说在前边:
编码问题一直困扰着每一个程序员的编程之路,如果不将它彻底搞清楚,那么你的的这条路一定会走的格外艰辛,尤其是针对使用python的程序员来说,这一问题更加显著,
因为python有两个版本,这两个版本编码格式却完全不同,但我们却经常需要兼顾这两个版本,所以出现各种问题的几率就大了很多。
所以在这里我试图用一篇文章来彻底梳理整个python语言的编码问题,尽量降低以后在这方面举到问题的可能性。
ps 此文一定程度上参考和引用了alex的博客:“https://www.cnblogs.com/alex3714/articles/7550940.html”
说编码,首先得知道什么是编码,为什么会有编码:
百度百科上的解释是:“编码是信息从一种形式转换为另一种形式的过程”,这其实是一个过程,而我们常说的“编码问题”,其实更多的是指“编码格式问题”。
常见的编码格式有:
ASCII 占一个字节,只支持英文
GB2312 占2个字节,支持6700多个汉字
GBK GB2312的升级版,支持的汉字更多(21000+汉字)
Shift-JIS 日本字符
因为计算机只识别二进制,每个字符想要被计算机识别,那么它就需要有字符和二进制之间的对应关系,而每个国家都有自己的字符,但是也仅包含本国字符,
导致本国软件、系统,到了国外就会乱码,从而为了解决这一问题,“万国码”(Unicode)出现了,它包含了全球所有文字和其二进制的对应关系。
Unicode 2-4字节,已经收录了136690+字符,且依旧在扩充。
它支持全球所有语言,每个国家都不用使用原先的本国编码,用Unicode就万事大吉。
Unicode解决了字符和二进制之间的对应关系,但是仍有一个问题没有解决,那就是空间问题,因为Unicode使用2-4个字节标识一个字符,二原先的ASCII码虽然只支持英文,
但是一个英文字母只占1个字节,原先 “Python” 用ASCII占6字节,现在用Unicode却要占12字节,在存储和网络传输过程中是很大的负担,所以推生出另一种编码出现:
"UTF" (Unicode Transformation Format),即对Unicode的转换,目的是存储和传输过程中节省空间。
UTF-8 : 使用 1、2、3、4个字节表示所有字符,优先使用1个字符,无法满足即增加一个字节,最多使用4字节:英文1字节,欧洲语系2字节,东亚3字节(中文),特殊字符4字节。
UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
UTF-32: 使用4个字节表示所有字符;
(UTF是为Unicode编码格式设计的一种在存储与运输时节省空间的编码方案)
整体编码背景说完,我们该来说说python的编码了:
由于最开始出现的时python2,所以我们从它开始说:
龟叔当初开发python时,估计没想到它会这儿的火,所以就将ASCII来当作了默认编码,所以python中的默认编码是ASCII.

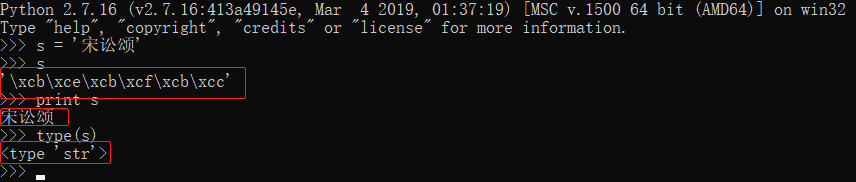
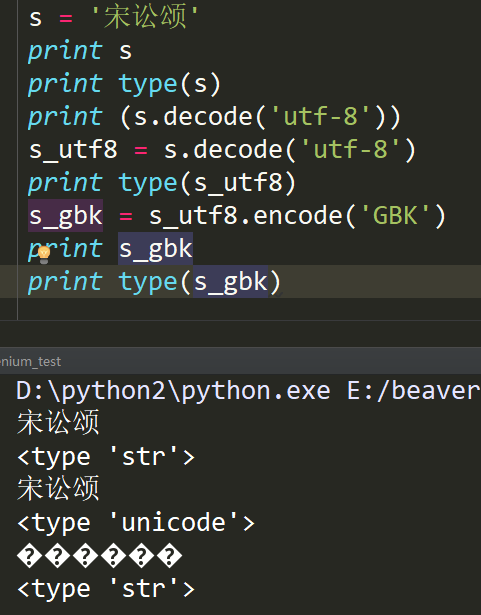
我们在python中输入 s = '宋讼颂'后,使用print来打印,确实是“宋讼颂”没错,但是当你直接调用s时,却出现的是一个个的16进制表示的二进制字节,我们将其称之为bytes类型(字节类型)
我们打印出它的类型,确是“str”,实际上在 python2中 bytes == str ,然后python2中还有一个单独的类型,就是unicode,将str解码后就变成了unicode,然后当你想从unicode编码转成gbk编码时,
只需要在对其进行编码,就ok,所以我们一定要记住,unicode是桥梁,任何两种编码想要相互转换,都需要decode('utf-8')将其先转为unicode,再经过encode()转换为想要的编码。
python3横空出世:
在2008年,python3横空出世,不兼容python2,字符串变成了unicode, 文件默认编码变为了utf-8,意味着只要用python3编写的代码,无论程序是以哪种编码开发的,任何电脑都可以显示。
这时的str和bytes已经不同了,str就是unicode格式的字符串,但是bytes就是单纯的二进制文件啦。
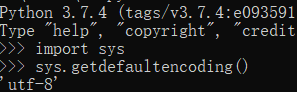

从这张图我们就可以看到,这时的字符串已经是unicode类型了,所以就不能decode()了。
而bytes已经仅仅表示二进制文件啦。