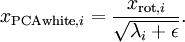The goal of whitening is to make the input less redundant; more formally, our desiderata are that our learning algorithms sees a training input where (i) the features are less correlated with each other, and (ii) the features all have the same variance.
example
How can we make our input features uncorrelated with each other? We had already done this when computing
. Repeating our previous figure, our plot for
was:
The covariance matrix of this data is given by:
It is no accident that the diagonal values are
and
. Further, the off-diagonal entries are zero; thus,
and
are uncorrelated, satisfying one of our desiderata for whitened data (that the features be less correlated).
To make each of our input features have unit variance, we can simply rescale each feature
by
. Concretely, we define our whitened data
as follows:
Plotting
, we get:
This data now has covariance equal to the identity matrix
. We say that

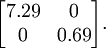
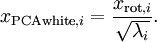

ZCA Whitening
Finally, it turns out that this way of getting the data to have covariance identity
is any orthogonal matrix, so that it satisfies
(less formally, if
will also have identity covariance. In ZCA whitening, we choose
. We define
Plotting
, we get:
It can be shown that out of all possible choices for
.
When using ZCA whitening (unlike PCA whitening), we usually keep all
dimensions of the data, and do not try to reduce its dimension.
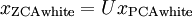

Regularizaton
When implementing PCA whitening or ZCA whitening in practice, sometimes some of the eigenvalues
will be numerically close to 0, and thus the scaling step where we divide by
would involve dividing by a value close to zero; this may cause the data to blow up (take on large values) or otherwise be numerically unstable. In practice, we therefore implement this scaling step using a small amount of regularization, and add a small constant
to the eigenvalues before taking their square root and inverse:
When
, a value of
might be typical.
For the case of images, adding
ZCA whitening is a form of pre-processing of the data that maps it from