1、索引
B+树
索引分类
1.普通索引index :加速查找
2.唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3.联合索引 -primary key(id,name):联合主键索引 -unique(id,name):联合唯一索引 -index(id,name):联合普通索引
4.全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
索引的最左匹配特性(即从左往右匹配)
联合索引比索引的组合效率要高得多
索引字段要尽量的小
- 避免使用select *
- count(1)或count(列) 代替 count(*)
- 创建表时尽量时 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(经常使用多个条件查询时)
- 尽量使用短索引 - 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致 - 索引散列值(重复少)不适合建索引,例:性别不适合
2、事务
- 原子性(Actomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以操持完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
3、锁机制
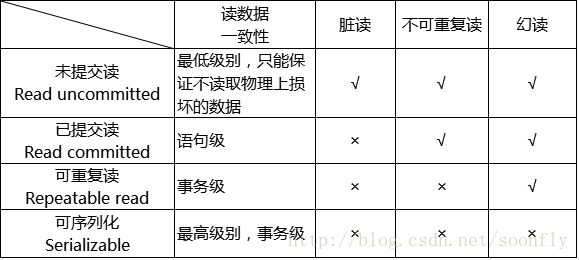
- 脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做“脏读”。
- 不可重复读(Non-Repeatable Reads):一个事务在读取某些数据已经发生了改变、或某些记录已经被删除了!这种现象叫做“不可重复读”。
- 幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
对于以上的问题,可以添加隔离级别解决
innodb行锁模式及枷锁方法
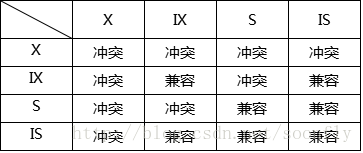
- 共享锁(s):又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
- 排他锁(X):又称写锁。允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
-
意向共享锁(IS):事务打算给数据行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
-
意向排他锁(IX):事务打算给数据行加排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
读未提交
读操作:不加锁 即产生脏读的原因。
写操作:行级共享锁 其他线程只能读 不能写。
读提交
读操作:行级共享锁 只有在读的时候加锁 读完就释放。
写操作:行级排它锁 在写操作的瞬间加锁 不允许其他事务做读写操作。
可重复读
读操作:行排他锁。
写操作:行级排它锁 在写操作的瞬间加锁 不允许其他事务做读写操作。
串行化
读操作:表级共享锁 只有在读的时候加锁 读完就释放。
写操作:表级排它锁 在写操作的瞬间加锁 不允许其他事务做读写操作。
以上为悲观锁的实现方式。
原因就是在没有索引的情况下,InnoDB只能使用表锁。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
总结:
- 尽量使用较低的隔离级别; 精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会;
- 选择合理的事务大小,小事务发生锁冲突的几率也更小;
- 给记录集显式加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁;
- 不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
- 尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响; 不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁;
- 对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。