1、FM (因子分解机)
2、FM的作用:
(1)特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接进行建模,很可能会忽略掉特征与特征之间的关联信息,因此,可以通过构建新的交叉特征这一特征组合方式提高模型的效果。
(2)高维的稀疏矩阵是实际工程过程中常见的问题,并直接回导致计算量过大,特征权值更新缓慢。试想一个10000*100的表,每一列都有8种元素,经过one-hot独热编码之后,会产生一个10000*800的表。因此表中每行元素只有100个值为1,700个值为0。
而FM的优势就在于这两方面问题的处理。首先是特征组合,通过对两两特征组合,引入交叉项特征,提高模型得分;其次是高维灾难,通过引入隐向量,(对参数矩阵进行矩阵分解),完成对特征的参数估计。
3、FM适应场景:
FM可以解决特征组合以及高维系数矩阵问题,而实际业务长江汇总,电商、豆瓣等推荐系统场景是使用最广的领域。
4、FM的样子:
首先,看一下线性表达式:
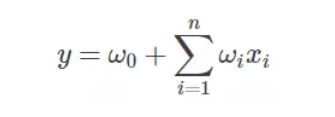
其中w0为初始权值,wi为每个特征xi对应的权值。可以看到,这种线性表达式值描述了每个特征与输出的关系。
FM表达式:(引入了交叉项)

5、FM交叉项的展开
5.1、寻找交叉项
FM表达式的求解核心在于对交叉项的求解。



5.3、交叉项展开式





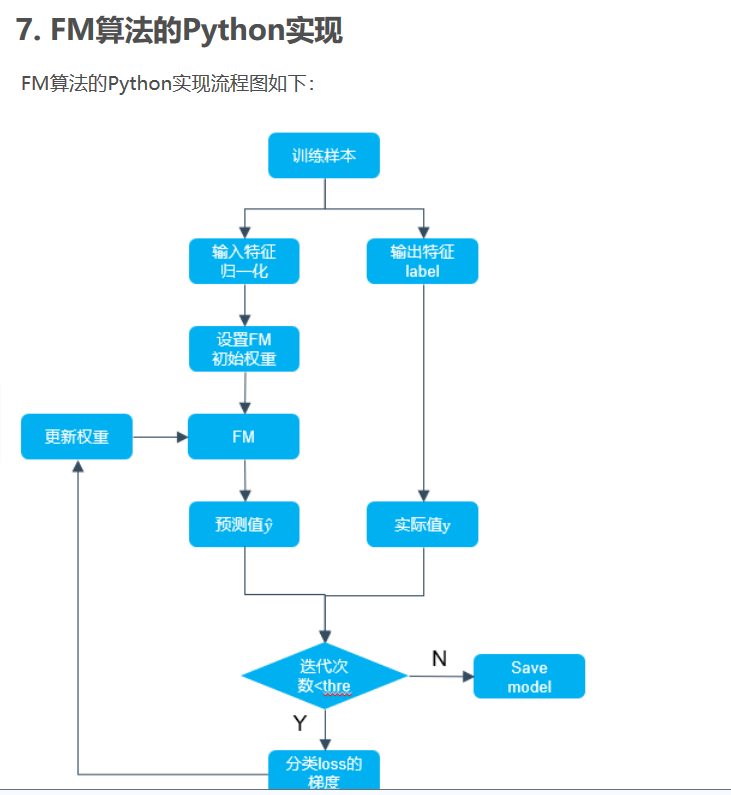

代码数据集的获取:https://pan.baidu.com/s/1TcCV55sgUbjmMVmipJUgSQ
from __future__ import division from math import exp import numpy as np from numpy import * from random import normalvariate from datetime import datetime import pandas as pd trainData = 'diabetes_train.txt' testData = 'diabetes_test.txt' def preprocessData(data): feature = np.array(data.iloc[:,:-1])#取特征,最后一列之前的列为特征列 label = data.iloc[:,-1].map(lambda x :1 if x==1 else -1)#取标签并转化为+1,-1 # 将数组按行进行归一化,按列axis=0取每一列的最大值和最小值 zmax,zmin = feature.max(axis=0),feature.min(axis = 0) feature = (feature -zmin )/(zmax-zmin) label = np.array(label) # print(type(feature),label) return feature,label def sigmoid(inx): return 1.0/(1+exp(-inx)) def SGD_FM(dataMatrix,classLabels,k,iter): ''' dataMatrix特征矩阵 classLabels类别矩阵 k辅助向量的大小 iter迭代次数 return ''' # dataMatrix用的是mat,classLabels是列表 m,n = shape(dataMatrix) #矩阵的行列数,即样本数和特征数 alpha = 0.01 #初始化参数 # w = random.randn(n,1) #n是特征的个数 w = zeros((n,1))#一阶特征的系数,初始为1 n行1列 # print (w) w_0 = 0. v = normalvariate(0,0.2)*ones((n,k)) #即生成辅助向量用来训练二阶交叉特征的系数 for it in range(iter): for x in range(m): inter_1 = dataMatrix[x] * v # *表示矩阵的点乘 inter_2 = multiply(dataMatrix[x],dataMatrix[x]) * multiply(v,v) interaction = sum(multiply(inter_1,inter_1) - inter_2) /2 p = w_0 + dataMatrix[x] *w + interaction loss = 1-sigmoid(classLabels[x]*p[0,0]) w_0 = w_0 + alpha * loss *classLabels[x] for i in range(n): if dataMatrix[x,i] !=0: w[i,0] = w[i,0] +alpha *loss *classLabels[x] *dataMatrix[x,i] for j in range(k): v[i,j] = v[i,j] + alpha *loss*classLabels[x] * (dataMatrix[x,i]*inter_1[0,j]-v[i,j]*dataMatrix[x,i]*dataMatrix[x,i]) print("第{}次迭代后的损失为{}".format(it,loss)) return w_0,w,v def getAccuracy(dataMatrix,classLables,w_0,w,v): m,n = shape(dataMatrix) allItem = 0 error = 0 result = [] for x in range(m): allItem +=1 inter_1 = dataMatrix[x] *v inter_2 = multiply(dataMatrix[x],dataMatrix[x])*multiply(v,v) interaction = sum(multiply(inter_1,inter_1)-inter_2)/2 p = w_0 + dataMatrix[x]*w +interaction pre = sigmoid(p[0,0]) result.append(pre) if pre < 0.5 and classLables[x] == 1.0: error +=1 elif pre >= 0.5 and classLables[x] == -1.0: error += 1 else: continue return float(error) / allItem if __name__ == '__main__': train = pd.read_csv(trainData) test = pd.read_csv(testData) dataTrain,labelTrain = preprocessData(train) dataTest,labelTest = preprocessData(test) date_startTrain = datetime.now() print("开始训练") w_0,w,v = SGD_FM(mat(dataTrain),labelTrain,20,60) print("训练准确率为:%f"%(1-getAccuracy(mat(dataTrain),labelTrain,w_0,w,v))) date_endTrain = datetime.now() print("训练用时为:%s"%(date_endTrain-date_startTrain)) print("开始测试") print("测试准确性为:%f"%(1-getAccuracy(mat(dataTest),labelTest,w_0,w,v)))
参考:https://blog.csdn.net/sun_wangdong/article/details/86505011