第2章 利用用户行为数据
接触推荐系统不久,看了推荐系统实践这本书,也结合博客大佬们的一些笔记,有不对的地方欢迎大家指出,希望可以和大家一起学习,一起进步!
目录:
-
2.1 用户行为数据简介
-
2.2 用户行为分析
-
2.3 实验设计和算法评测
-
2.4 基于领域算法
-
2.5 隐语义模型
-
2.6 基于图的模型
本章主要是利用用户的行为数据给用户进行推荐。“听其言,观其行”这句古话可以很好的应用到这一章中。
要想给用户体验比较好的推荐,我们必须了解用户的一些行为,要想很好得到用户的行为,就必须知道用户关于行为方面的数据。如:注册信息方面,个性描述,好友的行为及自己的历史行为。为了更好的学习用户行为数据进行推荐,下面就开始我们的讲解吧!
2.1 用户行为数据简介
这一节这要有几个知识点需要了解:显性反馈行为、隐性反馈行为、显性反馈数据和隐性反馈数据的比较、正反馈和负反馈及如何描述用户的行为。
-
显性反馈行为包括用户明确表示对物品喜好的行为,主要是可以通过这个行为体现用户对物品是喜欢、不喜欢;如:给物品评分很高表示喜欢,评分较低表示不喜欢。
-
隐性反馈行为指的是那些不能明确反应用户喜好的行为,最具代表性的隐性反馈行为就是页面浏览行为,因为浏览网页我们无法判断用户是否的喜好。
- 显性反馈数据进和隐性反馈数据的比较:

-
按照反馈的方向分,又可以分为正反馈和负反馈。正反馈指用户的行为倾向于指用户喜欢该物品,而负反馈指用户的行为倾向于指用户不喜欢该物品。
- 用户行为的描述:

2.2 用户行为分析
用户行为分析,主要是用户、物品两个方面来进行分析。
本节主要知识点:长尾分布、用户活跃度和物品流行度的概念理解及其关系。
很多关于互联网数据的研究发现,互联网上很多数据分布是满足一种成称为Power Law的分布,这个分布在互联网领域也成为长尾分布。
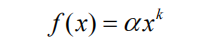
很多研究人员发现,用户行为数据也蕴含着这种规律。令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数。那么,fu(k)和fi(k)都满足长尾分布。也就是说:
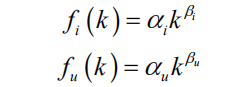

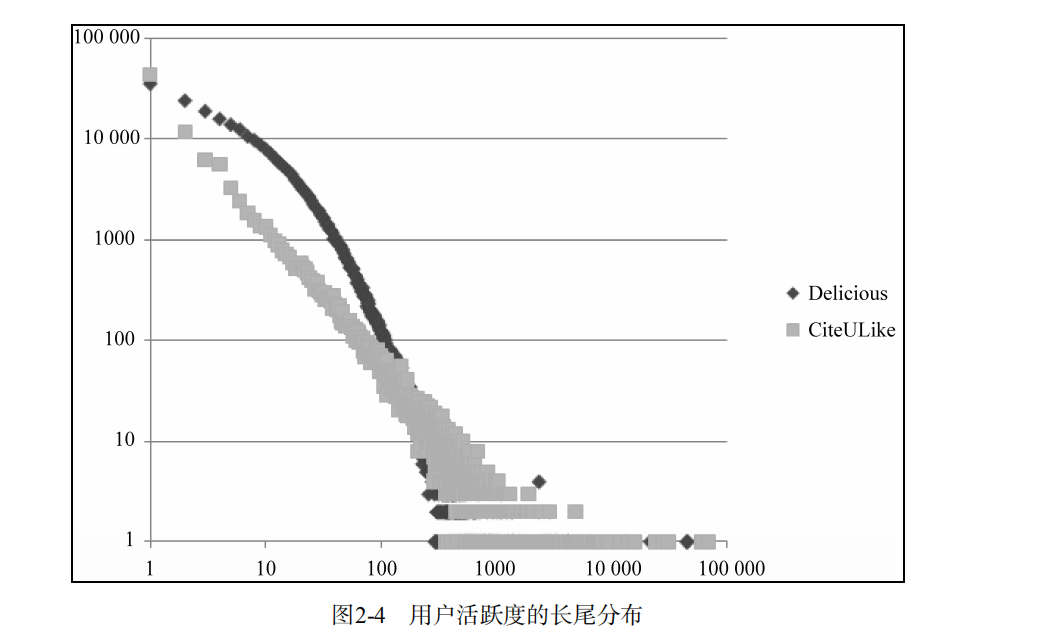
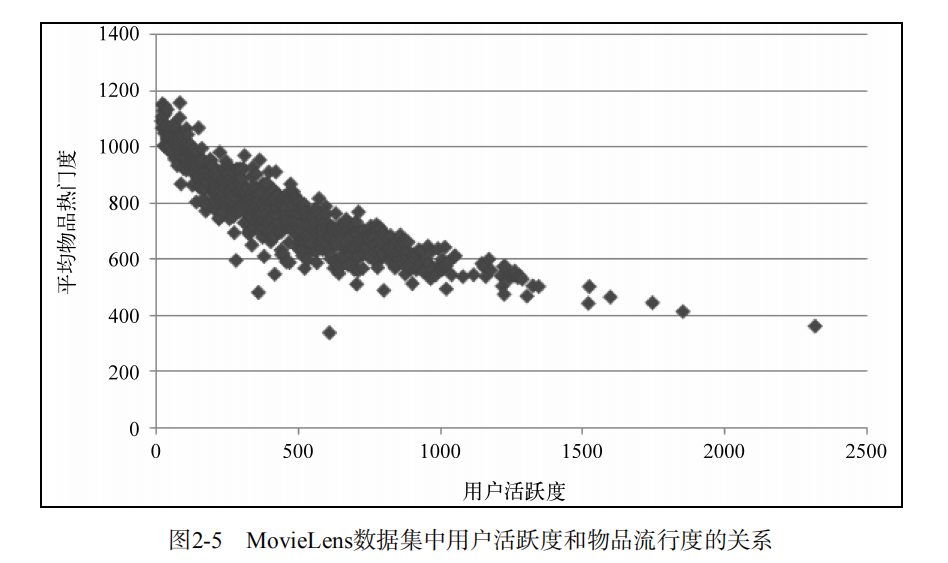
用户活跃度与物品流行度的关系:一般认为,新用户倾向于浏览热门的物品,因为他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。
2.3 实验设计和算法测评
本节主要知识点:准确率、召回率和覆盖率


召回率描述有多少比例的用户—物品评分记录包含在最终的推荐列表中,而准确率描述最终的推荐列表中有多少比例是发生过的用户—物品评分记录。
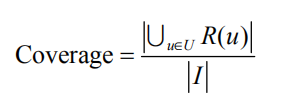
2.4 基于邻域的算法
本节主要知识点:基于用户的协同过滤算法和基于物品的协同过滤算法
2.4.1 基于用户的协同过滤算法
步骤:
-
找到和目标用户兴趣相似的用户集合。
-
找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
相似度的计算:
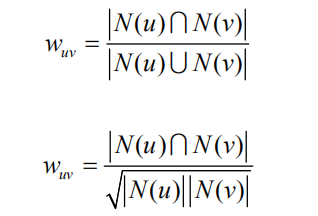
例如:

为了降低复杂度,采取物品到用户的倒排表:
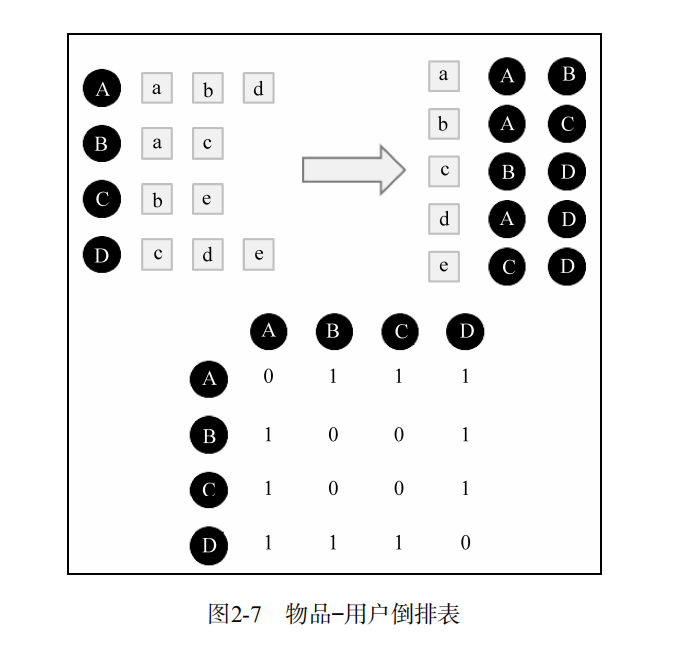
此时,相似度的计算:
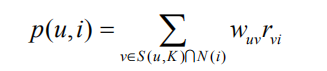
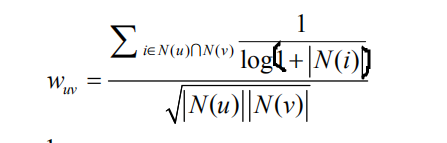
主要是惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
2.4.2 基于物品的协同过滤算法
-
计算物品之间的相似度。
-
根据物品的相似度和用户的历史行为给用户生成推荐列表。
相似度的计算:
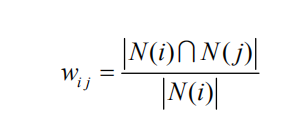

在得到物品之间的相似度后,ItemCF通过如下公式计算用户u对一个物品j的兴趣:
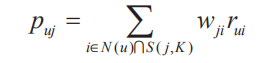
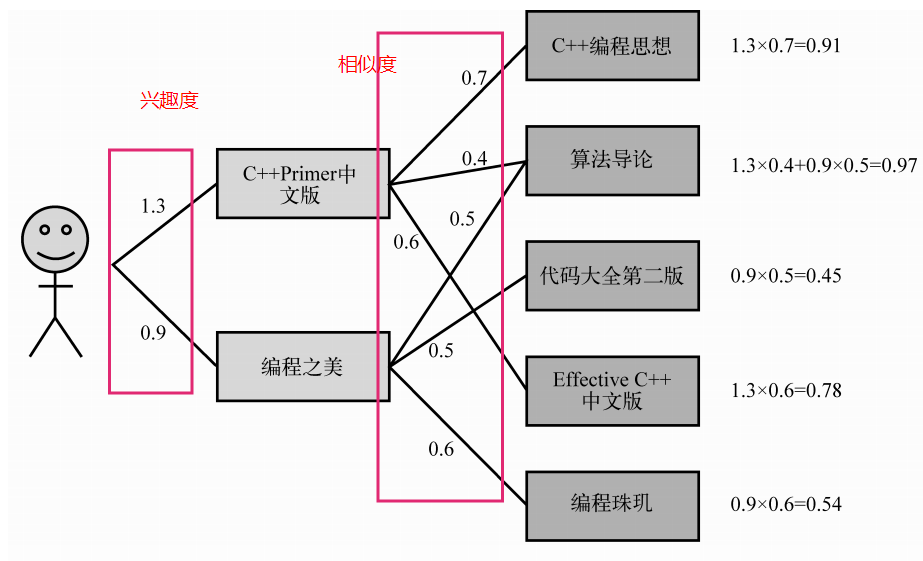
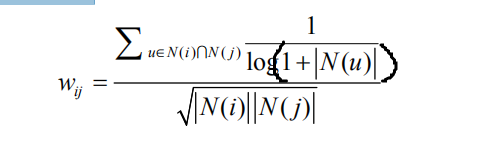
2.4.3 UserCF和ItemCF的综合比较

2.5 隐语义模型
主要知识点:理解隐语义模型(核心思想是通过隐含特征联系用户兴趣和物品)。以LFM为例介绍隐含语义分析技术在推荐系统中的应用。
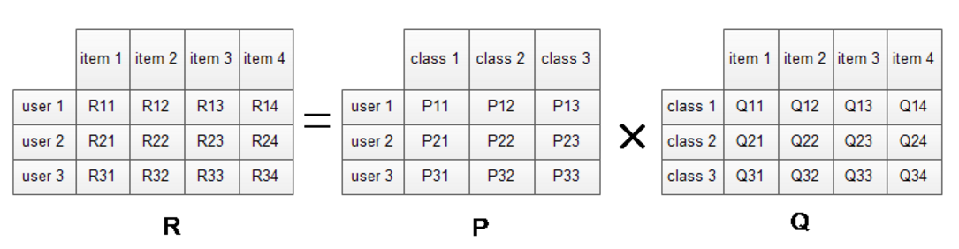
R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。
LFM计算用户U对物品I的兴趣度:
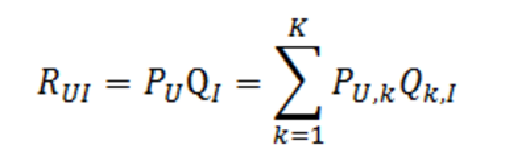
我们不需要关心分类的角度,结果都是基于用户行为统计自动聚类的,全凭数据自己说了算; 不需要关心分类粒度的问题,通过设置LFM的最终分类数就可控制粒度,分类数越大,粒度约细; 对于一个item,并不是明确的划分到某一类,而是计算其属于每一类的概率,是一种标准的软分类; 对于一个user,我们可以得到他对于每一类的兴趣度,而不是只关心可见列表中的那几个类; 对于每一个class,我们可以得到类中每个item的权重,越能代表这个类的item,权重越高;
那么,如何计算矩阵P和矩阵Q中参数值。一般做法就是最优化损失函数来求参数。在定义损失函数之前,我们需要准备一下数据集并对兴趣度的取值做一说明。
数据集应该包含所有的user和他们有过行为的(也就是喜欢)的item。所有的这些item构成了一个item全集。对于每个user来说,我们把他有过行为的item称为正样本,规定兴趣度RUI=1,此外我们还需要从item全集中随机抽样,选取与正样本数量相当的样本作为负样本,规定兴趣度为RUI=0。因此,兴趣的取值范围为[0,1]。
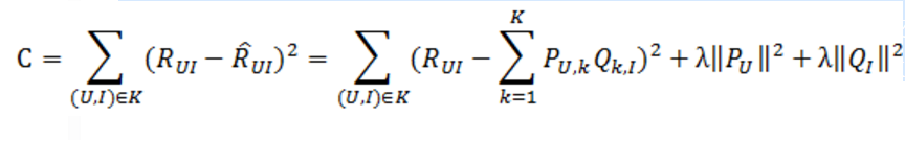
损失函数的优化使用随机梯度下降算法:
1、通过求参数PUK和QKI的偏导确定最快的下降方向:
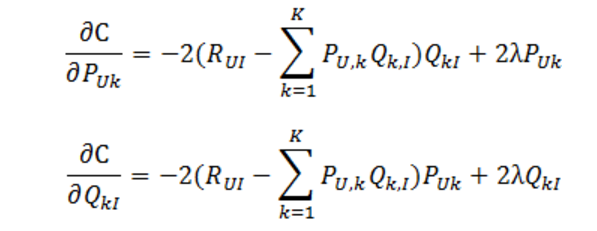
2、迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛
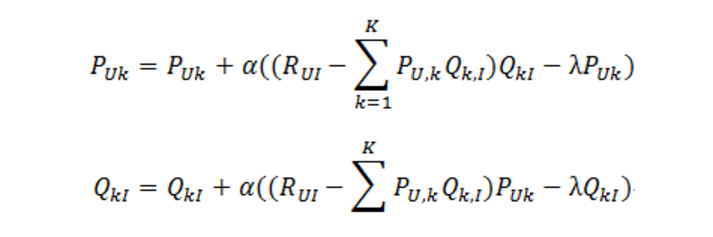
LFM和基于邻域的方法的比较:
1、理论基础: LFM具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
2、离线计算的空间复杂度: 基于邻域的方法需要维护一张离线的相关表。在离线计算相关表的过程中,如果用户/物品数很多,将会占据很大的内存。而LFM在建模过程中,如果是F个隐类,那么它需要的存储空间是O(F*(M+N)),这在M和N很大时可以很好地节省离线计算的内存。
3、离线计算的时间复杂度: 在一般情况下,LFM的时间复杂度要稍微高于UserCF和ItemCF,这主要是因为该算法需要多次迭代。但总体上,这两种算法在时间复杂度上没有质的差别。
4、在线实时推荐: UserCF和ItemCF在线服务算法需要将相关表缓存在内存中,然后可以在线进行实时的预测。LFM在生成一用户推荐列表时速度太慢,因此不能在线实时计算,而需要离线将所有用户的推荐结果事先计算好存储在数据库中。
5、推荐解释: ItemCF算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。但LFM无法提供这样的解释,它计算出的隐类虽然在语义上确实代表了一类兴趣和物品,却很难用自然语言描述并生成解释展现给用户。
2.6 基于图的模型
本节主要利用二分图进行建模。
二分图就是在一个图中,将顶点集分成A和B,在这个图中,所有边的两个顶点都分别在顶点集A和B上,顶点集A中的顶点不会连向顶点集A中的顶点,顶点B中顶点不会连向顶点集B中的顶点。
如果将个性化推荐算法放到二分图模型上,那么给用户u推荐物品的任务就可以转化为度量用户顶点vu和vu没有边直接相连的物品节点在图上的相关性,相关性越高的物品在推荐列表中的权重就越高。
度量图中两个顶点之间相关性的方法很多,但一般来说图中顶点的相关性主要取决于下面3个因素:
- 两个顶点之间的路径数;
- 两个顶点之间路径的长度;
- 两个顶点之间的路径经过的顶点。
而相关性高的一对顶点一般具有如下特征:
- 两个顶点之间有很多路径相连;
- 连接两个顶点之间的路径长度都比较短;
- 连接两个顶点之间的路径不会经过出度比较大的顶点。
在介绍该算法之前,我们先介绍另外一个算法——pageRank算法,这个一个用来衡量搜索引擎中特定网页相对于其他网页重要性的算法,使用这个算法作为搜索结果网页排名相当重要的一部分。
它的基本思想是,假设网页之前通过超链接相互连接,互联网上的所有网页便构成了一张图。用户随机的打开一个网页,并通过超链接跳转到另一个网页。每当用户到达一个网页,他都有两种选择,停留在当前网页或者通过继续访问其他网页。如果用户继续访问网页的概率为d,那么用户停留在当前网页的概率便是1-d。如果用户继续访问其他网页,则会以均匀分布的方式随机访问当前网页指向的另一网页,这是一个随机游走的过程。当用户多次访问网页后,每一个网页被访问到的概率便会收敛到某个值,而计算出来的结果便可以用于网页排名。
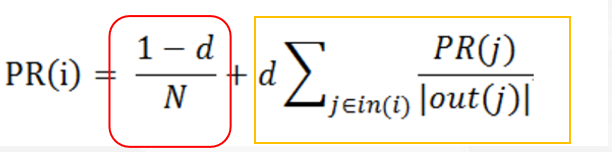
其中PR(i)是网页i被访问到的概率,d代表用户继续访问网页的概率,N为所有网页的数量,in(i)代表所有指向网页i的网页集合,out(j)代表网页j指向的其他网页集合。
红框部分表示网页i作为起点,第一个被用户点击后停留在当前页面的概率;
黄框部分表示用户点击其他网页后(无论网页i是不是起点),再次跳转回到网页i的概率。
PersonalRank算法是基于pageRank算法进行了一些变化,在pageRank算法中,计算出来的是每一个顶点相对其他顶点的相关性,代入到我们的用户物品二分图中,这显然不是我们想要的,我们需要的是所有物品相对于特定某个用户的相关性,有公式如下:
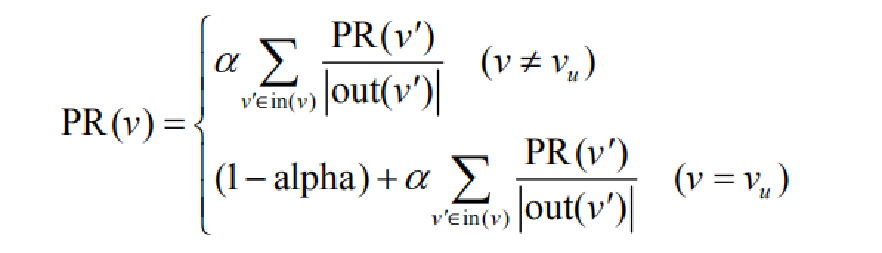
两种算法的区别:PersonalRank算法每次都是从目标用户节点出发,进行随机游走,而不同于pageRank的起点是随机从所有网页中进行选择,personalRank算法得出的结果便是所有顶点相对于目标用户结点的相关性。
这一张也算总结好了,可能结构排版不是很好,以后继续努力!有错误的地方请指出来,我们一起学习!
2019-07-12
参考文献:
《推荐系统实践》 项亮
