一、解决什么样的问题?
现有的基于contrastive learning的方法都有一个implicit semantic consistency(SC) assumption: a training image should have consistent semantic meaning across views。
问题是,有些数据集不满足SC assumption,本文的目的就是to explore alternative pretext tasks which do not rely on the SC assumption

二、提出了什么方法解决问题?
提出了 contrastive mask prediction(CMP)for visual representation learning and design a mask contrast(MaskCo) framework to address.
Idea: We make the task contrastive so that the extracted features
can focus on high-level semantic meanings instead of pixellevel details.
提出了两个问题:
1. 对比哪些的特征?(对比region-level 的features)
First, we propose to use region-level features instead of view-level features to compute contrastive loss。
2.如何在masked and unmasked 的特征之间建立bridge?(如何消除两者之间的gap?)
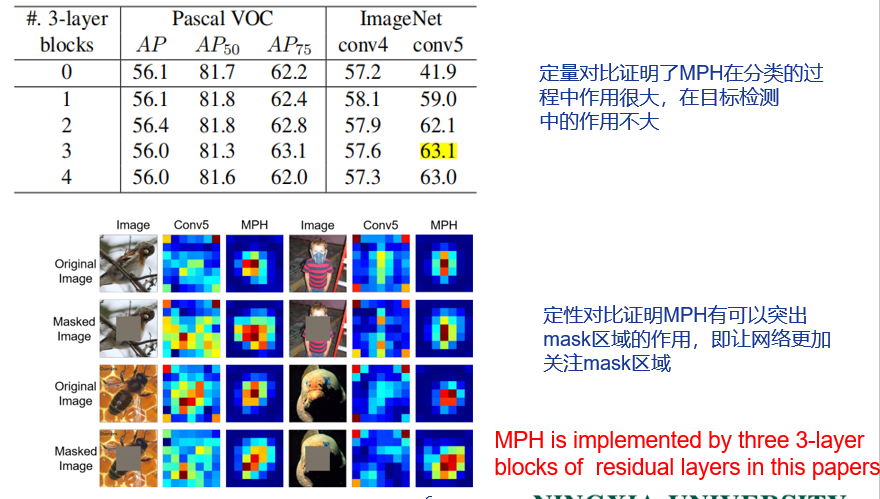
提出了MPH,来解决上述问题,Experients部分定性和定量证明了MPH的有效性。
框架图:

怎么选择masked region?
两个crop的views要有overlap, masked region就是从overlap中进行选择的。
The constraint here is that the two views should have a sufficiently large overlap. Then, a masked region is identified within the overlap of the two views. In the query view, the selected region is masked to zero.
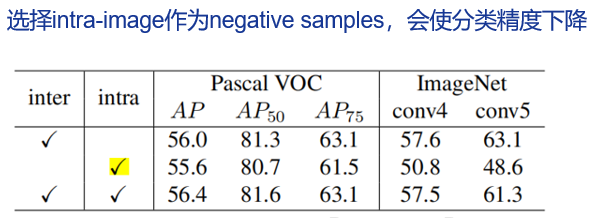
怎么选择negative sample(negative key boxes)?

选择intra-image negatives,为了提升pre-trained representation的定位能力,因为intra-image
negatives 是harder samples,网络很难区分。【增加intra-image negatives图片分类的精度会降低,主要原因是网络搞不清与positive sample的差异有多大,才能可以被归为negative sample】
选择inter-image negatives, 因为仅仅使用intra-image negatives 缺乏表征的多样性。使用inter-image negatives目的是为了增加representation的多样性。
本文选择了少量的intra-image negatives和大量的inter-image negatives相结合的方法
Region-level contrast is the key to release the SC assumption used in ID tasks. (Why?)
预测masked region的特征,我们从unmasked view获得相同region的representation作为正样本,不依赖于任何假设。
This is because, for the predicted feature of the masked region, the representation of the same region drawn from an unmasked view is an indisputable positive sample that does not depend on any hypothesis.

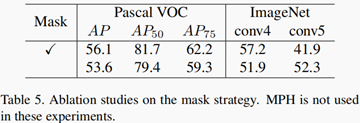
Mask的作用?
如果没有mask相当于传统的CL去掉random cropping。那样学习表征的任务变得非常简单,可能不能学到有意义的表征。文章中实验表明,在加上mask之后学到的特征用在分类和object detection的效果都比没有mask的好。
Mask Prediction Head(MPH)的作用?
上面有讲:如何在masked and unmasked 的特征之间建立bridge?(如何消除两者之间的gap?)
论文的优点
1. Overlap保证两幅图有相关语义。增加了mask region,从而增加了学表达的难度,从而学到更好的representations
2. 基于region-level contrast ,从对应的unmasked image中选择negative samples可以让网络学到更细粒度的representations.【与传统的对比学习比,本文相当于local patch 之间的对比】
论文的不足(论文本身有提到)
与传统的contrastive learning的区别是?
l 提取的特征是基于region-level的不是view-level
l 传统的contrastive learning中negative samples 的选取仅可以来自与anchor没有语义信息的样本,本文中negative samples的选取可以与positive sample 来自同一张图片。(本文中的negative sample是从Key中crop出来的box)