1. 不使用pixel-wise而使用比较简单的弱监督信息(如scribbles/bounding boxes/ points/ image-level labels[只告诉训练器,图片中有什么物体])称为弱监督
使用pixel-wise的是全监督。
一篇论文的思想:训练时用弱监督,测试的时候仍用全监督 。 Saliency maps:显著图
2. face parsing的任务是:给一张图片,把人脸的不同区域用不同的颜色表示出
笔记2020/9/11
GAP把特征图转化成特征向量,每一层特征图用一个值表示,如果这个特征图的深度(channel)是512,那么这个特征向量的长度就是512。
GAP作用:能保留空间信息,并且定位。
在论文《Learning Deep Features for Discriminative Localization 》发现
CAM是一个帮助我们可视化CNN的工具。使用CAM,我们可以清楚的观察到,网络关注图片的哪块区域。
因为CAM基于分类,所以被激活的区域是根据分类决定的,即同一个特征图,只更新不同的权重
CAM网络的工作是分类,思想是:对于某一类object来说,它想知道这一类类别的信息和这个图像中的哪些部分的特征是有关联关系的。所以狗的头部被高亮,则通过狗的头部特征把狗分为一类【CAM关注物体的显著部分,通过显著部分来进行object的分类】
来自 <https://www.cnblogs.com/luofeel/p/10400954.html>
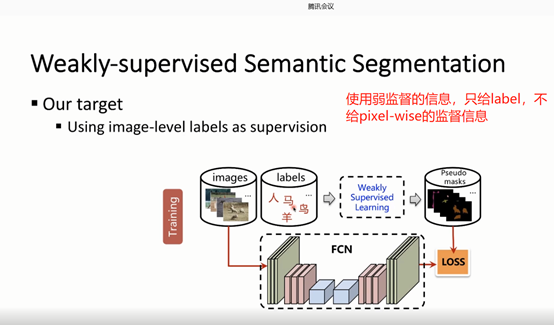
弱监督语义分割:在训练的时候在使用弱监督的信息作为监督信息,训练得到的分割图作为测试阶段的监督信息(在测试阶段用全监督)。这样的深度学习网络称为弱监督语义分割网络
弱监

任意的深度学习网络,做弱监督训练。
在training Stage我们使用弱监督的信息作为监督信息(这里给的是语义labels)然后进行弱监督学习得到大概的分割图(简称Pseudo masks)。此时得到的Pseudo masks肯定比手工标注的分割图的精度差,但是我们可以使用Weakly Supervised Learning学习到一个很逼近的Pseudo mask。然我们用Pseudo masks作为近似的全监督信息,用于testing Stage。Pseudo masks精度越高对后面的test dataset训练越好
主要问题是:如何从已知的训练样本(images和labels)中推断出精确的Pseudo masks【即怎么得到Pseudo masks是一个关键的问题】