CVPR 2020
Motivation
1. 以前的分割网络都是只关注像素级别的预测,忽略了像素分组。但本文认为语义分割可以分为explicit pixel-wise prediction and implicit pixel grouping. 。为了解决像素分组的问题,论文引入了SA model,并且其结果还可以更好的指导像素的预测
2. 受Squeeze-and-Excitation Networks【SENet】的启发,该文中SANet扩展SENet并引入了channel attention通过通道之间的相关性把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
SANet与SENet的不同之处:
(1)SA模块的注意通道采用平均池化的方法下采样本特征图,得到的是attention convolution channel,然后再上采样到主干网络中,【上采样的目的是为了和RESNet有相同的维度】
(2)SE model不能保持spatial information,而SA model以扩张的FCN作为主干网络,增加了spatial features来进行pixel level prediction【SA保留了spatial information】
Pixel-group
- Pixel grouping: 强调像素之间的联系
- 我们引入了像素分组的第二个子任务,直接鼓励属于同一类的像素被分组在一起,而不受空间限制
Model
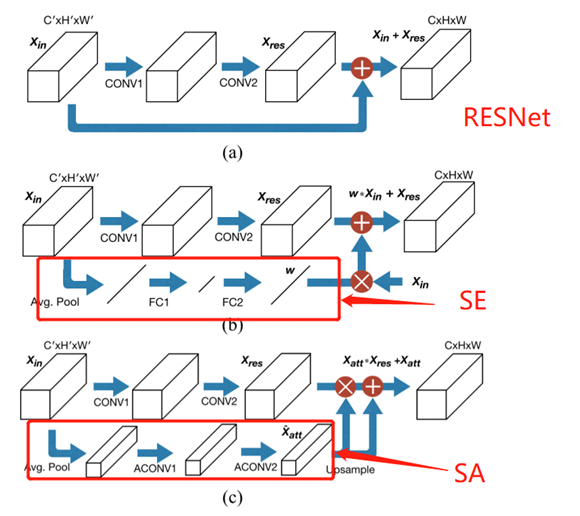




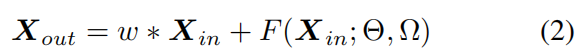

w(欧米伽)用于重新标定输入的feature map通道的学习权重。【怎么重新标定的呢?见下图】
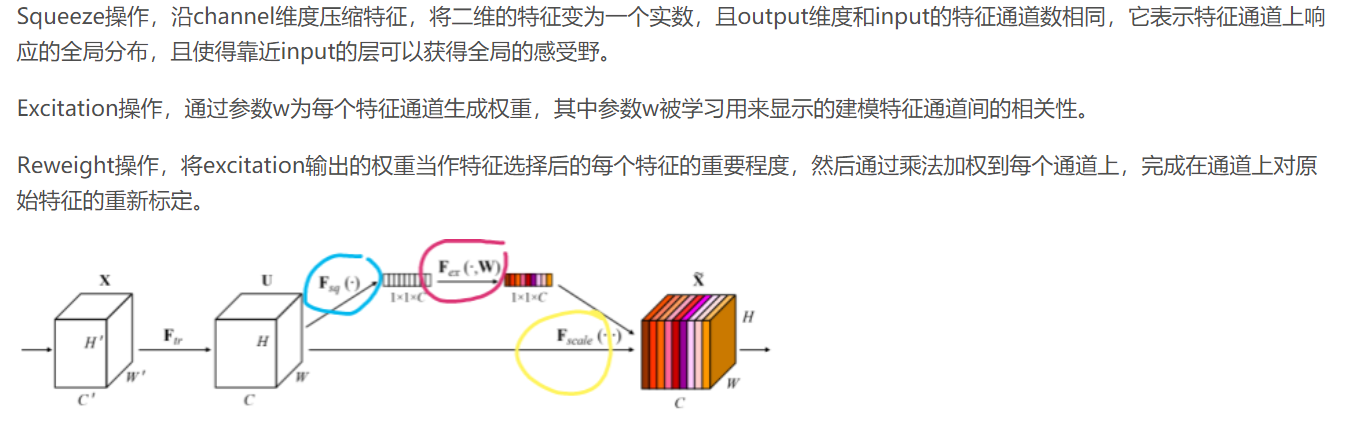
备注:1、蓝色-Squeeze操作,Global average pooling用来计算channel-wise的统计量;粉色-Excitation操作;黄色-Reweight操作;
图片来源于:https://blog.csdn.net/Z199448Y/article/details/88866965


SANet:
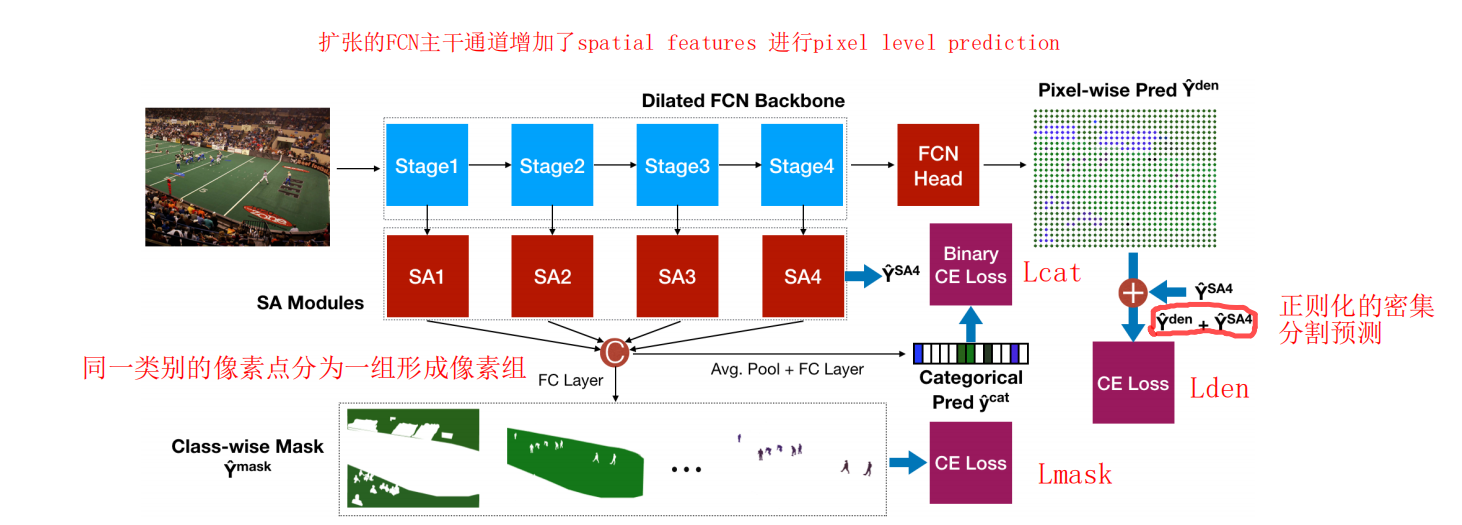
LOSS Function:

可以看到作者语义分割网络一共三个损失,其中Lmask 和Lden计算每个像素的分类损失并求平均,也就是经典的语义分割损失。而Lcat计算的是图像多标签二分类的分类损失
Questions:
1. 论文作者没有提到用Sigmoid或Softmax计算注意力,而是直接用卷积结果作为注意力
2.grouping在哪里体现? 感觉本质上还是per-pixel classification,只是从softmax变成了每类的二分类。