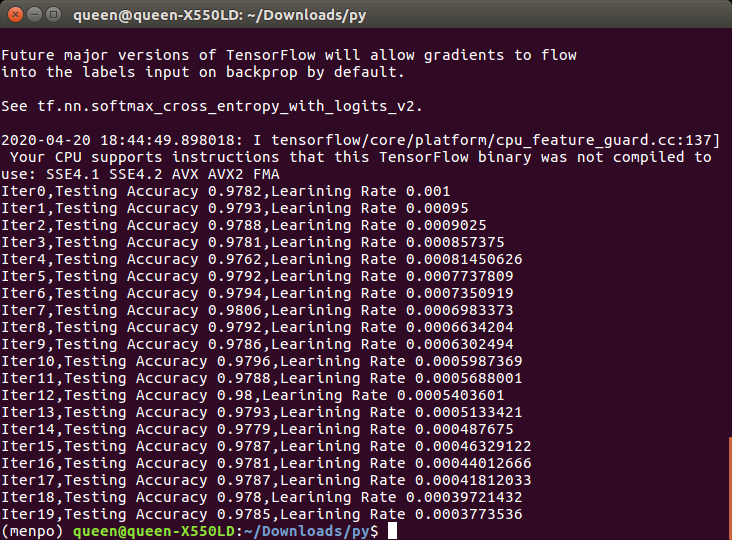
tensorflow中的优化器有很多种,也有很多类似的博客,当然最常用的是AdamOptimizer,我们这里就通过adma和衰减的学习率加上之前学的多层结构,使手写数字模型准确率达到98%以上
以下代码优化地方为:
1.增加2个隐藏层
2. 把权值用了一个截断的正态分布初始化
3. 使用交叉熵代价函数(softmax)
4. 更换优化器为AdamOptimizer并将初始学习率改为0.001


# -*- coding: UTF-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #载入数据集 mnist=input_data.read_data_sets("MNIST_data", one_hot=True) #每个批次的大小 batch_size=100 #计算一共有多少个批次 n_batch=mnist.train.num_examples #定义两个placeholder x=tf.placeholder(tf.float32,[None,784]) y=tf.placeholder(tf.float32,[None,10]) keep_prob=tf.placeholder(tf.float32) lr = tf.Variable(0.001,dtype=tf.float32) #增加一个学习率的变量,初始学习率为0.01 #创建一个简单的神经网络,设置2个隐藏层(第一个隐藏层为200个神经元,第二个隐藏层为100个神经元) W1=tf.Variable(tf.truncated_normal([784,200],stddev=0.1))#这里我们使用了一个截断的正态分布初始化W1,效果比divided.py初始化效果好 b1=tf.Variable(tf.zeros([200])+0.1) L1=tf.nn.tanh(tf.matmul(x,W1)+b1)#定义L1的输出(L1为当前层神经元的输出) L1_drop=tf.nn.dropout(L1,keep_prob)#keep_prob:设置有百分之多少个神经元是工作的 W2=tf.Variable(tf.truncated_normal([200,100],stddev=0.1))#这里我们使用了一个截断的正态分布初始化W2,标准差为0.1 b2=tf.Variable(tf.zeros([100])+0.1) L2=tf.nn.tanh(tf.matmul(L1_drop,W2)+b2) L2_drop=tf.nn.dropout(L2,keep_prob)#keep_prob:设置有百分之多少个神经元是工作的 #设置输出层神经网络 W3=tf.Variable(tf.truncated_normal([100,10],stddev=0.1)) b3=tf.Variable(tf.zeros([10])+0.1) prediction=tf.nn.softmax(tf.matmul(L2_drop,W3)+b3) #二次代价函数 #loss=tf.reduce_mean(tf.square(y-prediction)) #使用交叉熵代价函数 loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction)) #使用梯度下降法 #train_step=tf.train.GradientDescentOptimizer(0.2).minimize(loss)#优化方式可以改AdamOptimizer #优化方式可以改AdamOptimizer train_step=tf.train.AdamOptimizer(lr).minimize(loss)#学习率为0.0001 #初始化变量 init=tf.global_variables_initializer() #结果存放在一个布尔型列表中 correct_prediction=tf.equal(tf.argmax(y,1), tf.argmax(prediction,1)) #求准确率 accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session() as sess: sess.run(init) for epoch in range(20):#迭代次数越多越准确(但太多我的cpu扛不住) sess.run(tf.assign(lr,0.001*(0.95**epoch))) for batch in range(n_batch): batch_xs,batch_ys=mnist.train.next_batch(batch_size) sess.run(train_step,feed_dict={x:batch_xs, y:batch_ys, keep_prob:0.7})#keep_prob:0.7}神经元只用到了70% learning_rate = sess.run(lr) acc=sess.run(accuracy,feed_dict={x:mnist.test.images, y:mnist.test.labels,keep_prob:1.0}) print("Iter"+str(epoch)+",Testing Accuracy "+str(acc)+",Learining Rate "+str(learning_rate))
运行结果:(把迭代次数增加到50则能达到98%以上的分准确率,因为我电脑太老,只迭代到了20次)