TensorFlow安装及实例-(Ubuntu16.04.1 & Anaconda3)
Python-pip 和python-dev
Pip是python的默认包管理器,直接用pip安装TensorFlow,安装这两个包
命令:apt-get install python-pip python-dev python-virtualenv
可以virtualenv 创建一个隔离的容器, 来安装 TensorFlow. 这是可选的,这样做能使排查安装问题变得更容易。
安装Anaconda3
命令:bash Anaconda3-4.3.1-Linux-x86_64.sh
Anaconda3是python的一个科学计算发行版,内置了数百个Python经常会使用到的库,也包括许多机器学习和数据挖掘的库,容易Scikit-learn、NumPy、SciPy和Pandas等,另外还有一些TensorFlow的依赖库,推荐安装这个版本的python。
Ubuntu(32位)安装tensorflow报错
export TF_BINARY_URL = https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.0rc0-cp35-cp35m-linux_x86_64.whl
pip install --upgrade $ TF_BINARY_URL
Tensorflow 不支持32位,只支持64位。这太坑爹,本人的电脑性能不行,一直用的是Virtualbox或是Vmware运行的32位Ubuntu(12.04),刚开始还以为是Ubuntu版本太低,一直升级到Ubuntu16,发现还是不行,最后再查才发现TensorFlow只支持64位。
这绝对是一个大坑,谨慎勿入!
以下是报错:
tensorflow-1.0.0rc0-cp35-cp35m-linux_x86_64.whl is not a supported wheel on this platform
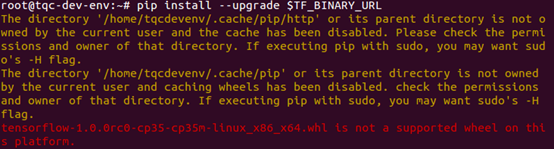
出现此错误后,查看Ubuntu系统是32位的还是64位的:
命令: uname –m

提示i686则代表系统是32位版本的。
Virtualbox安装64位Ubuntu
Win7 上Vitualbox虚拟机默认是不支持安装64为虚拟机系统的,如下所示,只能选择择32位的安装:

这是因为PC的主板BIOS默认不开启用主板虚拟化技术(Virtualization)。要运行一些操作系统,虚拟化软件和虚拟机,硬件虚拟化就需要启用。大多数情况下,不需要虚拟化技术的操作系统可以正常运行在启用了虚拟化技术的系统,但有些需要这种技术的操作系统,必须启用虚拟化技术才能运行。
所有最新的处理器和主板都支持虚拟化技术,检查一下你的主板厂商是否支持并且要知道如何启用或禁用BIOS中的VT。当在主板上启用虚拟化技术后,操作系统能立即检测到。
启用主板虚拟化技术 ,联想电脑(本人的)重启系统按F2进入BIOS, 进入BIOS后 :
高级->CPU菜单-> inter(CR) Virtualization
选择enable,然后按F10保存,重启电脑后可以VirtualBox就有64位系统的选项了,然后在Ubuntu官网下载最新的64位的操作系统镜像ubuntu-16.04.2-desktop-amd64.iso
http://cn.ubuntu.com/download/
安装ubuntu虚拟机就简单了,这里就不详细说了。
VirtualBox 共享文件夹
在宿主机(Windows)和虚拟机(Ubuntu)之间共享文件的重要性就不多说了,这里简单介绍如何设置共享文件夹。
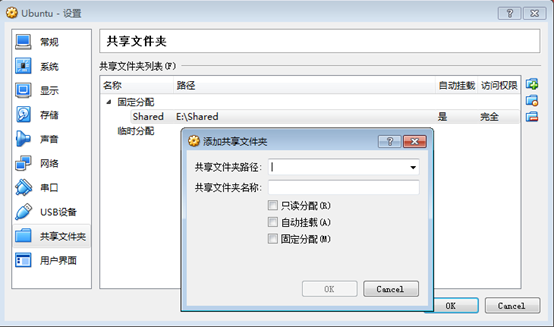
在Windows任意盘符下建立一个共享的文件夹如E:Shared,然后在Ubuntu系统中设置挂载点,挂载点目录添加"Shared"目录,接着执行"mount -t vboxsf Shared /mnt/share/",就能完成共享文件夹的设置。
重启Ubuntu系统进入/media 目录即可即看见sf_Shared目录,也就是Windows的Shared共享目录,如下:
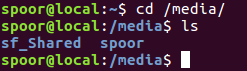
这样就可以方便的在Windows和Ubuntu虚拟机之间共享文件了。
设置自动挂载:
即etc/fstab中添加一项
Shared /mnt/share vboxsf rw,gid=110,uid=1100,auto 0 0
安装正确Anaconda3版本
在64位Ubuntu上Anaconda3必须安装64位的Anaconda3即Anaconda3-4.3.1-Linux-x86_64.sh,如果不小心下载了32位的版本Anaconda3-4.3.1-Linux-x86.sh,在Ubuntu(64位)安装:
命令:bash Anaconda3-4.3.1-Linux-x86.sh
会报以下错误: cannot execute native linux-32 binary, output from 'uname –a ' is

正确的是安装64位的Anaconda3,即:
命令:bash Anaconda3-4.3.1-Linux-x86_64.sh
报错tensorflow-1.0.0rc0-cp35-cp35m-linux_x86_64.whl is not a supported wheel on this platform
Ubuntu版本对了,在安装tensorflow的时候仍然报错:

说是pip版本低,于是按照提示执行: pip install –upgrade pip, 然后再次安装tensorflow,仍然报以下错误,

于是通过命令python –version 查看当前安装的Anaconda3的python版本,是Python 3.6.0

而我们要安装的tensorflow是基于python 3.5的,这个可以通过命令安装命令:pip install –upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.0rc0-cp35-cp35m-linux_x86_x64.whl
可以看出,cp3、cp35m就是代表的python的版本是3.5的,和我们之前安装的Anaconda3的python版本3.6.0不匹配,所以果断修改tensorflow安装命令为:
pip install –upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.0rc0-cp36-cp36m-linux_x86_x64.whl
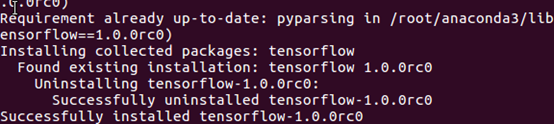
下图可以看到tensorflow就正确安装了!
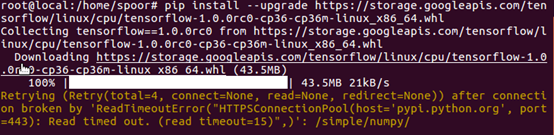
看大下面的提示就说明已经正确安装tensorflow-1.0.0rc0:
TensorFlow实例
下面讲解通过一个实例讲解TensorFlow的用法,以及如何通过它的训练得到优化后的参数的。这个例子中y_data 为实际的输出,其中x_data 为原始的训练输入数据,它的权重为0.1,偏置为0.3,也就是一条线性的直线,y为训练模型的预测值,tensorflow训练要达到目的就是使得y和y_data也就是预测值和实际值的均方差loss最小,经过以系列训练过后,如果训练得到的Weights权重,和biases偏置逼近了0.1和0.3则就说明训练达到了好的效果。
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
import tensorflow as tf
import numpy as np #科学计算的模块
# create data
x_data = np.random.rand(100).astype(np.float32) #生成100个随机数列,数据类型是float32,tf中大多数都用的是float32
y_data = x_data*0.1 + 0.3 #0.1为权重,0.3为偏置
### create tensorflow structure start ###
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#用Variable初始化Weights权重变量-随机数列生成-1到1的1维数据,
biases = tf.Variable(tf.zeros([1])) #偏置初始化为0,
y = Weights*x_data + biases #所要预测的y,通过训练使得y逼近真实的y_data,优化得到的参数变量就即Weights和biases
loss = tf.reduce_mean(tf.square(y-y_data)) #预测的y和实际的y_data的差别,即均方差
optimizer = tf.train.GradientDescentOptimizer(0.5) #用tf的梯度下降优化器减少误差loss,提升参数的准确度,0.5为学习效率(一般小于1)
train = optimizer.minimize(loss) #训练以减少误差
init = tf.initialize_all_variables() #初始化tf结构图中的所有变量,这里是Weights和biases
### create tensorflow structure end ###
sess = tf.Session() #激活创建的结构图,Sesssion是神经网路的执行命令的对话控制
sess.run(init) #激活init,也就是所有结构
for step in range(201):#让神经网络一步一步的训练 201步
sess.run(train) # 开始训练
if step % 20 == 0: #每间隔20步打印以下训练得到的变量值
print(step, sess.run(Weights), sess.run(biases))
训练效果:
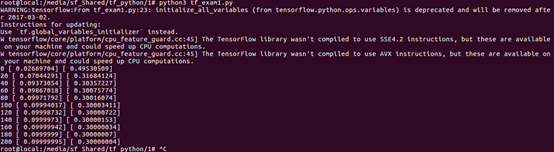
我们看到每个20步打印了训练的权重和偏置,并且随着训练的进行权重和偏置逐渐的逼近0.1和0.3,说明模型通过了训练达到了良好的效果。
实例警告处理
我们同时看到运行过程中有一些警告:
WARNING:tensorflow:From tf_exam1.py:23: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.global_variables_initializer` instead.
意思是initialize_all_variables即将要被弃用,推荐用global_variables_initializer()函数来代替。所以根据提示之际用新的函数代替即可。
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations
这些warings的意思是说:你的机器上有这些指令集可以用,并且用了他们会加快你的CPU运行速度,但是你的TensorFlow在编译的时候并没有用到这些指令集。
我的tensorflow在安装的时候采用的pip install指令,这种安装方式会存在这种问题。主要有两种解决方法,一种是修改警告信息的显示级别,使这种信息不再出现,另外一种就是自己重新编译安装tensorflow,在编译的时候使用这些指令集。这里我尝试第二种解决方法。并且由于我的机器上没有高效的GPU,所以我尝试安装的是CPU版本。
这里因为不影响实验就不处理这个warning,所以修改了第一个warning之后的程序变成:
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
import tensorflow as tf
import numpy as np #科学计算的模块
# create data
x_data = np.random.rand(100).astype(np.float32) #生成100个随机数列,数据类型是float32,tf中大多数都用的是float32
y_data = x_data*0.1 + 0.3 #0.1为权重,0.3为偏置
### create tensorflow structure start ###
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#用Variable初始化Weights权重变量-随机数列生成-1到1的1维数据,
biases = tf.Variable(tf.zeros([1])) #偏置初始化为0,
y = Weights*x_data + biases #所要预测的y,通过训练使得y逼近真实的y_data,优化得到的参数变量就即Weights和biases
loss = tf.reduce_mean(tf.square(y-y_data)) #预测的y和实际的y_data的差别,即均方差
optimizer = tf.train.GradientDescentOptimizer(0.5) #用tf的梯度下降优化器减少误差loss,提升参数的准确度,0.5为学习效率(一般小于1)
train = optimizer.minimize(loss) #训练以减少误差
init = tf.global_variables_initializer() #初始化tf结构图中的所有变量,这里是Weights和biases
### create tensorflow structure end ###
sess = tf.Session() #激活创建的结构图,Sesssion是神经网路的执行命令的对话控制
sess.run(init) #激活init,也就是所有结构
for step in range(201):#让神经网络一步一步的训练 201步
sess.run(train) # 开始训练
if step % 20 == 0: #每间隔20步打印以下训练得到的变量值
print(step, sess.run(Weights), sess.run(biases))
运行的效果:
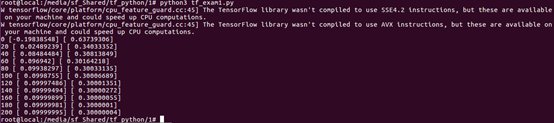
这次没有了第一个警告。
例子程序存放在oschina上:
http://git.oschina.net/wjiang/tensorflow_python3
git clone http://git.oschina.net/wjiang/tensorflow_python3