马拉车用于解决最长回文子串问题,重点是子串,而不是子序列,想了解最长回文子序列的可以看下这篇博客传送门。对于这种问题,当然最简单粗暴的方法就是暴力求解,但太暴力也不好,毕竟会TLE。所以对于求最长回文子串的问题有一种神奇的算法——马拉车算法,神奇就神奇在时间复杂度为O(n)。 我先说一下大概思路,就是用一个Len[i]数组去存第i个位置到mx位置的长度,然后用id记录上一次操作的位置,mx标记上一次的最长子串的最右端,然后依次去递推。不太好理解(花了好几个小时才懂),现在看不懂没关系,我尽量讲的详细点。
以hihoCoder的一道裸题为例,只要能AC就差不多懂了,题目链接:传送门
先定义一个字符串s = “ababc”,因为对于回文字符串来说有对称轴,比如说aba就是以b作为对称轴,那么当字符串长度为偶数的时候,对称轴就不是唯一的整数位了。所以我们要对原字符串
做一个预处理,在每个字符左右都加上一个特殊字符,这里我用’#’,那么处理后的字符串str就是#a#b#a#b#c#了,不管原字符串长度是奇数还是偶数,处理后的长度都变成奇数了。然后还需要在这个str的最前面加一个不同于之前的特殊字符的特殊字符,这里我用了’%’(因为在后面的while循环中在匹配字符的时候可能会越界)。这样预处理操作就完了,最后的字符串str就是%#a#b#a#b#c#了。
首先需要明白的是,我定义的mx是上一次操作的最长回文子串的最右端,我解释一下,比如说ababa,第一次对i=2操作的时候,会计算出他的最回文子串为aba(长度为3),则在这次操作结束后mx的位置就是4,也就是aba的下一位。而我定义的id是上一次操作的位置,也就是i的位置,还以刚才的例子为例,在对i=2操作结束后,id的位置就是2。姑且先这么理解,知道他是什么就行,后面再去思考。
Len数组里存的是第i个位置到mx位置的长度,比如说还是ababa,当i=2的时候,可以计算出aba是它此时的最长回文子串,那么mx的位置就是aba的下一位,那Len[2]存的就是mx - i了。最重要的就是Len数组,所以这点一定要弄明白,Len存的是,当前这个位置到它的最长回文子串的最右端的距离(也就是mx的位置)。在str字符串中,Len[i] = 2*Len[i] - 1(因为有特殊字符),在s字符串中Len[i] = mx - id + 1。
知道这些后,开始进入正题,先看下核心代码。

首先把mx初始化0,然后开始从i=1开始遍历str,当i>=mx的时候,也就是i在mx前面的时候,就让Len[i] = 1,表示在i之前没有回文串出现,所以让Len从1开始,然后先不说i<mx的情况,然后往下走到while循环,这个循环就是用来判断这个位置的最长回文子串的,就是以这个点为中心,然后依次比较左边一个和右边一个、左边第二个和右边第二个…是否相等,相等的话就让Len[i]++,就相当于这个位置到这个位置的子串的最右端的长度++。然后再比较这个点+这个点的回文长度是否超过了mx的位置,超过的话就更新一下mx的值,因为mx是此次操作的最长回文子串的最右端。
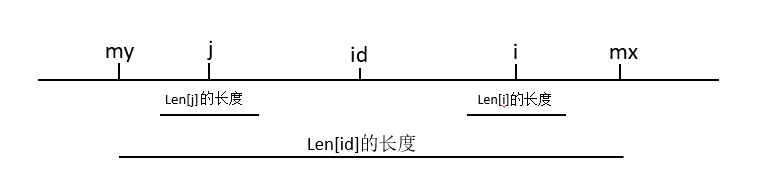
然后对于i<mx的情况就稍微有点不太好理解了,参考着上图我讲一下这种情况。这是一个以id(上一次操作的位置)为中点长度为mx-my的回文串,j是以id为中点的i的对称点,因为j在之前遍历的时候就已经操作过了,所以Len[j]是已知的又因为回文串的性质可以知道Len[j]<=Len[i]的,my是mx的对称点。对于i<mx的情况还要再分情况,就是Len[j]和mx-i比较了,上图的情况是Len[j]是小于mx-i的,表示j位置的最长回文子串的长度是在id位置的最长回文子串的范围内的,还有一种情况就是Len[j]>mx-i,如下图所示,Len[j]的长度的范围超出了my。
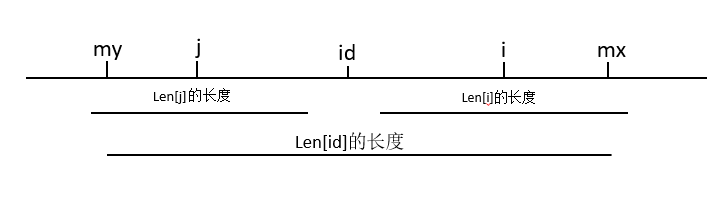
所以我们需要对这两种情况再讨论一下,当Len[j] < mx-i的时候,表示Len[i]的长度可能不会超过mx-i,所以我们就从i的Len[2*id - i]也就是Len[mx-i]的地方开始匹配。当Len[j] > mx - i的时候,说明i位置的子串长度超过了mx,但mx以外的地方还没有遍历到,所以我们就从mx-i也就是mx的位置开始对i匹配。
然而最后的结果就是下图这样的

用一个sum去更新最大值就行了。我觉得挺不好理解的,建议耐下心想一想,模拟一遍,有不懂的都可以评论,有不对的地方也请指出。然后上一个前面说的那道题的代码,也是Manacher的模板。
#include <iostream>
#include <cstdio>
#include <cstring>
#define Min(a,b) a>b?b:a
#define Max(a,b) a>b?a:b
using namespace std;
const int N = 2e6 + 10 ;
int Len[N] , a[N] ;
char str[N] ;
int n,mx,id,len;
string s ;
void init(int l , int r){
int k=0;
str[k++] = '$';
for(int i=l;i<=r;i++){
str[k++]='#';
str[k++]=s[i];
}
str[k++]='#';
len=k;
str[k] = '�' ;
}
int ans = 0 , flag ;
int Manacher(){
Len[0] = 0;
int sum = 0;
mx = 0;
id = 0 ;
// cout << str << endl ;
for(int i=1;i<len;i++){
if(i < mx) Len[i] = Min(mx - i, Len[2 * id - i]);
else Len[i] = 1;
while(str[i - Len[i]]== str[i + Len[i]]) Len[i]++;
if(Len[i] + i > mx){ // 更新最长的回文串
mx = Len[i] + i; // mx是回文串右边一个位置
id = i; //id是回文串的中心
sum = Max(sum, Len[i]); // sum 是回文串的长度 + 1
}
// cout << i << " " << Len[i] << endl ;
// if(Len[i] == i) 表示前缀是回文的
// {
// if(ans < Len[i])
// ans = Len[i] - 1 , flag = 1 ;
// }
// if(Len[i] + i == len) 表示后缀是回文的
// if(ans < Len[i])
// ans = Len[i] - 1 , flag = 2 ;
}
return sum - 1 ;
}
int main()
{
scanf("%d",&n);
while(n--){
cin >> s ;
len = s.size();
int l = 0 , r = len - 1 ;
init(l , r);
ans = 0 , flag = 0 ;
// cout << Manacher() << endl ;
}
return 0;
}