环境:ubuntu(linux)+gcc+Cmake
LTP源码:https://github.com/HIT-SCIR/ltp/releases
LTP模型:https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2Fltp-models
下载ltp源码ltp-3.4.0解压并进入
LTP的C++源码编译及测试
./configure
make
编译成功后,会在bin目录下生成一下二进制文件
| 程序名 | 说明 |
|---|---|
| ltp_test | LTP主程序 |
| ltp_server | LTP Server |
在 bin/examples 目录下生成以下二进制程序
| 程序名 | 说明 |
|---|---|
| cws_cmdline | 分词模块命令行程序 |
| pos_cmdline | 词性标注模块命令行程序 |
| ner_cmdline | 命名实体识别模块命令行程序 |
| par_cmdline | 依存句法分析模块命令行程序 |
在 examples 目录下有C++源码和Makefile文件
使用pos_cmdline完成词性标注测试
$ cat input
这 是 测试 样本 ,中文 句法 分析 。
$ cat input | ./bin/examples/pos_cmdline --postagger-model ./ltp_model/pos.model
TRACE: Model is loaded
TRACE: Running 1 thread(s)
WARN: Cann't open file! use stdin instead.
这_r 是_v 测试_v 样本_n ,中文_nz 句法_n 分析。_v
TRACE: consume 0.162231 seconds.
在Linux下使用动态库生成可执行程序
(1)分词cws.cpp代码如下
#include <iostream>
#include <string>
#include "ltp/segment_dll.h"
int main(int argc, char * argv[])
{
if (argc < 2) //命令行参数,没有分词模型的情况下输出
{
std::cerr << "cws [model path] [lexicon_file]" << std::endl;
return 1;
}
void * engine = 0; //声明一个指向模型的指针
if (argc == 2) //第一个命令行参数,为分词模型
{
engine = segmentor_create_segmentor(argv[1]); //分词接口,初始化分词器
}
else if (argc == 3) //第二个命令行参数,可以外加词典文件
{
engine = segmentor_create_segmentor(argv[1], argv[2]); //分词接口,初始化分词器
}
if (!engine)
{
return -1;
}
std::vector<std::string> words; //将分词结果存入vector中
//分词的文本
const char * suite[2] = {
"What's wrong with you? 别灰心! http://t.cn/zQz0Rn", "台北真的是天子骄子吗?",};
for (int i = 0; i < 2; ++ i) {
words.clear();
int len = segmentor_segment(engine, suite[i], words); //分词接口,对句子分词。
for (int i = 0; i < len; ++ i) {
std::cout << words[i];
if (i+1 == len) std::cout <<std::endl;
else std::cout<< "|";
}
}
segmentor_release_segmentor(engine); //分词接口,释放分词器
return 0;
}
(2)生成cws可执行程序
将下载的LTP置于 ltp-project 目录下,编译命令如下
$ g++ -o cws cws.cpp -I ../include/ -I ../thirdparty/boost/include/ -Wl,-dn -L ../lib/ -lsegmentor -lboost_regex -Wl,-dy
运行生成的可执行程序
$ cws ../ltp_model/cws.model
运行结果如下:
- What's|wrong|with|you|?|别|灰心|!|http://t.cn/zQz0Rn
- 台北|真|的|是|天子骄子|吗|?
构建基于LTP的句法分析类Parsing
#include <iostream>
#include <vector>
#include "ltp/segment_dll.h"
#include "ltp/postag_dll.h"
#include "ltp/parser_dll.h"
using namespace std;
//构建LTP句法分析类
class Parsing
{
public:
void* cws_engine = 0;
void* pos_engine = 0;
void* par_engine = 0;
vector<string> words;
vector<string> postags;
vector<int> heads;
vector<string> deprels;
public:
void get_models(char* cws, char* pos, char* par);
void get_words(string str);
void get_postags(string str);
void get_parsing(string str);
void release_model();
};
//加载模型文件
void Parsing::get_models(char* cws,char* pos,char* par)
{
cws_engine = segmentor_create_segmentor(cws);
pos_engine = postagger_create_postagger(pos);
par_engine = parser_create_parser(par);
}
//分词
void Parsing::get_words(string str)
{
words.clear();
segmentor_segment(cws_engine, str, words);
}
//词性标注
void Parsing::get_postags(string str)
{
words.clear();
postags.clear();
segmentor_segment(cws_engine, str, words);
postagger_postag(pos_engine, words, postags);
}
//句法分析
void Parsing::get_parsing(string str)
{
words.clear();
postags.clear();
heads.clear();
deprels.clear();
segmentor_segment(cws_engine, str, words);
postagger_postag(pos_engine, words, postags);
parser_parse(par_engine, words, postags, heads, deprels);
}
//释放模型
void Parsing::release_model()
{
segmentor_release_segmentor(cws_engine);
postagger_release_postagger(pos_engine);
parser_release_parser(par_engine);
}
int main(int argc, char * argv[])
{
Parsing pars;
//pars.get_models("/mnt/f/ltp_project/ltp_model/cws.model","/mnt/f/ltp_project/ltp_model/pos.model","/mnt/f/ltp_project//ltp_model/parser.model");
pars.get_models(argv[1],argv[2],argv[3]);
//cout<<"测试代码"<<endl;
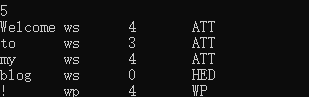
pars.get_parsing("Welcome to my blog!");
cout<<pars.words.size()<<endl;
for (int i = 0; i < pars.words.size(); i++)
{
cout << pars.words[i]<<' '<<pars.postags[i]<<' '<<pars.heads[i]<<' '<<pars.deprels[i]<< endl;
//cout << pars.postags[i] << endl;
//cout << pars.heads[i] << endl;
//cout << pars.deprels[i] << endl;
}
pars.release_model();
return 0;
}
使用Parsing类实现句法分析
生成Parsing可执行程序
$ g++ -o parsing parsing.cpp -I ../include/ -I ../thirdparty/boost/include/ -Wl,-dn -L ../lib/ -lsegmentor -lpostagger -lparser -lboost_regex -Wl,-dy
运行Parsing可执行程序
$ ./parsing ../ltp_model/cws.model ../ltp_model/pos.model ../ltp_model/parser.model
运行结果如下