本文是一些比较基础的shellcode开发技巧,有些技巧可能已经过时了。所有内容均摘自《0day安全软件漏洞分析技术 第二版》
关于exploit和shellcode的区别:
植入代码前需要大量调试,如,弄清程序有几个输入点,这些输入将最终会当做哪几个函数的第几个参数读入到内存的哪一个区域,哪一个输入会造成栈溢出,在复制到栈区的时候对这些数据有没有额外的限制等。调试之后,还要计算函数返回地址距离缓冲区的偏移并淹没之,选择指令的地址,最终制作出一个有攻击效果的“承载”着shellcode的输入字符串。这个代码植入的过程就是漏洞利用,即exploit
exploit关心的是怎样淹没返回地址,获得进程控制权,把EIP传递给shellcode让其得到执行,而并不关心shellcode到底是弹出一个对话框还是格式化硬盘。
设计shellcode需要考虑以下问题:
- shellcode的地址是动态变化的(程序运行过程中被动态加载),如何定位到shellcode?
- 缓冲区有shellcode、函数返回地址、用于填充的数据,我们该如何组织缓冲区的这些内容?(有人可能觉得这个问题莫名其妙,请看下面
2. 组织缓冲区) - shellcode运行中势必要用到一些系统API,而不同系统、机器下同一API的入口地址等往往有所差异。如何让shellcode自动获得API地址?
- shellcode太大,如何绕过软件对缓冲区的限制及IDS(入侵检测系统)等检查?
- 在整个缓冲区空间有限的情况下,如何使代码更加精简?
0. shellcode调试模板
char shellcode[]="x66x81xEC......"; //预调试的十六进制机器码 void main(){ __asm{ lea eax,shellcode push eax ret } }
1. 定位shellcode
有人想,我们完全可以用越界的字符将返回地址覆盖为shellcode在内存中的起始地址。然而由于动态链接库的装入和卸载等原因,win进程函数栈帧“移位”,shellcode在内存中的地址是会动态变化的。
这里给出一个解决办法,此办法基于以下两点:
- kernel32.dll、user32.dll之类的动态链接库几乎会被所有进程加载,且加载基址始终相同
- ESP寄存器不会被缓冲区的溢出数据干扰,只要函数返回时(retn执行后),ESP一定恰好指向栈帧中返回地址的后一个位置
所以解决办法是:用kernel32.dll(或其他dll)内存中任意一个jmp esp指令的地址覆盖函数返回地址;重新布置shellcode,确保shellcode恰好摆放在函数返回地址之后。这样,jmp esp指令执行后会恰好跳进shellcode
除了利用jmp esp定位shellcode,还可以利用mov eax esp、jmp eax等指令进入栈区,而EAX、EBX、ESI等寄存器也会指向栈顶附近,我们只要保证栈区的一大段nop执行之后就是shellcode即可
2. 组织缓冲区
把shellcode放在函数返回地址之后的话,可以不用担心自身被压栈数据破坏,但是这样一来shellcode可能会破坏前栈帧数据,导致无法让函数正常返回继续执行原程序。
当缓冲区相对shellcode较大时,我们把shellcode放在缓冲区的“前端”(内存低址方向),这时shellcode离栈顶较远,压栈操作可能只会破坏一些填充值nop。
如果担心shellcode被压栈数据破坏,可以在shellcode一开始就大范围抬高栈顶,把shellcode“藏”在栈内。
有时候,返回地址距离缓冲区的偏移量不确定,可以这样:
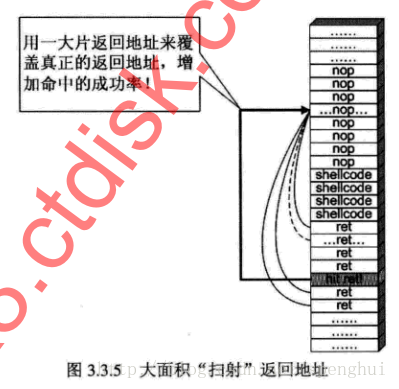
但是这个做法有个缺陷,我们想要的恶意函数返回地址有可能按照字节错位。如不同输入下strcat产生的字节错位导致返回地址0x7c81cdda发生错位:
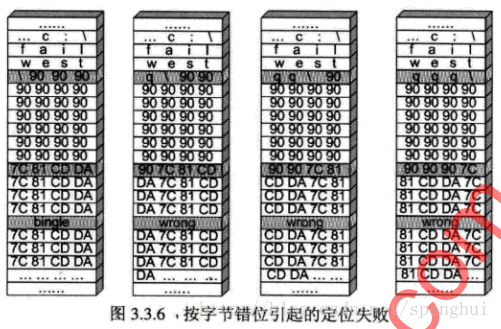
解决办法是:使用0x0a0a0a0a、0x0c0c0c0c之类的返回地址。当然这种情况下,shellcode位于堆上。
3. 定位API

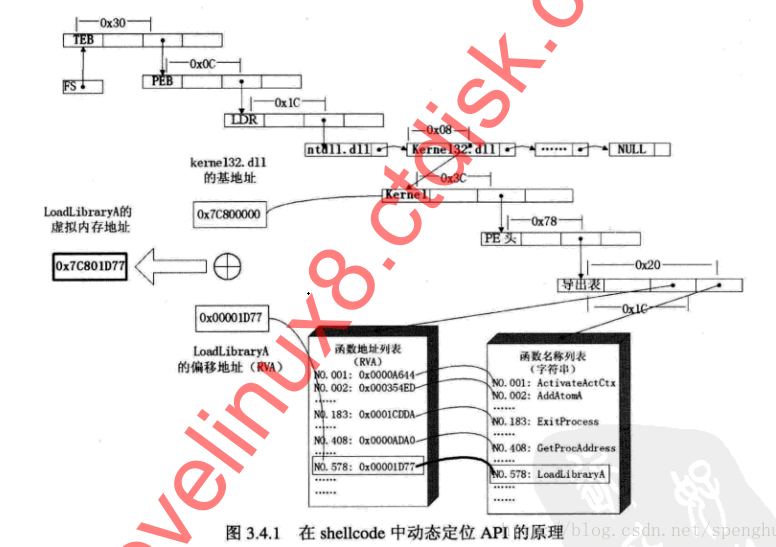
为了使shellcode尽可能短,在函数名导出表中搜索函数名时,一般情况不会直接比对函数名字符串,而是对所需API函数名进行hash运算,在搜索导出表时对当前函数名也进行同样的hash,比较两次hash所得摘要。此法虽引入额外算法,但胜在节约存储函数名称字符串空间。
利用此法进行hash摘要比较时,注意先将增量标志DF清零,否则字串处理方向可能会让摘要比较发生错误。
4. shellcode编码
很多场景里shellcode会受如下限制:
NULL字节限制、可见字符ASCII值或Unicode值限制,甚至有IDS系统会根据代码特征拦截shellcode。
可以对shellcode进行编码,附带一段解码程序,这样就可以只重点关注解码程序是否符合限制。
最简单的编码过程就是异或运算,但是要注意用于异或的特定数据不能喝shellcode已有字节相同,否则编码后会产生NULL字节。
5. 精简代码
尽量选短指令、复合指令
尽量节约指令,降低代码冗余度(如很多API调用会向栈中压入NULL,可考虑初始时将栈中一大片区域全置为NULL,从而节约xor ebx,ebx;push ebx之类的指令;又如许多系统API都比较健壮,两个API用到的数据结构重叠也没关系)
不用把代码和数据分得太开
活用寄存器
活用hash