前面我们对K8s的基本组件与概念有了个大致的印象,并且基于K8s实现了一个初步的CI/CD流程,但对里面涉及的各个对象(如Namespace, Pod, Deployment, Service, Ingress, PVC等)及各对象的管理可能还缺乏深入的理解与实践,接下来的文章就让我们一起深入K8s的各组件内部来一探究竟吧。下图是基于个人的理解梳理的一个K8s结构图,示例了各个组件(只包含了主要组件)如何协同。
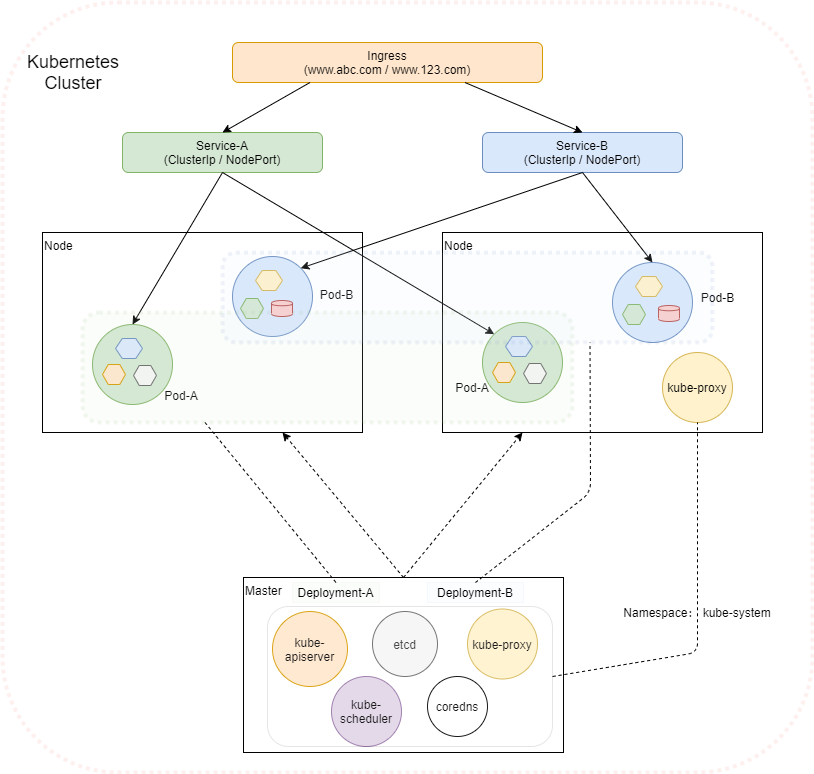
后续几篇文章围绕该图涉及组件进行整理介绍,本文主要探究Namespace及与Namespace管理相关的资源限制ResourceQuota/LimitRange部分。
Namespace
理解
Namespace即命名空间,主要有两个方面的作用:
- 资源隔离:可为不同的团队/用户(或项目)提供虚拟的集群空间,共享同一个Kubernetes集群的资源。比如可以为团队A创建一个Namespace ns-a,团队A的项目都部署运行在 ns-a 中,团队B创建另一个Namespace ns-b,其项目都部署运行在 ns-b 中,或者为开发、测试、生产环境创建不同的Namespace,以做到彼此之间相互隔离,互不影响。我们可以使用 ResourceQuota 与 Resource LimitRange 来指定与限制 各个namesapce的资源分配与使用
- 权限控制:可以指定某个namespace哪些用户可以访问,哪些用户不能访问
Kubernetes 安装成功后,默认会创建三个namespace:
- default:默认的namespace,如果创建Kubernetes对象时不指定 metadata.namespace,该对象将在default namespace下创建
- kube-system:Kubernetes系统创建的对象放在此namespace下,我们前面说的kube-apiserver,etcd,kube-proxy等都在该namespace下
- kube-public:顾名思义,共享的namespace,所有用户对该namespace都是可读的。主要是为集群做预留,一般都不在该namespace下创建对象
实践
1.查看namesapce
kubectl get namespaces
kubectl get namesapce
kubectl get ns # 三个操作等效
kubectl get ns --show-labels # 显示namespace的label
使用namesapces,namesapce,ns都是可以的。如下列出了当前集群中的所有namespace
[root@kmaster ~]# kubectl get ns
NAME STATUS AGE
default Active 34d
develop Active 17d
ingress-nginx Active 33d
kube-node-lease Active 34d
kube-public Active 34d
kube-system Active 34d
kubernetes-dashboard Active 31d
pre-release Active 17d
可以使用 kubectl describe 命令来查看某个namespace的概要信息,如
[root@kmaster ~]# kubectl describe ns default
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
No resource limits.
2.创建namespace
有两种方式:通过yaml定义文件创建或直接使用命令创建。
# 方式1. 通过yaml定义文件创建
[root@kmaster ~]# vim test-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test # namespace的名称
labels:
name: ns-test
[root@kmaster ~]# kubectl create -f ./test-namespace.yaml
# 方式2. 直接使用命令创建
[root@kmaster ~]# kubectl create ns test
3.在namesapce中创建对象
# 1. 在yaml中通过metadata.namesapce 指定
[root@kmaster ~]# kubectl get deploy my-nginx -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: my-nginx
name: my-nginx
namespace: test # 指定namespace
spec:
...
# 2. 在命令中通过 -n 或 --namesapce 指定
[root@kmaster ~]# kubectl run dev-nginx --image=nginx:latest --replicas=3 -n test
4.设定kubectl namesapce上下文
kubectl上下文即集群、namespace、用户的组合,设定kubectl上下文,即可以以上下文指定的用户,在上下文指定的集群与namespace中进行操作管理。查看当前集群kubectl上下文
# 查看当前kubectl上下文
[root@kmaster ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.40.111:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
可见当前上下文为kubernetes-admin@kubernetes (current-context: kubernetes-admin@kubernetes)。
创建一个kubectl上下文
[root@kmaster ~]# kubectl config set-context test --namespace=test --cluster=kubernetes --user=kubernetes-admin
Context "test" created.
再次执行 kubectl config view 将可以看到上面创建的test上下文。
切换上下文
# 设置当前上下文
[root@kmaster ~]# kubectl config use-context test
Switched to context "test".
# 查看当前所在的上下文
[root@kmaster ~]# kubectl config current-context
test
指定了上下文,后续操作都在该上下文对应的namespace中进行,不需要再显式指定namespace。在上下文中创建对象
# 在当前上下文中创建对象
[root@kmaster ~]# kubectl run my-nginx --image=nginx:latest --replicas=2
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/my-nginx created
# 查看创建的对象,不需要指定namespace
[root@kmaster ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
my-nginx 2/2 2 2 25m
[root@kmaster ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx-667764d77b-ldb78 1/1 Running 0 24m
my-nginx-667764d77b-wpgxw 1/1 Running 0 24m
删除上下文
[root@kmaster ~]# kubectl config delete-context test
deleted context test from /root/.kube/config
也可以使用如下命令直接切换默认的namespace
# 将默认namespace设置为test
[root@kmaster ~]# kubectl config set-context --current --namespace=test
5.删除namesapce
可以使用 kubectl delete ns <namespace名称> 来删除一个namesapce,该操作会删除namespace中的所有内容。
[root@kmaster ~]# kubectl delete ns test
Resource Quota
Resource Quota即资源配额,限定单个namespace中可使用集群资源的总量,包括两个维度:
- 限定某个对象类型(如Pod)可创建对象的总数;
- 限定某个对象类型可消耗的计算资源(CPU、内存)与存储资源(存储卷声明)总数
如果在 namespace 中为计算资源 CPU 和内存设定了 ResourceQuota,用户在创建对象(Pod、Service等)时,必须指定 requests 和 limits;如果在创建或更新对象时申请的资源与 namespace 的 ResourceQuota 冲突,则 apiserver 会返回 HTTP 状态码 403,以及对应的错误提示信息。当集群中总的容量小于各个 namespace 资源配额的总和时,可能会发生资源争夺,此时 Kubernetes 将按照先到先得的方式分配资源。
对象数量限制
声明格式为: count/<resource>.<group>, 如下列出各类对象的声明格式
count/persistentvolumeclaims
count/services
count/secrets
count/configmaps
count/replicationcontrollers
count/deployments.apps
count/replicasets.apps
count/statefulsets.apps
count/jobs.batch
count/cronjobs.batch
count/deployments.extensions
计算资源限制
定义CPU、内存请求(requests)、限制(limits)使用的总量,包括
- limits.cpu:namespace中,所有非终止状态的 Pod 的 CPU 限制 resources.limits.cpu 总和不能超过该值
- limits.memory:namespace中,所有非终止状态的 Pod 的内存限制 resources.limits.memory 总和不能超过该值
- requests.cpu:namespace中,所有非终止状态的 Pod 的 CPU 请求 resources.requrest.cpu 总和不能超过该值
- requests.memory:namespace中,所有非终止状态的 Pod 的 CPU 请求 resources.requests.memory 总和不能超过该值
存储资源限制
定义存储卷声明请求的存储总量或创建存储卷声明数量的限制,包括
- requests.storage:namespace中,所有存储卷声明(PersistentVolumeClaim)请求的存储总量不能超过该值
- persistentvolumeclaims:namespace中,可以创建的存储卷声明的总数不能超过该值
<storage-class-name>.storageclass.storage.k8s.io/requests.storage:namespace中,所有与指定存储类(StorageClass)关联的存储卷声明请求的存储总量不能超过该值<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims:namespace中,所有与指定存储类关联的存储卷声明的总数不能超过该值
除此之外,还可以对本地临时存储资源进行限制定义
- requests.ephemeral-storage:namespace中,所有 Pod 的本地临时存储(local ephemeral storage)请求的总和不能超过该值
- limits.ephemeral-storage:namespace中,所有 Pod 的本地临时存储限定的总和不能超过此值
实践
查看是否开启 Resource Quota 支持,默认一般是开启的。如果没有,可在启动 apiserver 时为参数 --enable-admission-plugins 添加 ResourceQuota 配置项。
1.创建ResourceQuota
# 创建namespace
[root@kmaster ~]# kubectl create namespace test
# 编辑ResourceQuota定义文档
[root@kmaster ~]# vim quota-test.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-test
namespace: test
spec:
hard:
requests.cpu: "2"
requests.memory: 2Gi
limits.cpu: "4"
limits.memory: 4Gi
requests.nvidia.com/gpu: 4
pods: "3"
services: "6"
# 创建ResourceQuota
[root@kmaster ~]# kubectl apply -f quota-test.yaml
# 查看
[root@kmaster ~]# kubectl get quota -n test
NAME CREATED AT
quota-test 2020-05-26T10:31:10Z
[root@kmaster ~]# kubectl describe quota quota-test -n test
Name: quota-test
Namespace: test
Resource Used Hard
-------- ---- ----
limits.cpu 0 4
limits.memory 0 4Gi
pods 0 3
requests.cpu 0 2
requests.memory 0 2Gi
requests.nvidia.com/gpu 0 4
services 0 6
或者使用kubectl命令,如
[root@kmaster ~]# kubectl create quota quota-test --hard=count/deployments.extensions=2,count/replicasets.extensions=4,count/pods=3,count/secrets=4 --namespace=test
我们在namespace test中创建了一个ResourceQuota,限制CPU、内存请求为2、2GB,限制CPU、内存限定使用为4、4GB,限制Pod个数为3 等。
我们来尝试创建一个如下定义的Deployment来测试一下,
# 创建一个测试deploy
[root@kmaster ~]# vim quota-test-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: quota-test-deploy
spec:
selector:
matchLabels:
purpose: quota-test
replicas: 3
template:
metadata:
labels:
purpose: quota-test
spec:
containers:
- name: quota-test
image: nginx
resources:
limits:
memory: "2Gi"
cpu: "1"
requests:
memory: "500Mi"
cpu: "500m"
[root@kmaster ~]# kubectl apply -f quota-test-deploy.yaml -n test
# 查看pod
[root@kmaster ~]# kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
quota-test-deploy-6b89fdc686-2dthq 1/1 Running 0 3m54s
quota-test-deploy-6b89fdc686-9m2qw 1/1 Running 0 3m54s
# 查看deploy状态
[root@kmaster ~]# kubectl get deploy quota-test-deploy -n test -o yaml
message: 'pods "quota-test-deploy-6b89fdc686-rmktq" is forbidden: exceeded quota:
quota-test, requested: limits.memory=2Gi, used: limits.memory=4Gi, limited:
limits.memory=4Gi'
replicas: 3定义创建三个Pod副本,但只成功创建了两个Pod,在deploy的status部分(最后一条命令结果),我们可以看到message提示第三个Pod创建时被拒绝,因为内存已达到限定。我们也可以将limits.memory调整为1Gi,将replicas调整为4,来验证对Pod个数的限制。可看到最终只起了三个Pod,status部分message提示 pods "quota-test-deploy-9dc54f95c-gzqw7" is forbidden: exceeded quota:quota-test, requested: pods=1, used: pods=3, limited: pods=3。
Resource Limit Range
理解
Resource Quota 是对namespace中总体的资源使用进行限制,Resource Limit Range 则是对具体某个Pod或容器的资源使用进行限制。默认情况下,namespace中Pod或容器的资源消耗是不受限制的,这就可能导致某个容器应用内存泄露耗尽资源影响其它应用的情况。Limit Range可以用来限定namespace内Pod(或容器)可以消耗资源的数量。
使用LimitRange对象,我们可以:
- 限制namespace中每个Pod或容器的最小与最大计算资源
- 限制namespace中每个Pod或容器计算资源request、limit之间的比例
- 限制namespace中每个存储卷声明(PersistentVolumeClaim)可使用的最小与最大存储空间
- 设置namespace中容器默认计算资源的request、limit,并在运行时自动注入到容器中
如果创建或更新对象(Pod、容器、PersistentVolumeClaim)对资源的请求与LimitRange相冲突,apiserver会返回HTTP状态码403,以及相应的错误提示信息;如果namespace中定义了LimitRange 来限定CPU与内存等计算资源的使用,则用户创建Pod、容器时,必须指定CPU或内存的request与limit,否则将被系统拒绝;当namespace总的limit小于其中Pod、容器的limit之和时,将发生资源争夺,Pod或者容器将不能创建,但不影响已经创建的Pod或容器。
实践
创建一个测试namespace test-limitrange,
# 创建测试namespace
[root@kmaster ~]# kubectl create namespace test-limitrange
# 切换默认的namespace
[root@kmaster ~]# kubectl config set-context --current --namespace=test-limitrange
创建LimitRange定义文件 lr-test.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: lr-test
spec:
limits:
- type: Container #资源类型
max:
cpu: "1" #限定最大CPU
memory: "1Gi" #限定最大内存
min:
cpu: "100m" #限定最小CPU
memory: "100Mi" #限定最小内存
default:
cpu: "900m" #默认CPU限定
memory: "800Mi" #默认内存限定
defaultRequest:
cpu: "200m" #默认CPU请求
memory: "200Mi" #默认内存请求
maxLimitRequestRatio:
cpu: 2 #限定CPU limit/request比值最大为2
memory: 1.5 #限定内存limit/request比值最大为1.5
- type: Pod
max:
cpu: "2" #限定Pod最大CPU
memory: "2Gi" #限定Pod最大内存
- type: PersistentVolumeClaim
max:
storage: 2Gi #限定PVC最大的requests.storage
min:
storage: 1Gi #限定PVC最小的requests.storage
该文件定义了在namespace test-limitrange 中,容器、Pod、PVC的资源限制,在该namesapce中,只有满足如下条件,对象才能创建成功
- 容器的
resources.limits部分CPU必须在100m-1之间,内存必须在100Mi-1Gi之间,否则创建失败 - 容器的
resources.limits部分CPU与resources.requests部分CPU的比值最大为2,memory比值最大为1.5,否则创建失败 - Pod内所有容器的
resources.limits部分CPU总和最大为2,内存总和最大为2Gi,否则创建失败 - PVC的
resources.requests.storage最大为2Gi,最小为1Gi,否则创建失败
如果容器定义了
resources.requests没有定义resources.limits,则LimitRange中的default部分将作为limit注入到容器中;如果容器定义了resources.limits却没有定义resources.requests,则将requests值也设置为limits的值;如果容器两者都没有定义,则使用LimitRange中default作为limits,defaultRequest作为requests值
创建与查看LimitRange,
# 创建LimitRange
[root@kmaster ~]# kubectl apply -f lr-test.yaml
# 查看
[root@kmaster ~]# kubectl describe limits lr-test
Name: lr-test
Namespace: test-limitrange
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 100m 1 200m 900m 2
Container memory 100Mi 1Gi 200Mi 800Mi 1500m
Pod cpu - 2 - - -
Pod memory - 2Gi - - -
PersistentVolumeClaim storage 1Gi 2Gi - - -
我们可以创建不同配置的容器或Pod对象来验证,出于篇幅不再列出验证步骤。
总结
本文对K8s的Namespace及针对Namespace的资源限制管理ResourceQuota,LimitRange进行了较为深入的探索,其中ResourceQuota对整个Namespace的资源使用情况进行限制,LimitRange则对单个的Pod或容器的资源使用进行限制。Namespace的权限控制可基于RBAC来实现,后续再单独进行梳理介绍。
原文地址:http://blog.jboost.cn/k8s4-namespace.html
相关阅读:
- Kubernetes笔记(一):十分钟部署一套K8s环境
- Kubernetes笔记(二):了解k8s的基本组件与概念
- Kubernetes笔记(三):Gitlab+Jenkins Pipeline+Docker+k8s+Helm自动化部署实践(干货分享!)
作者:雨歌,一枚仍在学习路上的IT老兵
欢迎关注作者公众号:半路雨歌,一起学习成长
