本节的主要内容:
一、Receiver启动的方式设想
二、Receiver启动源码彻底分析
Receiver的设计是非常巧妙和出色的,非常值得我们去学习、研究、借鉴。
在深入认识Receiver之前,我们有必要思考一下,如果没有Spark、Spark Streaming,我们怎么实现Reciver?数据不断接进来,我们该怎么做?该怎么启动Receiver呢?......
首先,我们找到数据来源的入口,入口如下:

数据来源kafka、socket、flume等构建的都是基于InputDStream的,输入数据来源很关键,没有输入数据来源就无法产生数据,batchDuration就无法获取数据,RDD就无流处理数据及其它故事了。
我们从研究soketTexStream的receiverInputDstream来研究Receiver:
Receiver不断持续的接收外部数据源流入的数据、并将不断接收到数据的元数据汇报给Driver,每个batchDuration会根据汇报的数据生成不同的Job并执行相应的RDD transformation操作。
设想设计一个Receiver:
Receiver是Spark Streaming应用程序启动的一部分,他是随着Spark Streaming启动的时候启动的。怎么启动Receivers?
一个应用程序可以启动多个Receiver,分析源码的DStream Graph:

从上面的源码中分析得出:
通过ArrayBuffer数组来存储InputDStream对象列表,根据Receiver的个数,可以推导出InputDStream对象可以有多个,OutputStream也可以有多个。
如果Spark Streaming应用程序处理的后业务逻辑有多个输出,则会有多个不同的inputStream数据来源,会创建多个InputDStream对象,我们的实验代码只创建一个inputStream。
默认情况下假设:
1、只有一个Partition,我们启动一个Job RDD的transformation触发Job、并执行Job,因为Job只有一个分片Partition,而Partition只有一个Receiver成员,Reciever对象里面有一条或多条数据。
2、多个inputStream则需要启动多个Receiver,每个Receiver相当于一个Partition,从Spark Core的普通调度角度,在同一个executor上需要启动多个Receiver,只是RDD不同的Partition。
注意:
1、启动Receiver角度分析:
只要集群存在,Receiver就不能失败,如果启动Receiver失败,不同Partition代表不同的Receiver,在一个executor上启动Receivers,每个task代表一个Partition,其中一个task失败导致整个Job失败(虽然有stage有重试),而集群存在,我们的Receivers一定要启动成功。
2、运行Receiver角度分析:
运行过程中也有可能基于每个task启动一个executor的方式,task有可能失败,例如:executor挂掉了,则每个task为单位启动额Receiver也会挂掉,影响接收数据。
所以从启动角度不希望Receiver启动失败;在运行时Receiver的失败,不希望影响已有的工作。
作为Spark Streaming应用程序启动的Job,这个Job失败的话对整个应用程序是致命的问题。
启动应用程序的不同的Receiver,采用RDD的不同Partition代表不同Receiver,启动时通过Partition的执行层面是不同task,每个task启动执行时就需要启动Receiver,实现方式简单,实际就借助Spark Core上的Job的方式,但有弊端:
1、Job启动不成功。
2、运行过程Receiver失败,影响执行,task重试,重试失败,整个Job就失败,导致整个Spark应用就失败了,但Spark Streaming是需要在 7*24小时执行的。
Spark Streaming采用的方式是怎么样的?
Spark Streaming的start方法入手:



Receiver的启动是在JobScheduler的start方法中启动的。

ReceiverTracker类中的start方法:

ReceiverTracker类里面有个RPC消息通信体,ReceiverTracker需要监控整个集群中的Receiver,集群中Receiver汇报接收数据和生命周期给ReceiverTracker。
启动Receiver的执行线程时会判断receiverInputStreams对象列表,只有在其不能为空时才能启动Receiver,Receiver启动需要依赖输入数据流,如果没有receiverInputStreams就不会启动Receiver。
在看launchReveivers方法:

基于receiverInputStreams获得具体receivers实例,在具体的worker nodes上启动了receivers,基于receiverInputStreams,receiverInputStreams是在driver端的,
Spark Streaming作业都是基于RDD的方式,不会认识receiverInputStreams,其就相当于原数据或源对象,都是逻辑级别的,怎么分配到worker nodes上让其物理级别执行。
这个过程其实就是一个简单的Master和Slave结构。
一个inputDStream输入的数据来源只产生一个Receiver,通过getReceiver方法返回的是一个Receiver对象,此方法细节必须在其子类中实现:

receiverInputStreams从DStream Graph对象中获取,Receivers会封装完内部的receiver,并给entpoint 发送消息,RPC通信对象接收到这些信息。
那么Endpoint是哪里来的?是在start方法中是构建的:


Receiver要运行在哪些executor上:

这个方法启动一个Receiver,在已经计划好的executor上去运行,而不是让Spark Core自己来分配,不是通过Spark Core上的RDD task的分配方式,
而是Spark Streaming框架自己决定每个Receiver在哪些executor上执行,没有依赖Spark Core上task的分配方式。
Driver层面自己强制指定TaskLocation。
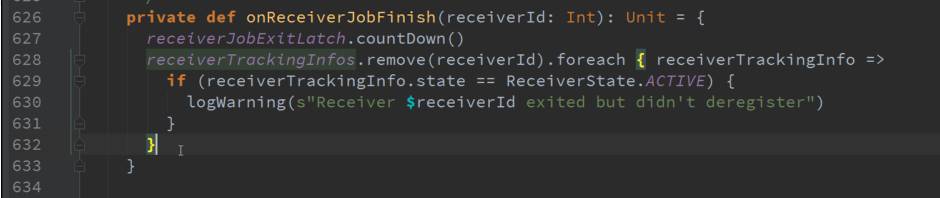
终止启动Receiver意味着不需要重新启动一个Spark Job。

上图这个函数在具体的worker node上启动Receiver的函数。
假设重新启动Receiver则需要重新Job Schduler,而不是taskScheduler的重试。
启动Receiver失败不会启动重试,从启动Job角度来看。
启动ReceiverSuperVisorImpl时Receiver会监听器和接收数据。
看ReceiverSuperVisorImpl的父类start方法,父类反过来调用其子类的onstart方法:


为了启动Receiver,其内部启动了一个Spark Context对象,通过此对象调用了submitJob方法启动了一个Spark作业,这个作业只会启动一个Receiver,
只会启动一个Receiver,每个Receiver的启动都会触发一个Spark Context对象的submitJob方法来启动Job:

每次循环每一个Rceciver时,都会启动一个Spark Job来负责,而不是说所有的Rcecivers都是交给一个Spark Job来负责,有如下考虑:
- Rceciver失败导致应用程序失败。
- 作业运行时有任务倾斜的问题,Spark Core的调度方式有可能会在同一台机器上运行多个Rceciver。
- 作业运行过程中Rceciver失败了导致整个Spark Job失败,进而导致应用程序的失败,代价太大。
每次循环每一个Rceciver时,都会启动一个Spark Job来负责,则一个Job的失败只会影响一个Job的运行,从而最大程度负载均衡。
再看作业的失败,作业失败后会执行restartReceiver方法的代码,给自己发消息,又会把刚才的过程走一遍:

每个Job里面是启动一个Receiver,也就是说每个Job里面就只有一个任务,并且只会在一台机器上运行一个task,最大程度负载均衡。
在启动很多Receiver时用了线程池来处理,可以并发启动Receiver,Receiver之间没有直接关系,可以并发启动、执行。
把Receiver放在哪些位置上,由receiverScheduleringPolicy策略来调度,尽量均匀分配。
在看runDummySparkJob方法:

为了保证Executor活着,其内部自己跑一个Spark Job作业,产生50个Receviers、并发度20的小任务,此Spark Streaming应用程序会跑在所有机器上,确保其均匀的运行。
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
Spark发行版笔记9