最近利用空闲时间实现了一个简易的全文搜索引擎,主要是把学的东西练一下手,目前支持简单的单词搜索和基于用户点击实学习。其他部分还在继续开发(本文主要用以记录设计思路,完整代码等主要的做出来提交。)
1. 基本流程
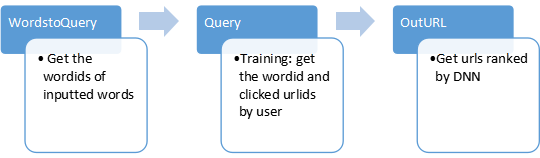
2. 主要模块
2.1 内容获取
定时运行爬取程序。
2.2 分词
调用结巴分词开源包(https://github.com/fxsjy/jieba)
2.3 基本数据组织结构
2.3.1 单词与URL存取
URL: id, url Word: id, word urlConnetword: urlID, wordID
2.3.2 DNN网络结构
Input_to_Hidden: inputid, hiddenid Hidden_to_Output: hiddenid, outpudid 举例: Input -> Hidden -> output Word1 -> Word1_to_word2_id -> URL(包含了Word1与Word2的URL) Word2