1.集群机器:
1台 装了 ubuntu 14.04的 台式机
1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用)
搭建步骤:
准备工作:
使两台机器处于同一个局域网:相互能够 ping 通
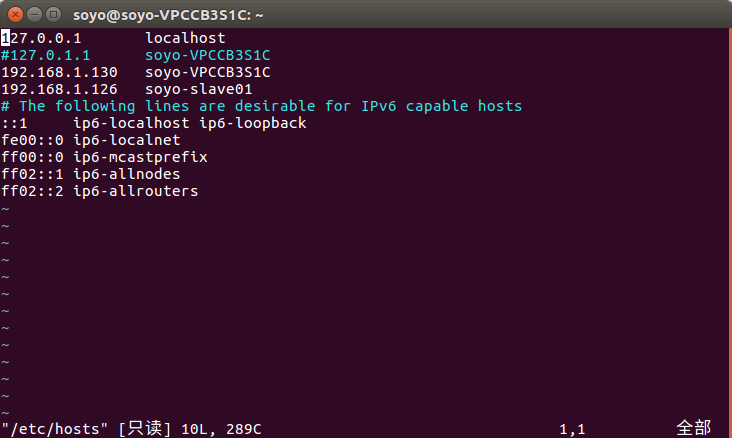
主机名称 IP地址
soyo-VPCCB3S1C 192.168.1.130 (master-->namenode)
soyo-slave01 192.168.1.126 (datanode)
想要更改主机名称的话:sudo vim /etc/hostname 之后重启
之后两台机器都修改 /etc/hosts/ 设置为:
2.配置ssh无密码登录本机和访问集群机器
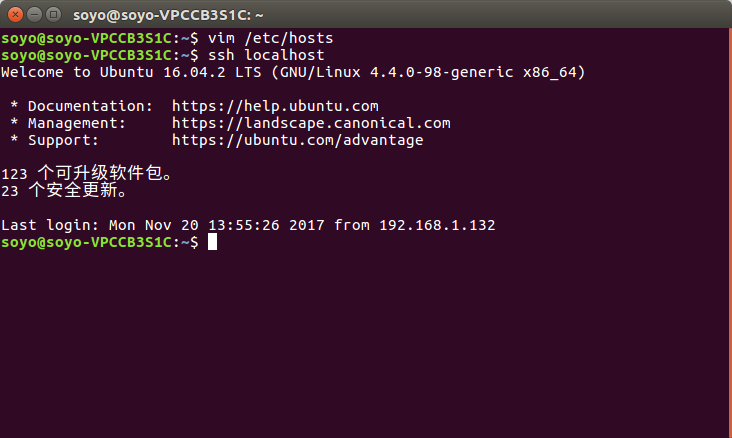
2台主机电脑分别运行如下命令,测试能否连接到本地localhost
ssh localhost
结果:这样说明没问题
如果不能登录本地:
- sudo apt-get openssh-server
- ssh-keygen -t rsa -P "" // 生成ssh公钥
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys // (authorized_keys 刚开始是没有的) SSH无密码登陆授权
在保证了2台主机电脑都能连接到本地localhost后,还需要让master主机免密码登录slave01。在master执行如下命令,将master的id_rsa.pub传送给slave01主机。scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。
scp ~/.ssh/id_rsa.pub soyo@soyo-slave01:/home/soyo/这个时候在soyo-slave01主机的/home/soyo/路径下可以找到 id_rsa.pub 这个文件
- 接着在slave01主机上将master的公钥加入各自的节点上,在soyo-slave01执行如下命令:
- cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
- rm ~/id_rsa.pub
- 配置完成
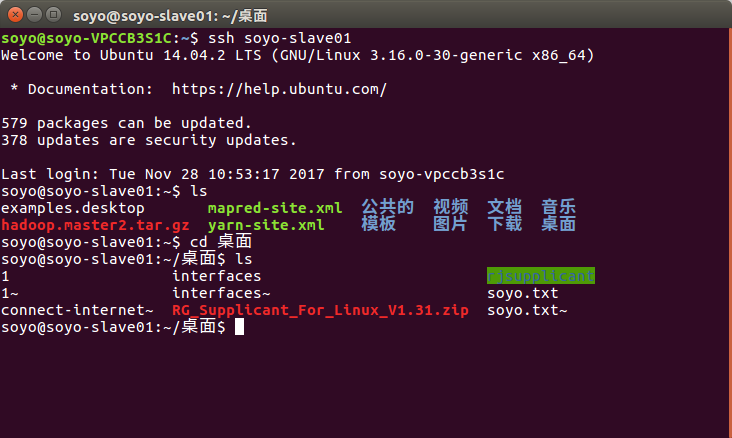
3.在master(soyo-VPCCB3S1C)测试连接soyo-slave01节点:
4.Hadoop分布式配置:
hadoop而而配置文件都位于/usr/local2/hadoop/etc/hadoop目录下。
总共要配置 5 个文件:slaves,core-site.xml,hdfs-site.xml,mapred-site.xml.template(复制后修改名字为mapred-site.xml),yarn-site.xml
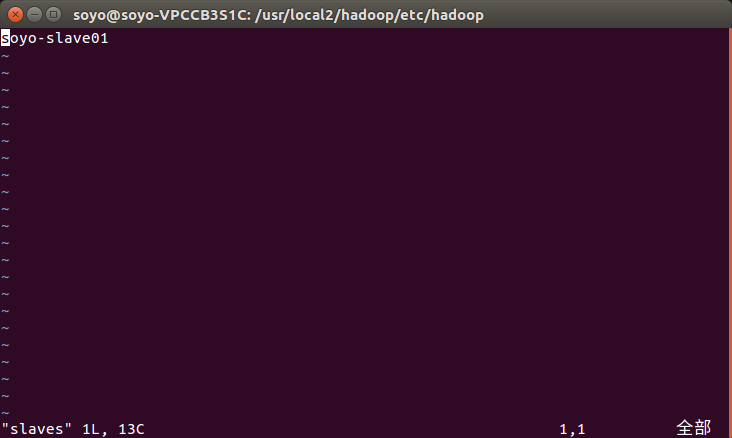
slaves:
core-site.xml:

hdfs-site.xml:

mapred-site.xml:

yarn-site.xml:
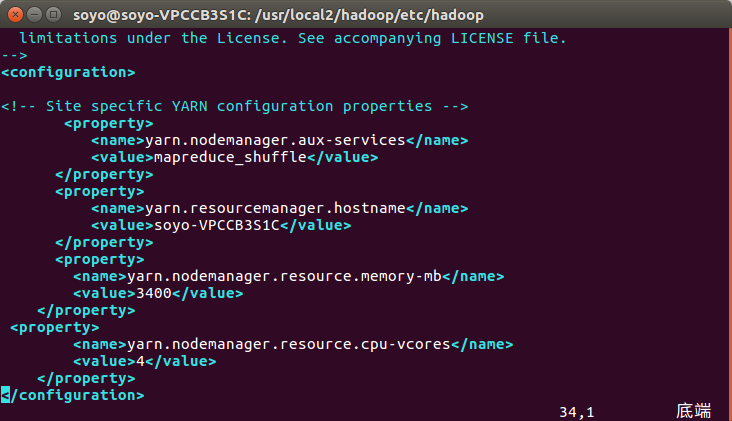
这里如果不配置:
<name>yarn.nodemanager.resource.memory-mb</name>
<name>yarn.nodemanager.resource.cpu-vcores</name>
soyo-slave01上的NodeManager无法启动
memory-mb(可用内存大小) value:参照Linux分类的总结--> http://www.cnblogs.com/soyo/p/7908430.html
cpu-vcores (CPU核数) value:参照Linux分类的总结--> http://www.cnblogs.com/soyo/p/7908365.html
5.给节点分发Hadoop配置:
当前路径为:/usr/local2
tar -zcf ~/hadoop.tar.gz ./hadoop
(如果Hadoop之前被使用过最好删除 temp 和logs 再分发,每次删除这两个文件后,启动Hadoop前都需要执行:hdfs namenode -format 不然namenode会无法启动,这个下面有讲)
cd /home/soyo
scp ./hadoop.tar.gz soyo-slave01:/home/soyo (这里节点写成:soyo@soyo-slave01:/home/soyo 也可以)
在soyo-slave01节点上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local2
sudo chmod -R 777 hadoop
6.启动Hadoop集群:
任意路径下执行:
hdfs namenode -format
start-all.sh
(想要在任意路径下可以启动Hadoop 需要配置:bashrc)
vim ~/.bashrc:
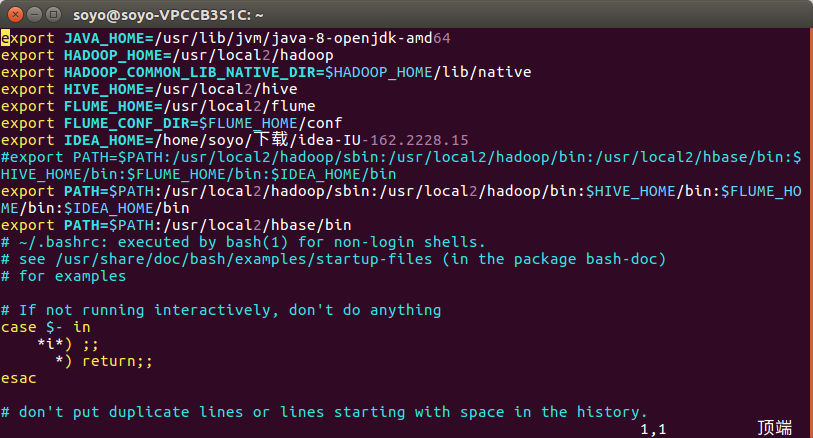
source ~/.bashrc
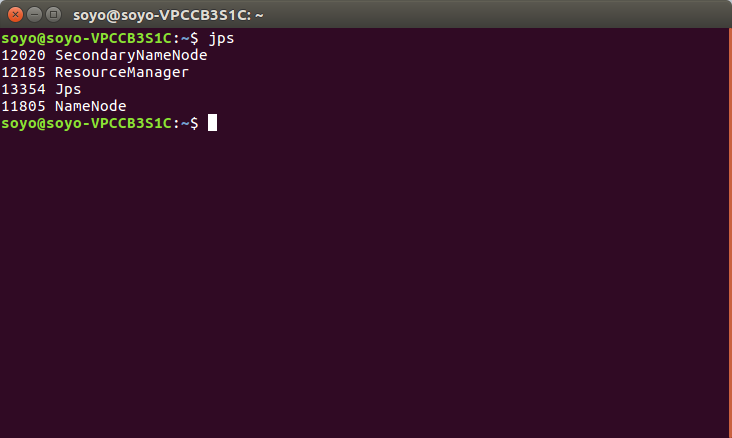
7.查看Hadoop分布式是否搭建成功:
在master节点:jps
在 slave节点上:jps
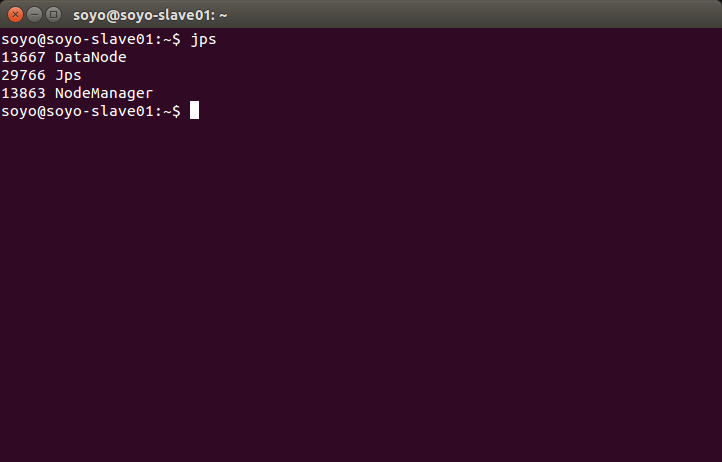
要保证master,slave 的shell中的进程都被启动(少一个都表示没有配置成功)
8.分布式计算:
首先创建 HDFS 上的数据存放目录
hdfs dfs -mkdir -P /user/soyo
往HDFS中导入数据:
hdfs dfs -put /usr/local2/hadoop/etc/hadoop/*.xml /user/soyo
执行:
hadoop jar /usr/local2/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar grep /user/soyo /user/soyo_output 'dfs[a-z.]+'

可以通过WEB页面查看HDFS上存储的数据以及计算的结果文件:soyo-VPCCB3S1C:50070 (直接浏览器输入这个网址)
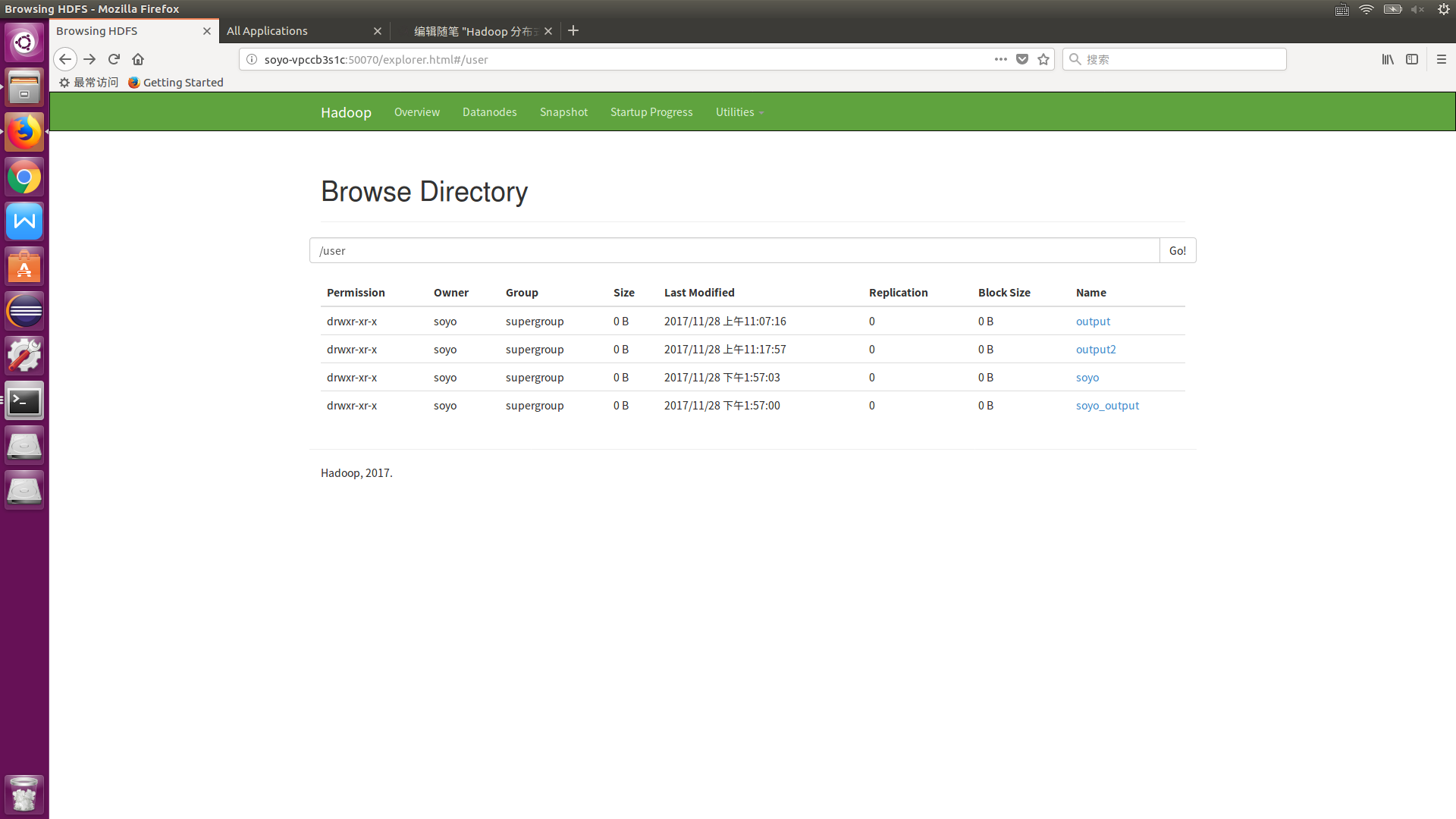
同样可以通过 Web 界面查看任务进度:soyo-VPCCB3S1C:8088 (直接浏览器输入这个网址) 如何yarn资源管理器启动失败这个网页是打不开的
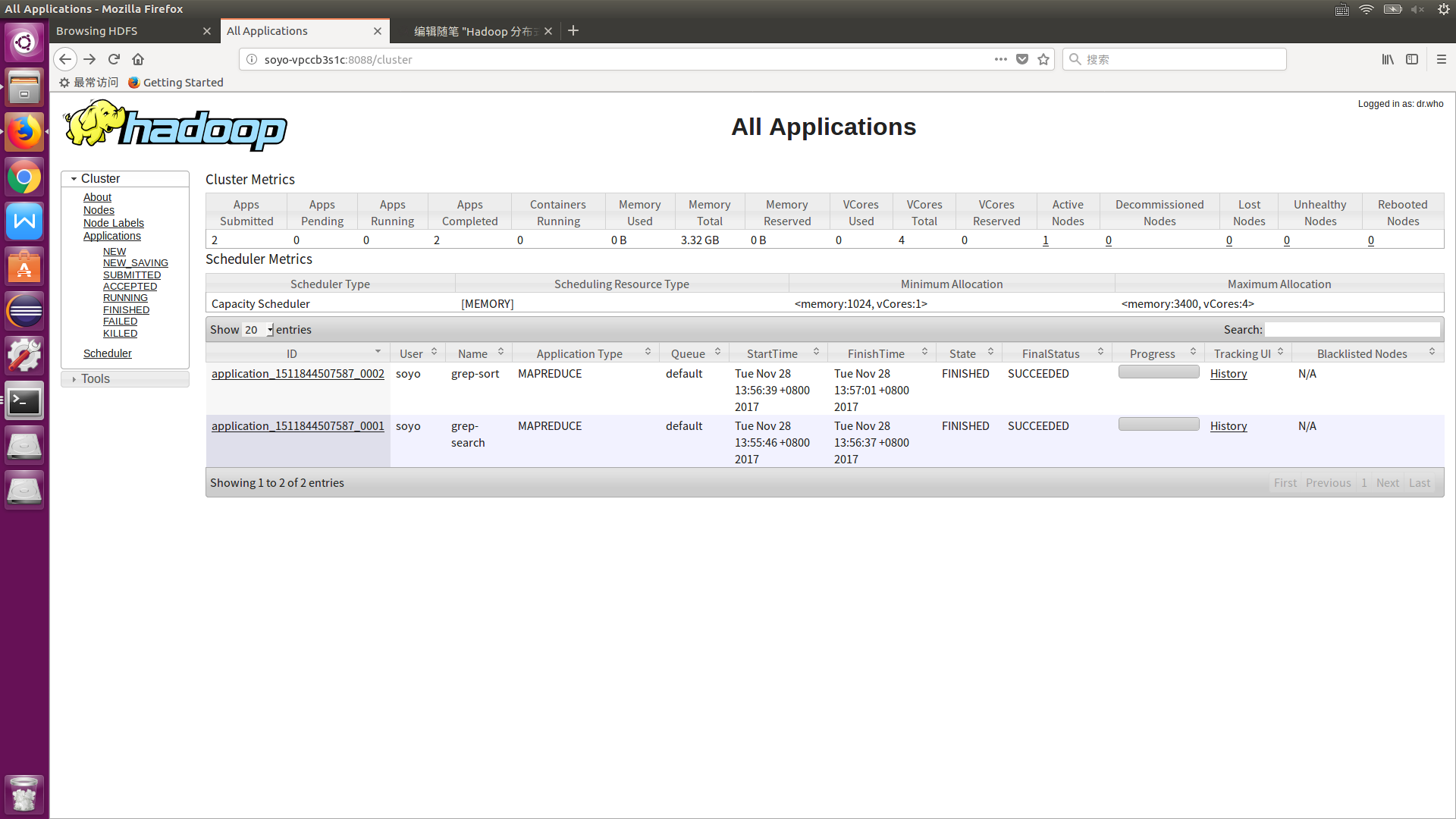
9.把计算结果保存到本地:
hdfs dfs -get /user/soyo_output /home/soyo
10.DataNode 节点负责保存HDFS上的 数据,那实质的计算过程也是由它做吗?(很无奈啊......图片是反的)
DataNode:
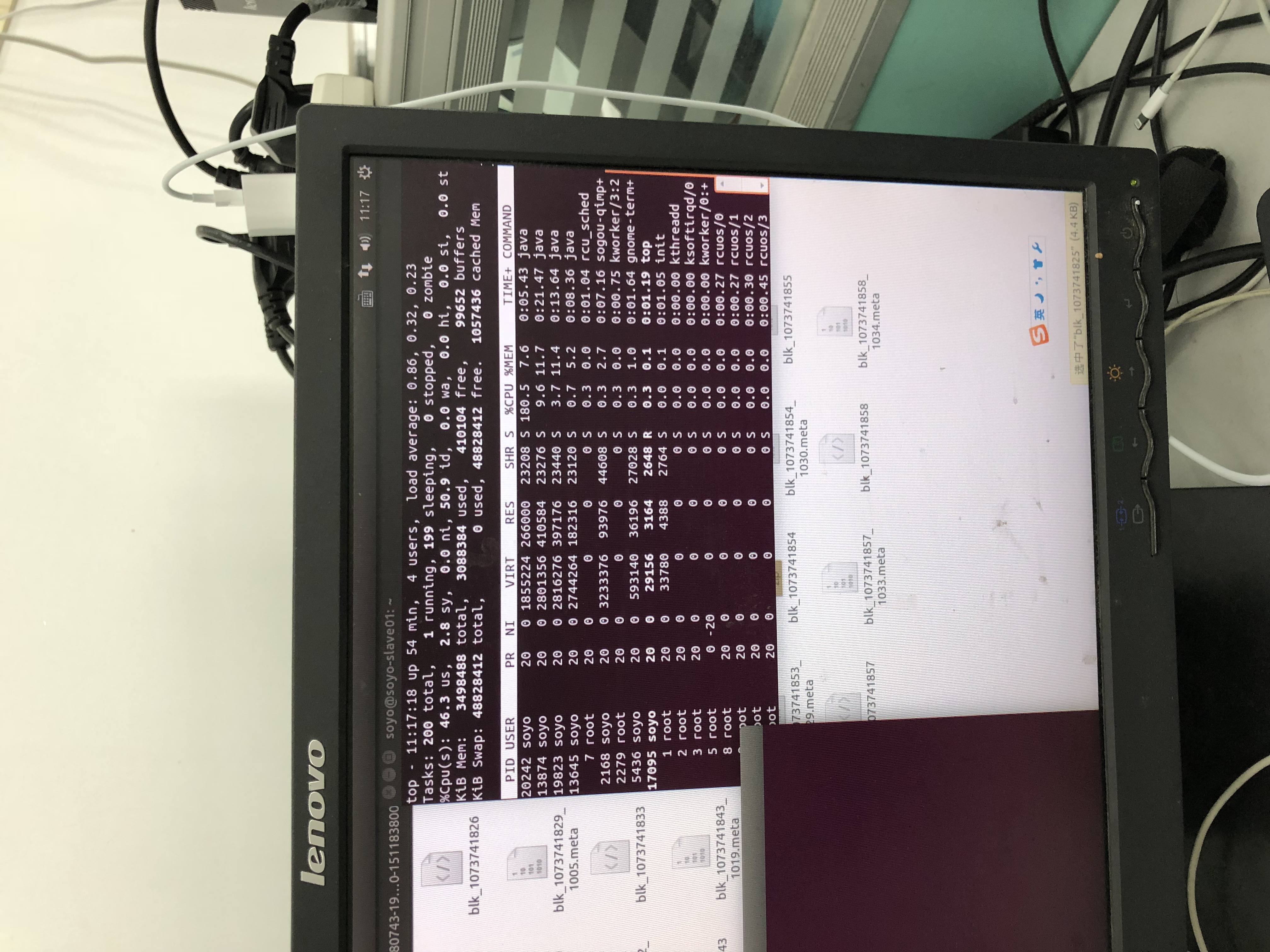
NameNode:

可以看出计算的过程也是由DataNode来承担的