资料链接:
1、《Redis设计与实现》http://redisbook.com/
2、《Redis设计与实现解读版》https://www.cnblogs.com/monxue/p/3961380.html
3、《Redis源码中文注释版(v3.0)》https://github.com/huangz1990/redis-3.0-annotated
4、《吃透了这些Redis知识点,面试官一定觉得你很NB(干货 | 建议珍藏)》https://www.cnblogs.com/lixinjie/p/a-key-point-of-redis-in-interview.html
5、《Redis服务器原理》https://blog.csdn.net/linkedin_38454662/article/details/76152219
redis中几个知识点和设计思想:
1、redis使用的数据结构(5种):字符串、哈希表、列表、集合、有序集
“没有完美的数据结构设计,只有适合的使用场景”---在每种数据类型下面,redis在实际使用的时候都会因地制宜,不同场景下采用不同的具体实现
(比如:有序集中分为ziplist、skiplist&dict两种实现;Hash的内部结构包含ziplist和hash两种)
Redis对象底层数据结构共八种:
编码常量 编码所对应的底层数据结构
REDIS_ENCODING_INT(long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
2、redis持久化的两种方式:rdb和aof
rdb:每次全量保存数据库快照到dump.rdb文件中。优点是全量数据,恢复速度快;缺点是较耗费资源;
aof:redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。优点是持久性强、可追加以及易parse;缺点是文件较大些;
3、柔性数组
在sds的结构实现中,采用了柔性数组。
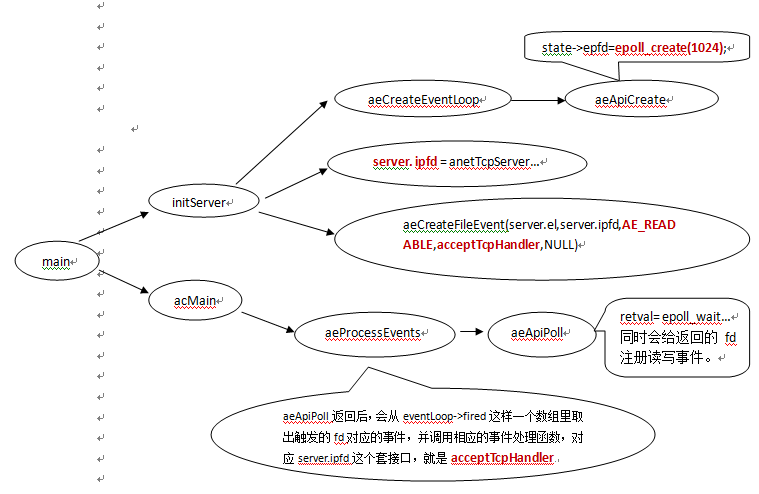
4、IO多路复用的选择
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
Redis 会优先选择时间复杂度为 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 ,并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
例如,redis在linux系统环境下编译时,通过gcc预置的宏定义(__linux__)来定义HAVE_EPOLL,从而控制aeProccessEvents方法中的aeApiPoll采用EPOLL模型实现。