1、导入模块配置中文
import pandas as pd import numpy as np from matplotlib import pyplot as plt # 支持中文 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
2、从csv中读取爬取得数据
采集代码:https://github.com/song-zhixue/lagou
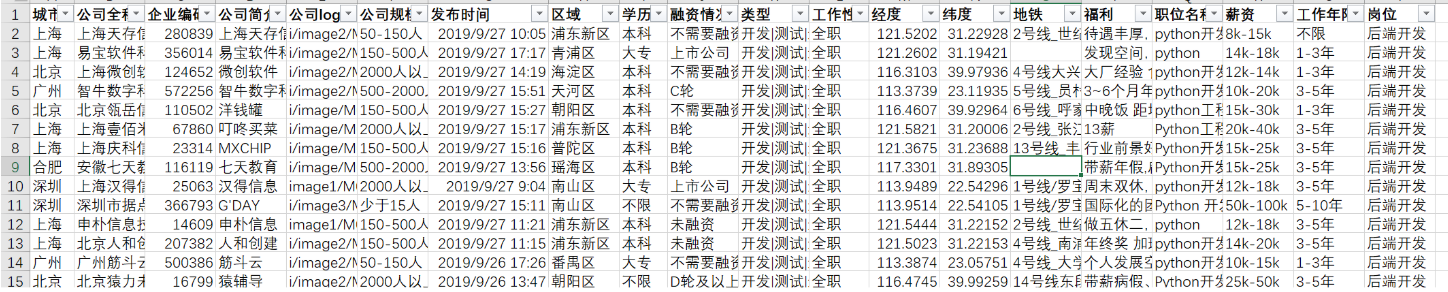
data = pd.read_csv("./lagou_data.csv",sep = ',',encoding = 'gbk') data.head()
3、进行数据清洗
这里我只做了简单得清洗就是去掉空值
- 去重 - 去空 - 1删除 - 2替换 - 3填充 - 去异常 - 1非法数据 比如本来应该是数字列的中间夹杂着一些汉字或者是符号 - 2异常数据 异乎寻常的大数值或者是小数值
data.isnull() data.isnull().any() # 按照列统计空值,查看哪一列有空值
城市 False 公司全称 False 企业编码 False 公司简介 False 公司logo False 公司规模 False 发布时间 False 区域 True 学历 False 融资情况 False 类型 False 工作性质 False 经度 True 纬度 True 地铁 True 福利 False 职位名称 False 薪资 False 工作年限 False 岗位 False dtype: bool
data = data.dropna() # 默认会删除包含缺失值的行 data
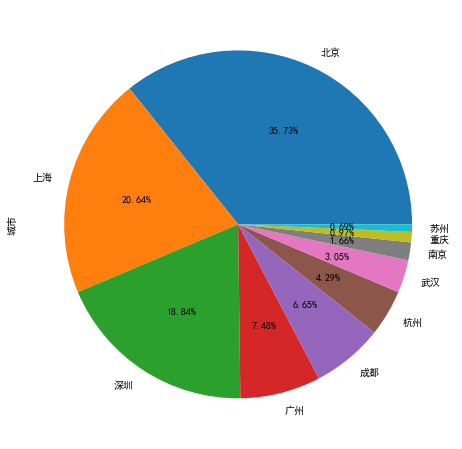
4、根据城市招聘情况绘制饼图TOP10
data["城市"].value_counts() 北京 258 上海 149 深圳 136 广州 54 成都 48 杭州 31 武汉 22 南京 12 重庆 7 苏州 5 天津 4 石家庄 3 长沙 3 厦门 3 西安 2 郑州 2 青岛 2 大连 2 佛山 2 长春 1 贵阳 1 Name: 城市, dtype: int64
ret = data["城市"].value_counts().head(10).plot(kind='pie',autopct='%1.2f%%',figsize=(10,8)) # 取前10个结果进行绘图 ret plt.show
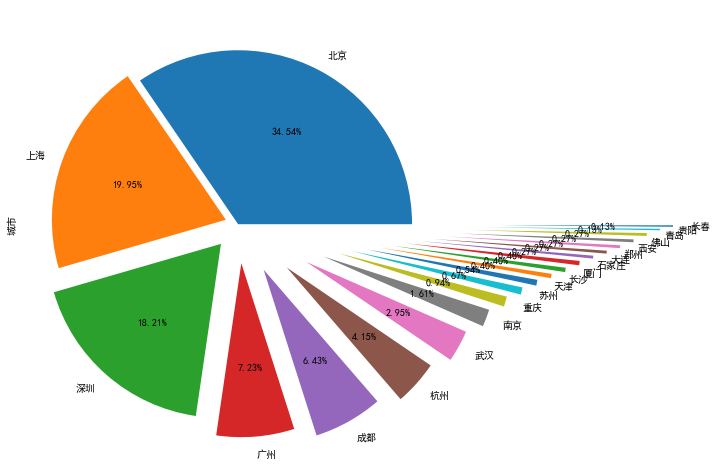
ret = data["城市"].value_counts().plot(kind='pie',autopct='%1.2f%%',figsize=(10,8),explode = np.linspace(0,1.5,21)) # 每隔1.5个长度绘制一次,一共21条数据 ret plt.show
5、根据学历绘制柱状图
data["学历"].value_counts() 本科 613 大专 73 不限 50 硕士 11 Name: 学历, dtype: int64 data["学历"].value_counts().plot(kind='bar') plt.xticks(rotation=0)

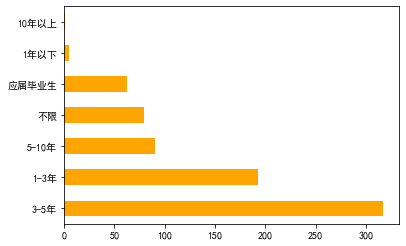
6、根据工作经验绘制条形图
data["工作年限"].value_counts() 3-5年 317 1-3年 193 5-10年 90 不限 79 应届毕业生 62 1年以下 5 10年以上 1 Name: 工作年限, dtype: int64 data["工作年限"].value_counts().plot(kind='barh',color="orange")
7、根据公司规模绘制饼图和条形图
data["公司规模"].value_counts() 150-500人 190 50-150人 181 15-50人 130 2000人以上 112 500-2000人 100 少于15人 34 Name: 公司规模, dtype: int64 data["公司规模"].value_counts().plot(kind='pie',autopct='%1.2f%%')
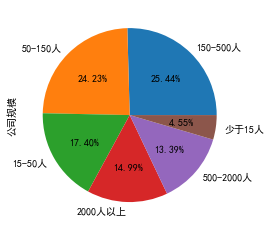
data["公司规模"].value_counts().plot(kind='barh',color="red")

8、根据融资情况绘制条形图
data["融资情况"].value_counts() 不需要融资 187 A轮 118 B轮 114 上市公司 96 未融资 88 天使轮 55 C轮 54 D轮及以上 35 Name: 融资情况, dtype: int64 data["融资情况"].value_counts().plot(kind='bar') plt.xticks(rotation=45)
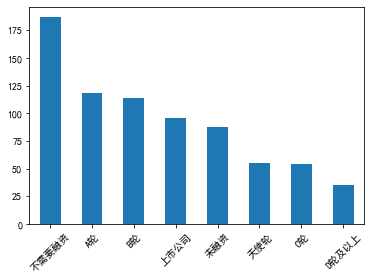
9、根据福利待遇绘制词云
# 利用结巴进行分词 import jieba # 绘制词云 import wordcloud # 自定义词云背景 from PIL import Image data["福利"] all_str = '' for i in data["福利"]: all_str += i # 利用jieba进行分词 lis = jieba.lcut(all_str) txt = " ".join(lis) # mask = np.array(Image.open("./词云.jpg")) # 自定义背景图 w = wordcloud.WordCloud( font_path="msyh.ttc", width=400, height=400, background_color="white", # colormap="Reds", # mask=mask, # contour_width=1, # contour_color="red" ) w.generate(txt) w.recolor() # 随机词云中的字体颜色 # w.to_file("福利.png") # 将词云保存在本地 w.to_image() # 查看生成的词云

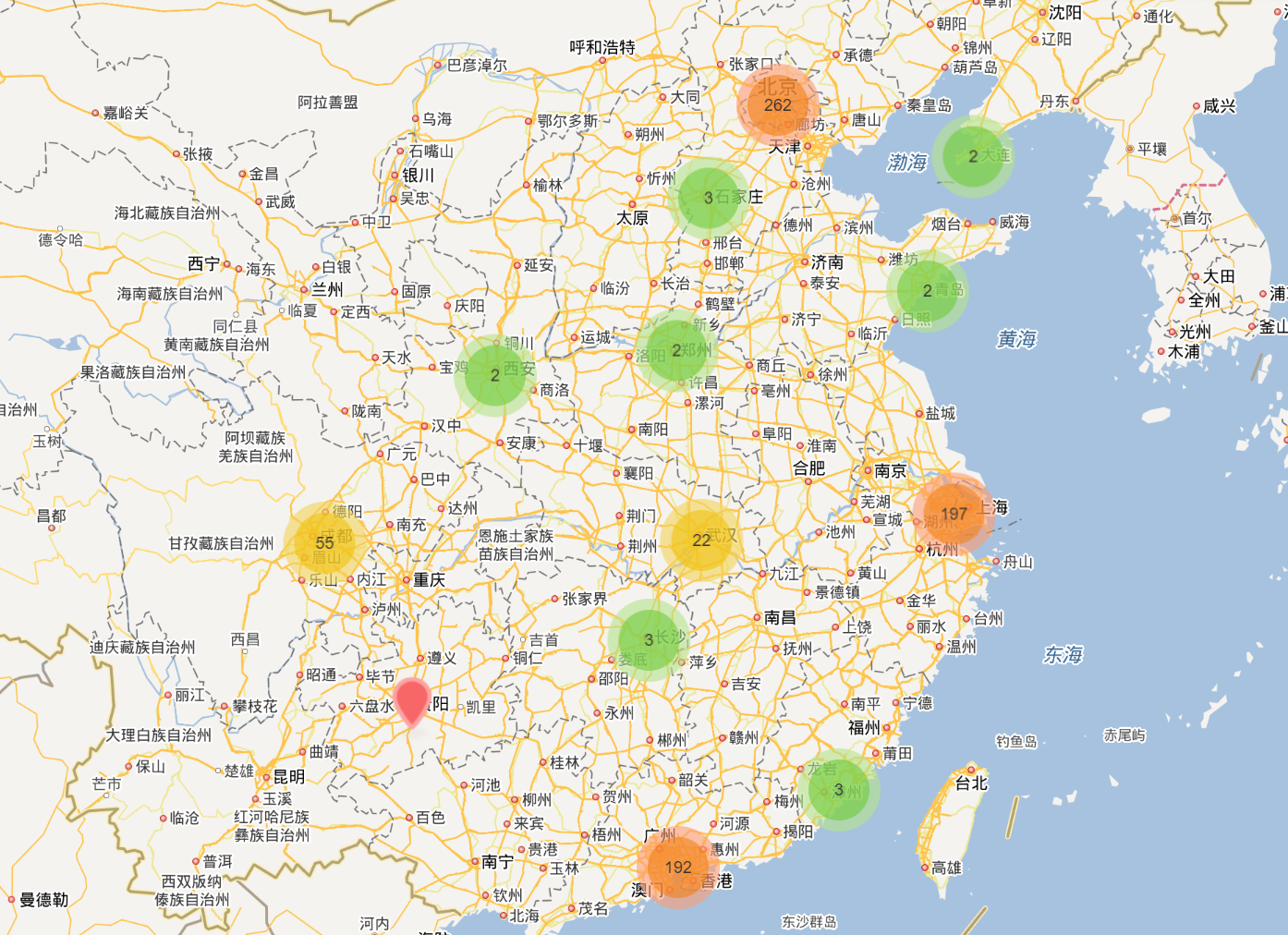
10、地图可视化
利用地图无忧进行地图可视化:https://www.dituwuyou.com/
data[["经度","纬度"]] # 取经度和纬度这两列数据
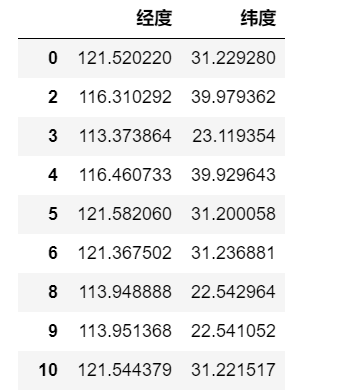
data[["经度","纬度"]].to_csv("./地图经纬度.csv",encoding="gbk") # 导出csv用地图无忧绘制地图
导出到csv样式
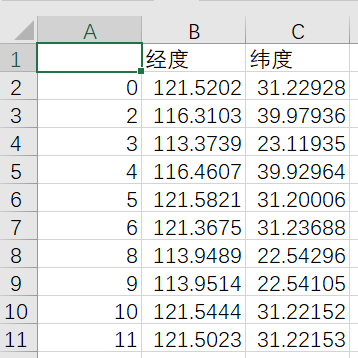
- https://www.dituwuyou.com/orgs/321267/maps - 账号:xxxxxx - 密码:xxxxxx

11、薪资统计
我们获得的数据都是以字符串形式存储的,而且像工资(20k—30k)都是以区间的形式表现出来的,应该求其平均值(工资25k)
原数据:
data["薪资"].value_counts() 15k-30k 71 15k-25k 68 10k-20k 58 20k-40k 49 20k-30k 32 10k-15k 30 25k-50k 24 8k-15k 22 20k-35k 20 10k-18k 16 12k-20k 16 8k-12k 15 15k-20k 13 12k-18k 13 25k-40k 12 6k-12k 11 25k-35k 9 12k-24k 9 30k-50k 9
清洗后的数据
# 统计每个公司给出的平均工资 pattern = 'd+' # 正则表达式-匹配连续数字 data['平均工资']= data["薪资"].str.findall(pattern) avg_salary = [] for k in data['平均工资']: salary_list = [int(n) for n in k] salary = sum(salary_list)/2 avg_salary.append(salary) data['平均工资'] = avg_salary # 新创建一列平均工资 data['平均工资'] 0 11.5 2 13.0 3 15.0 4 22.5 5 30.0 6 20.0 8 15.0 9 75.0 10 15.0 11 17.0 12 12.5 13 37.5 14 11.5 15 12.0 16 12.5 17 22.5 19 25.0
根据平均薪资绘制频数直方图
# 平均工资直方图 plt.figure(figsize=(15,5),dpi=80) plt.hist(data['平均工资'], alpha=0.8, color='steelblue') plt.xlabel('工资/千元') plt.ylabel('频数') plt.title("python工程师平均工资直方图") plt.show()
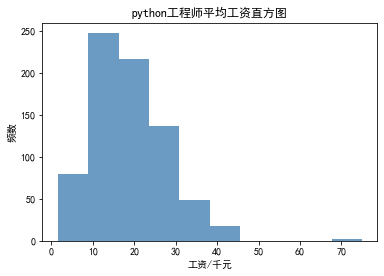
可以看出python的薪资范围在10k-15k比较多