在这里添加一个slave,真的有一个很好的可扩展性的策略,这基本上足以满足大多数现代应用程序。使用一台服务器的情况下,许多应用程序就会完美地运行,您可能想添加以副本以给基础设施增加一些安全,但在许多情况下,这是许多人想要的。
如果您的应用程序变得越来越大,可以在很多情况下,您可以添加slave和向外扩展读;这也不是什么大问题,并可以很容易地完成。如果您要添加更多的slave,您可能需要级联复制您您的基础设施,但对于98%的应用程序来说,目前为止,这就够了。
其余2%的应用程序由PL/Proxy来解决。PL/Proxy的思想是要能向外扩展写入。请记住,基于事务日志的复制只能向外扩展读,没有办法扩展写入。
[如果您想扩展写入,请使用PL/Proxy。]
13.1 理解基本概念
正如我们以之前所提到的,PL/Proxy背后的思想是像向外扩展读取一样来扩展写入,读取扩展可以使用我们在本书中之前列出的技术很容易地做到。
现在的问题是:您怎么向外扩展写?要做到这一点,我们必须要遵循一个老的罗马原则,它已经被广泛应用于战争:分而治之(英文:Divide and conquer)。一旦您成功地把一个问题拆分成多个小问题,您总是站在胜利的一边。
把该原则应用到数据库的工作意味着我们必须拆分写入并把它们分散到许多不同的服务器上。这里主要的艺术是如何明智地分割数据。
作为一个例子,我们简单地假设我们要拆分用户数据。让我们进一步假设,每个用户有一个用户名来标识他/她自己。
现在,我们 如何拆分数据呢?在这一点上,许多人将建议按字母顺序拆分数据。比方说,从A到M发到服务器1,所有剩下的发到服务器2.这实际上是一个糟糕的想法,因为我们永远不能假设数据是均匀分布的。一些名字可能只是比另外一些名字更相似,所以,如果您按字母来拆分,您永远不会使每个分区的数据的数量大致相同(这是非常期望的)。但是,我们一定要确保每台 服务器都有大致相同的数据量,我们要找到一种方法来扩展集群到更多的服务器。但是,让我们稍后讨论一下有用的分区函数。
13.1.1 考虑全局
在我们看一个真实的设置和如何对数据进行分区之前,我们必须讨论全局处理:从技术上讲,PL/Proxy是一种存储过程语言,它仅仅包括五个命令。这种语言的唯一目的是调度请求到集群内部的服务器。
让我们看看下面的图片:
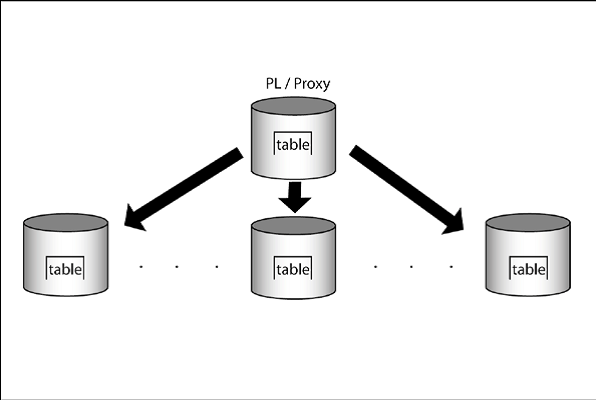
我们拿到PL/Proxy并把它安装到一个服务器,这将作为我们的系统代理。每当我们做一个查询,我们要求代理给我们提供数据。代理将询问它的规则并找出查询要重定向到哪台服务器。基本上,PL/Proxy是一种分片的数据库实例。
[向代理请求数据的方法是调用了一个存储过程。由于写这本书的时候,没有办法真正创建一个虚拟的 表分发到多台服务器。您必须要使用过程调用。]
所以,如果您发出一个查询,PL/Proxy将尝试隐藏大量的复杂性,并只是为您提供数据,无论是来自哪里。
13.1.2 分区数据
正如我们刚才看到的,基本上,PL/Proxy就是一种分发数据到多个节点的方法。现在核心的问题是:我们如何以一种明智的,合乎情理的方法来拆分并分区数据?在本书中,我们已经解释过,按字母拆分可能不是所有想法中最好的一种,因为数据 不会被均匀分布。
当然,有很多方法来拆分数据。在本节中,我们将看一个简单而有效的方法,它可以适用于许多不同的场景。让我们假设,在这个例子中,我们要拆分数据并将其存储到16台服务器的阵列中。16是一个不错的数字,因为16是2的幂。在计算机科学中,2的幂通常是很好的数字,同样也适用于PL/Proxy。
均匀分配的数据的关键取决于第一次把您的文本值转换为一个整数:
test=# SELECT 'www.postgresql-support.de';
?column?
---------------------------
www.postgresql-support.de
(1 row)
test=# SELECT hashtext('www.postgresql-support.de');
hashtext
-------------
-1865729388
(1 row)
我们可以使用一个PostgreSQL内置的函数(不涉及PL/Proxy)来对文本进行哈希。它会给我们一个均匀分布的数字。因此,如果我们哈希一百万条数据,我们将看到均匀分布的哈希键。这是很重要的,我们可以把数据拆分成类似的块。
现在,我们可以拿到这个整数值,并只保留低四位 :
test=# SELECT hashtext('www.postgresql-support.de')::bit(4);
hashtext
----------
0100
(1 row)
test=# SELECT hashtext('www.postgresql-support.de')::bit(4)::int4;
hashtext
----------
4
(1 row)
最后四位是0100,它被转换回为整数。这回意味着该行应该存储到第五个节点上(如果我们从0开始计数)
使用哈希键是迄今为止最简单的拆分数据的方法。它有一些很不错的优点:如果您想增大您的集群的大小,您可以很容易地只再添加一位,而无需在集群中重新平衡数据。
当然,您总是可以拿出更复杂和精密的规则来分发数据。