数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
数据仓库概念是Inmon于1990年提出并给出了完整的建设方法。随着互联网时代来临,数据量暴增,开始使用大数据工具来替代经典数仓中的传统工具。此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构。
后来随着业务实时性要求的不断提高,人们开始在离线大数据架构基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是Lambda架构。
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的Kappa架构。

数据仓库模型架构

数据仓库的建设主要包括数据的采集、数据的处理、数据归档、数据应用四个方面。
当前主要的应用场景包括报表展示、即席查询、BI展示、数据分析、数据挖掘、模型训练等方面。
数据仓库的建设是面向主题的、集成性的、不可更新的、时许变化的。
实时与离线
离线数据仓库主要基于sqoop、hive等技术来构建T+1的离线数据,通过定时任务每天拉取增量数据导入到hive表中,然后创建各个业务相关的主题维度数据,对外提供T+1的数据查询接口。
实时数仓当前主要是基于数据采集工具,如canal等将原始数据写入到Kafka这样的数据通道中,最后一般都是写入到类似于HBase这样存储系统中,对外提供分钟级别、甚至秒级别的查询方案。
数仓类型 |准确性 | 实时性 | 稳定性
----------| ---------| ------------------------------------
离线数仓 |准确度高 |时延一般在一天 |稳定性好,方便重算
实时数仓 |准确度底,数据延迟、数据乱序造成数据准确度低|分钟级延迟|稳定性查,需要考虑数据回溯处理
实时数仓的的实施关键点
端到端数据延迟、数据流量的监控
故障的快速恢复能力
数据的回溯处理,系统支持消费指定时间端内的数据
实时数据从实时数仓中查询,T+1数据借助离线通道修正
数据地图、数据血缘关系的梳理
业务数据质量的实时监控,初期可以根据规则的方式来识别质量状况
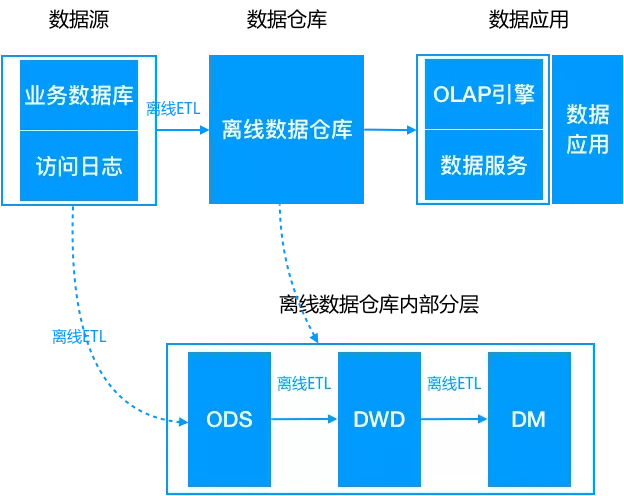
离线大数据架构
数据源通过离线的方式导入到离线数仓中。下游应用根据业务需求选择直接读取 DM 或加一层数据服务,比如 MySQL 或 Redis。数据仓库从模型层面分为三层:
1.ODS,操作数据层,保存原始数据;
2.DWD,数据仓库明细层,根据主题定义好事实与维度表,保存最细粒度的事实数据;
3.DM,数据集市/轻度汇总层,在 DWD 层的基础之上根据不同的业务需求做轻度汇总;
典型的数仓存储是 HDFS/Hive,ETL 可以是 MapReduce 脚本或 HiveSQL。
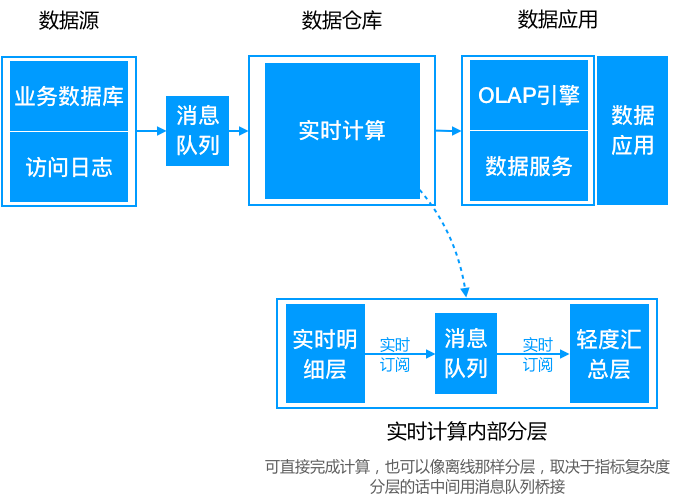
Lambda 架构
随着大数据应用的发展,人们逐渐对系统的实时性提出了要求,为了计算一些实时指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。
Lambda 架构问题:
- 同样的需求需要开发两套一样的代码:这是 Lambda 架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,一个在批处理引擎上实现,一个在流处理引擎上实现,还要分别构造数据测试保证两者结果一致),后期维护更加困难,比如需求变更后需要分别更改两套代码,独立测试结果,且两个作业需要同步上线。
- 资源占用增多:同样的逻辑计算两次,整体资源占用会增多(多出实时计算这部分)

Kappa 架构
Lambda 架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。后来随着 Flink 等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题,LickedIn 的 Jay Kreps 提出了 Kappa 架构。
1.Kappa 架构可以认为是 Lambda 架构的简化版(只要移除 lambda 架构中的批处理部分即可)。
2.在 Kappa 架构中,需求修改或历史数据重新处理都通过上游重放完成。
3.Kappa 架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
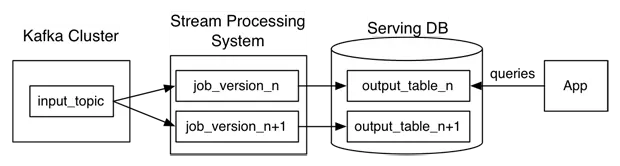
Kappa架构的重新处理过程
重新处理是人们对Kappa架构最担心的点,但实际上并不复杂:
1.选择一个具有重放功能的、能够保存历史数据并支持多消费者的消息队列,根据需求设置历史数据保存的时长,比如Kafka,可以保存全部历史数据。
2.当某个或某些指标有重新处理的需求时,按照新逻辑写一个新作业,然后从上游消息队列的最开始重新消费,把结果写到一个新的下游表中。
3.当新作业赶上进度后,应用切换数据源,读取2中产生的新结果表。
4.停止老的作业,删除老的结果表。
Lambda架构与Kappa架构的对比
| 对比项 | Lambda架构 | Kappa架构 |
|---|---|---|
| 实时性 | 实时 | 实时 |
| 计算资源 | 批和流同时运行,资源开销大 | 只有流处理,仅针对新需求开发阶段运行两个作业,资源开销小 |
| 重新计算时吞吐 | 批式全量处理,吞吐较高 | 流式全量处理,吞吐较批处理低 |
| 开发、测试 | 每个需求都需要两套不同代码,开发、测试、上线难度较大 | 只需实现一套代码,开发、测试、上线难度相对较小 |
| 运维成本 | 维护两套系统(引擎),运维成本大 | 只需维护一套系统(引擎),运维成本小 |
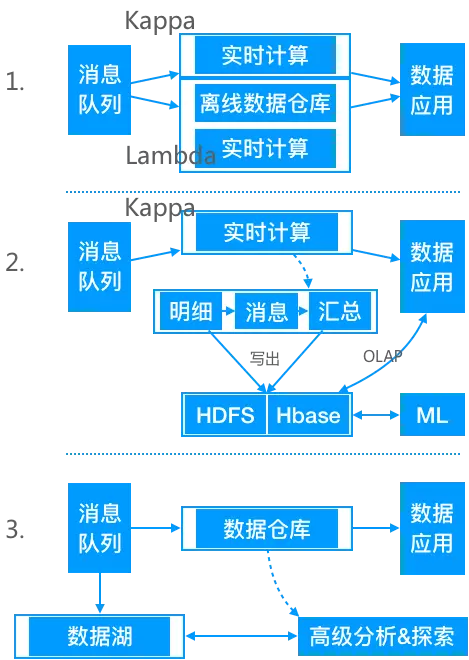
在真实的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金额相关)使用Lambda架构用批处理重新计算,增加一次校对过程。
Kappa架构并不是中间结果完全不落地,现在很多大数据系统都需要支持机器学习(离线训练),所以实时中间结果需要落地对应的存储引擎供机器学习使用,另外有时候还需要对明细数据查询,这种场景也需要把实时明细层写出到对应的引擎中。
另外,随着数据多样性的发展,数据仓库这种提前规定schema的模式显得越来难以支持灵活的探索&分析需求,这时候便出现了一种数据湖技术,即把原始数据全部缓存到某个大数据存储上,后续分析时再根据需求去解析原始数据。简单的说,数据仓库模式是schema on write,数据湖模式是schema on read。
实时数仓与离线数仓在几方面的对比:
首先,从架构上,实时数仓与离线数仓有比较明显的区别,实时数仓以 Kappa 架构为主,而离线数仓以传统大数据架构为主。Lambda 架构可以认为是两者的中间态。
其次,从建设方法上,实时数仓和离线数仓基本还是沿用传统的数仓主题建模理论,产出事实宽表。另外实时数仓中实时流数据的 join 有隐藏时间语义,在建设中需注意。
最后,从数据保障看,实时数仓因为要保证实时性,所以对数据量的变化较为敏感。在大促等场景下需要提前做好压测和主备保障工作,这是与离线数据的一个较为明显的区别。