1 背景
用户本地有一份txt或者csv文件,无论是从业务数据库导出、还是其他途径获取,当需要使用蚂蚁的大数据分析工具进行数据加工、挖掘和共创应用的时候,首先要将本地文件上传至ODPS,普通的小文件通过浏览器上传至服务器,做一层中转便可以实现,但当这份文件非常大到了10GB级别,我们就需要思考另一种形式的技术方案了,也就是本文要阐述的方案。
技术要求主要有以下几方面:
支持超大数据量、10G级别以上
稳定性:除网络异常情况100%成功
准确性:数据无丢失,读写准确性100%
效率:1G文件分钟级、10G文件小时级
体验:实时进度感知、网络异常断点续传、定制字符特殊处理
2 文件上传选型
文件上传至ODPS基本思路是先文件上传至某中转区域存储,然后同步至ODPS,根据存储介质可以分为两类,一类是应用服务器磁盘,另一类类是中间介质,OSS作为阿里云推荐的海量、安全低成本云存储服务,并且有丰富的API支持,成为中间介质的首选。而文件上传至OSS又分为web直传和sdk上传两种方案,因此上传方案有如下三种,详细优缺点对比如下:

蚂蚁的文本上传功能演进过程中对第一种、第二种方案均有实践,缺点比较明显,如上表所述,不满足业务需求,因此大文件上传终极方案是方案三。
3 整体方案
以下是方案三的整体过程示意图。
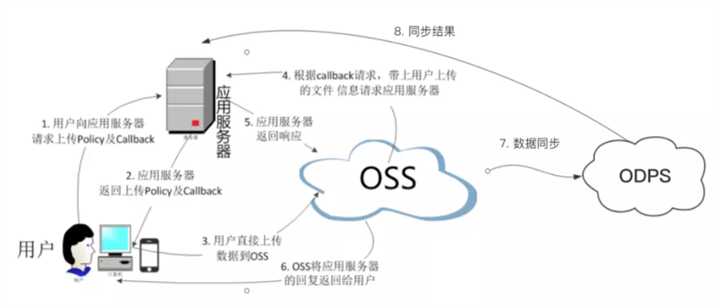
请求步骤如下:
用户向应用服务器取到上传policy和回调设置。
应用服务器返回上传policy和回调。
用户直接向OSS发送文件上传请求。
等文件数据上传完,OSS给用户Response前,OSS会根据用户的回调设置,请求用户的服务器。如果应用服务器返回成功,那么就返回用户成功,如果应用服务器返回失败,那么OSS也返回给用户失败。这样确保了用户上传成功,应用服务器已经收到通知了。应用服务器给OSS返回。
OSS将应用服务器返回的内容返回给用户。
启动后台同步引擎执行oss到odps的数据同步。
同步实时进度返回返回给应用服务器,同时展示给用户。
4 技术方案
4.1 上传
OSS提供了丰富的SDK,有简单上传、表单上传、断点续传等等,对于超大文件提供的上传功能建议采用断点续传方式,优点是可以对大文件并行分片上传,利用OSS的并行处理能力,中间暂停也可以从当前位置继续上传,网络环境影响可以降到最低。
4.2 下载
OSS文件下载同样也有多种方式,普通下载、流式下载、断点续传下载、范围下载等等,若直接下载到本地同样建议断点续传下载,但我们的需求并不仅仅是下载文件本地存储,而是读取文件做数据从OSS到ODPS的同步,因此不做中间存储,直接边读变写,一方面采用OSS流式读取,一方面ODPS tunnel上传,用多线程读写方式提高同步速率。
4.3 两阶段数据转移
文件从本地到ODPS可以分为两个阶段,第一阶段前端分片断点续传将本地文件上传至OSS,第二阶段后端流式读写将数据从OSS同步至ODPS,如下图所示:
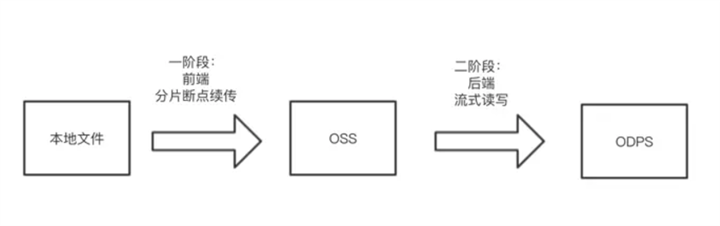
涉及技术点:
4.3.1 前端,js sdk带STS token 安全上传
在需要上传的文件较大时,可以通过multipartUpload接口进行分片上传。分片上传的好处是将一个大请求分成多个小请求来执行,这样当其中一些请求失败后,不需要重新上传整个文件,而只需要上传失败的分片就可以了。一般对于大于100MB的文件,建议采用分片上传的方法,每次进行分片上传都建议重新new一个新的OSS实例。
阿里云分片上传流程主要会调用3个api,包含
InitiateMultipartUpload, 分片任务初始化接口。
UploadPart, 单独的分片上传接口。
CompleteMultipartUpload, 分片上传完成后任务完成接口
临时访问凭证是通过阿里云Security Token Service(STS)来实现授权的一种方式。其实现请参见STS Java SDK。临时访问凭证的流程如下:
客户端向服务器端发起获得授权的请求。服务器端先验证客户端的合法性。如果是合法客户端,那么服务器端会使用自己的AccessKey来向STS发起一个请求授权的请求,具体可以参考访问控制。
服务器端获取临时凭证之后返回给客户端。
客户端使用获取的临时凭证来发起向OSS的上传请求,更详细的请求构造可以参考临时授权访问。客户端可以缓存该凭证用来上传,直到凭证失效再向服务器端请求新的凭证。
4.3.2 后端,多线程流式读写
OSS端:如果要下载的文件太大,或者一次性下载耗时太长,可以多线程流式下载,一次处理部分内容,直到完成文件的下载。
ODPS端:tunnel sdk对OSS流式数据直接写入,一次完整的数据写入流程通常包括以下步骤:
先对数据进行划分;
为每个数据块指定 block id,即调用 openRecordWriter(id);
然后用一个或多个线程分别将这些 block 上传上去, 并在某个 block 上传失败以后,需要对整个 block 进行重传;
在所有 block 都上传以后,向服务端提供上传成功的 blockid list 进行校验,即调用 session.commit([1,2,3,…])
而由于服务端对block管理,连接超时等的一些限制,上传过程逻辑变得比较复杂,为了简化上传过程,SDK提供了更高级的一种RecordWriter——TunnelBufferWriter。
5 实现过程及压测
太多了,可以参考我写的这篇文章:http://blog.ncmem.com/wordpress/2019/08/09/%e5%a4%a7%e6%96%87%e4%bb%b6%e4%b8%8a%e4%bc%a0%e8%a7%a3%e5%86%b3%e6%96%b9%e6%a1%88/
6 总结
实测结果显示,本文的上传方案实现了第一节提出的几点技术要求,如下:
支持超大数据量、10G级别以上没有任何压力,主要是前端在分片上传设置好分片限额即可(最大10000片,每片最大100G),目前设置每片1M满足10G需求。
稳定性:实测观察网络异常情况较少,文件内容正常情况下100%成功。
准确性:实测数据无丢失,读写准确性100%。
效率:办公网带宽1.5M/s的情况下1G文件分钟级、10G文件小时级,实际速度视用户端的当前网络带宽变化。
体验:实时进度感知、网络异常断点续传、定制字符特殊处理等高级功能可以提升用户体验。