读写分离优化了互联网读多写少场景下的性能问题,考虑一个业务场景,如果读库的数据规模非常大,除了增加多个从库之外,还有其他的手段吗?实现数据库高可用,还有另外一个撒手锏,就是分库分表。
为什么要分库分表
一般Mysql一个单库最多支持并发量到2000,且最好保持在1000。如果有20000并发量的需求,这时就需要扩容了,可以将一个库的数据拆分到多个库中,访问的时候根据一定条件访问单库,缓解单库的性能压力。
分表也是一样的,如果单表的数据量太大,就会影响SQL语句的执行性能。分表就是按照一定的策略将单表的数据拆分到多个表中,查询的时候也按照一定的策略去查询对应的表,这样就将一次查询的数据范围缩小了。比如按照用户id来分表,将一个用户的数据就放在一个表中,crud先通过用户id找到那个表在进行操作就可以了。这样就把每个表的数据量控制在一定范围内,提升SQL语句的执行性能。
分库分表原理
分库分表,顾名思义,就是将原本存储于单个数据库上的数据拆分到多个数据库,把原来存储在单张数据表的数据拆分到多张数据表中,实现数据切分,从而提升数据库操作性能。分库分表的实现可以分为两种方式:垂直切分和水平切分。
垂直切分
垂直拆分一般是按照业务和功能的维度进行拆分,把数据分别放到不同的数据库中。
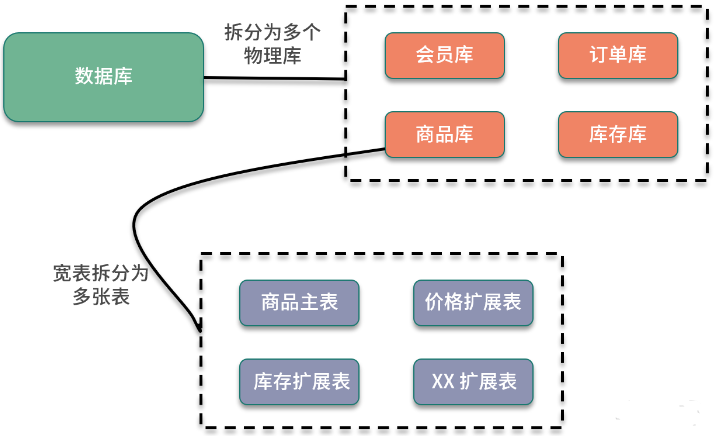
水平切分
水平拆分是把相同的表结构分散到不同的数据库和不同的数据表中,避免访问集中的单个数据库或者单张数据表,具体的分库和分表规则,一般是通过业务主键,进行哈希取模操作。
例如,电商业务中的订单信息访问频繁,可以将订单表分散到多个数据库中,实现分库;在每个数据库中,继续进行拆分到多个数据表中,实现分表。路由策略可以使用订单 ID 或者用户 ID,进行取模运算,路由到不同的数据库和数据表中。

分库分表后引入的问题
下面看一下,引入分库分表后额外增加了哪些系统设计的问题。
1)分布式事务问题
对业务进行分库之后,同一个操作会分散到多个数据库中,涉及跨库执行 SQL 语句,也就出现了分布式事务问题。
比如数据库拆分后,订单和库存在两个库中,一个下单减库存的操作,就涉及跨库事务。关于分布式事务的处理,我们在专栏“分布式事务”的模块中也介绍过,可以使用分布式事务中间件,实现 TCC 等事务模型;也可以使用基于本地消息表的分布式事务实现。如果对这部分印象不深,你可以回顾下前面讲过的内容。
2)跨库关联查询问题
分库分表后,跨库和跨表的查询操作实现起来会比较复杂,性能也无法保证。在实际开发中,针对这种需要跨库访问的业务场景,一般会使用额外的存储,比如维护一份文件索引。另一个方案是通过合理的数据库字段冗余,避免出现跨库查询。
3)跨库跨表的合并和排序问题
分库分表以后,数据分散存储到不同的数据库和表中,如果查询指定数据列表,或者需要对数据列表进行排序时,就变得异常复杂,则需要在内存中进行处理,整体性能会比较差,一般来说,会限制这类型的操作。具体的实现,可以依赖开源的分库分表中间件来处理。
分库分表常见的中间件
1)cobar
cobar是阿里的b2b团队开发和开源的,属于proxy层方案,介于应用服务器和数据库服务器之间。应用程序通过JDBC驱动访问cobar集群,cobar根据SQL和分库规则对SQL做分解,然后分发到MySQL集群不同的数据库实例上执行。cobar并不支持读写分离、存储过程、跨库join和分页等操作。早些年还可以用,但是最近几年都没更新了,基本没啥人用,算是淘汰了。
2)TDDL
TDDL是淘宝团队开发的,属于client层方案。支持基本的crud语法和读写分离,但是并不支持join、多表查询等语法。目前使用的也不多,因为使用还需要依赖淘宝的diamond配置管理系统。
3)atlas
atlas是360开源的,属于proxy层方案。以前是有一些公司再用的,但是社区最新的维护都在5年前了,现在用的公司也基本没有了。
4)sharding-jdbc
sharding-jdbc是当当开源的,属于client层方案。这个中间件对SQL语法的支持比较多,没有太多限制。2.0版本也开始支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。目前社区也还一直在开发和维护,算是比较活跃,是一个现在也可以选择的方案。
5)mycat
mycat是基于cobar改造的,属于proxy层方案。其支持的功能十分完善,是目前非常火的一个数据库中间件。社区很活跃,不断在更新。