Elastic Stack介绍
在Elastic Stack之前我们听说过ELK,ELK分别是Elasticsearch,Logstash,Kibana这三款软件在一起的简称,在发展的过程中又有新的成员Beats的加入,就形成了Elastic Stack。

Elastic Stack生态圈
在Elastic Stack生态圈中Elasticsearch作为数据存储和搜索,是生态圈的基石,Kibana在上层提供用户一个可视化及操作的界面,Logstash和Beat可以对数据进行收集。在上图的右侧X-Pack部分则是Elastic公司提供的商业项目。
Elastic Stack的组成部分
1. Logstash
是开源的服务器端数据收集管道,支持从不同的数据源采集数据,转换数据,最后将数据发送到不同的存储库中。后被Elastic公司在2013年收购,成为Elastic公司里专处理数据管道的部分。
Logstash具有如下特性:
1)可以实时解析和转换数据,比如从IP地址转换出地理坐标,将PII数据匿名话,排除一些敏感字段。
2)可扩展,拥有可扩展的插件生态系统,目前市面上具有200多个插件(日志/数据库/Archsigh/Netflow)。
3)可靠性、安全性。Logstash会通过持久化队列来保证至少将运行中的事件送达一次,同时将数据进行传输加密。
4)监控。
2. Kibana
Kibana是一款数据可视化工具,最早是基于Logstash来创建的一个工具,在2013年时候也是被Elastic公司收购。目前Kibana最常用就是以图表的形式呈现数据,并且具有可扩展的用户界面,配置和管理ElasticSearch。
Kibana特点:
1)Kibana可以提供各种可视化的图表;
2)可以通过机器学习的技术,对异常情况进行检测,用于提前发现可疑问题;
3. ElasticSearch:
ElasticSearch是对数据进行搜索、分析和存储,其是基于JSON的分布式搜索和分析引擎,专门为实现水平可扩展性、高可靠性和管理便捷性而设计的。
它的实现原理主要分为以下几个步骤:
1)首先用户将数据提交到ElasticSearch数据库中;
2)再通过分词控制器将对应的语句分词;
3)将分词结果及其权重一并存入,以备用户在搜索数据时,根据权重将结果排名和打分,将返回结果呈现给用户;
docker中运行ElasticSearch Kibana及Cerebro
cerebro是ElasticSearch一款监控工具,它的github地址:https://github.com/lmenezes/cerebro/releases。下吗使用docker及docker-compose来安装这些软件。
docker-compose.yaml文件内容如下
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: kibana7
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_01
environment:
- cluster.name=geektime
- node.name=es7_01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_02
environment:
- cluster.name=geektime
- node.name=es7_02
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01,es7_02
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data2:/usr/share/elasticsearch/data
networks:
- es7net
volumes:
es7data1:
driver: local
es7data2:
driver: local
networks:
es7net:
driver: bridge
在本地环境一个空目录中,创建上面这个 docker-compose.yaml文件,然后在执行命令docker-compose up 来启动容器。

启动好之后,我们在浏览器输入 http://localhost:5601/ 来访问Kibana。

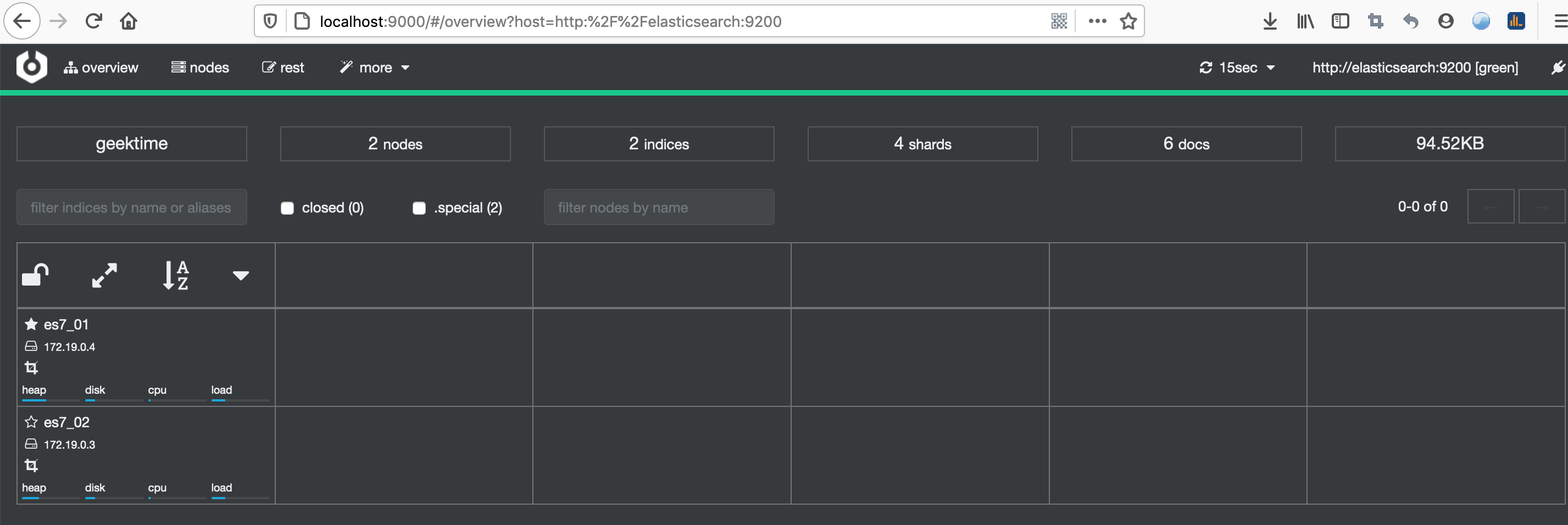
在输入http://localhost:9000/ 来访问cerebro。

登陆进去之后展示的就是cerebro的管理界面。
下面在安装Logstash,这里我之前一篇文章有写关于Logstash的使用与安装 https://www.cnblogs.com/songgj/p/11183566.html,安装好之后在MovieLens上下载一些测试数据来填充到Elasticsearch中,
(MovieLens数据集包含多个用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息。)
MovieLens地址 https://grouplens.org/datasets/movielens/
