一、关键点
MYSQL双查询错误之所以产生,有两个关键点:
(1)SQL语句中使用GROUP BY语句时会生成临时表;
(2)RAND()在查询和存储时生成的随机数有可能不同.
补充:===========================================================================================
(1)group by常和min(),max(),count(),sum(),avg()等聚合函数配合使用,如: select name, count(*) from user group by name; 这条语句会根据user表中的name字段进行分组,name字段中的值一样的记录会被划分为同一个组,而count(*)则会计算每个组中
的记录数,当我们运行上述语句时,会得到: +--------+------------+ | name | count(*) | +--------+------------+ | andy | 1 | | nana | 1 | | mike | 1 | +--------+------------+ user表中的name字段有三个值:mike、anna、andy,所以执行SQL语句后会得到三个分组,每个分组的记录数为1;我们往user
表中再添加一条记录: insert into user value(4,'mike'); 此时表中有两个同名的人,都叫mike,再执行SQL语句时,会得到如下结果: +--------+------------+
| name | count(*) |
+--------+------------+
| andy | 1 |
| nana | 1 |
| mike | 2 |
+--------+------------+
在name字段值为mike的分组中,可以看到记录数变为2了.
(2)rand()函数随机生成0和1之间的数(0和1除外)
================================================================================================
二、原理探究
1. 回顾在《MYSQL双查询错误1》中搭建的环境中使用的产生错误信息的SQL语句:
select count(*), concat((select database()), floor(rand()*2)) as a from user group by a;
说明:SQL语句中,rand()*2随机产生0和2之间(不包括0和2)的随机数,而floor(rand()*2)则会随机产生0和1这两个数之一
执行上述语句时,在会话期间,数据库会为当前会话维护一个主键为a的临时表,各个字段如下:
a count(*)
补充说明:实际上,字段的顺序应该是 count(*) a 只是我们把主键a放到了前面
针对由我们的SQL语句产生的每一个a值,数据库首先会查询临时表中有没有一样的a字段值,若有,则相应的count(*)字
段值加1,否则的话将a值插入到临时表的a字段中,相应的count(*)字段值置为1. 这里,我们先来理一理两个问题:
(1)针对新产生的a值,临时表中有相同的a字段值时是否会发生查询错误?
(2)针对新产生的a值,临时表中没相同的a字段值时是否会发生查询错误?
先来解决第一个问题. 将SQL语句修改如下:
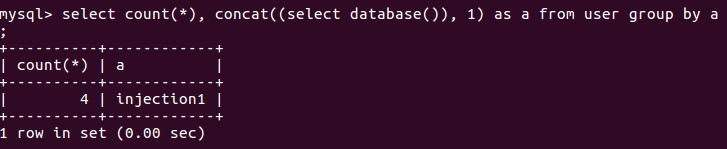
select count(*), concat((select database()), 1) as a from user group by a;
变化:针对user表中的每一条记录,SQL语句产生的a值均为injection1
多次执行新的SQL语句,情况是:没有查询错误产生,每次都得到的结果如下:
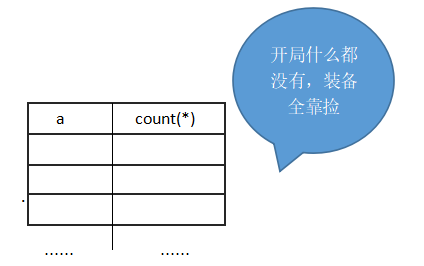
为什么不会产生查询错误呢?理解在这期间临时表中存储的信息如何变化就明白了. 首先,刚开始临时表中没有数据.
针对user表中的第一条记录,新的SQL语句产生的a值为injection1,数据库在临时表中查询到没有任何a字段值与刚产生
的a值相同,于是决定:将a值插入到a字段中.

针对user表的第二条记录,新的SQL语句产生的a值同样为injection1,数据库在临时表中查询到已经有a字段值和新的
a值一样了,于是决定:将对应的count(*)字段值加1.

user表中有4条记录,最终临时表中的count(*)字段会变为4. 可以看到,在新的SQL语句执行的会话期间,没有查询错误产生.
情况逐渐明了了,查询错误的产生可能与第一个问题无关. 接下来我们讨论第二个问题.
2. 为了便于叙述,将新的SQL语句称为SQL2,而另一个称为SQL1吧. 执行SQL1,当产生的a值与临时表中的各个a字段值不
同时(查询阶段),会将新的a值插入临时表中的a字段(插入阶段),并将对应的count(*)字段值置为1. 在这个过程中,错误
就发生在插入阶段. 在这个过程中,有两个关键的时点,一是查询时,二时插入时,在这两个时间点,rand()都会产生随机数,
随机数的产生使得两个时间点的a值有可能不一致,导致在插入阶段可能发生错误. 简单点说就是:在查询阶段和插入阶段的a
值有可能不同,这就是造成错误的原因. 接下来,我们从1条记录开始慢慢增加user表中的记录数,每一次都执行SQL1,看看
会发生什么.
(1)记录数为1时(只保留id为1的记录)
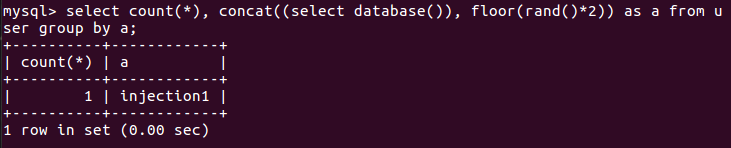
情况是:无论执行多少次,都不会发生错误,为什么呢?首先临时表是空的,而user表中只有一条记录,对应
要统计到临时表中的a值也只有一个,错误自然不会发生.
(2)记录数为2时(增加id为2,name为anna的记录)
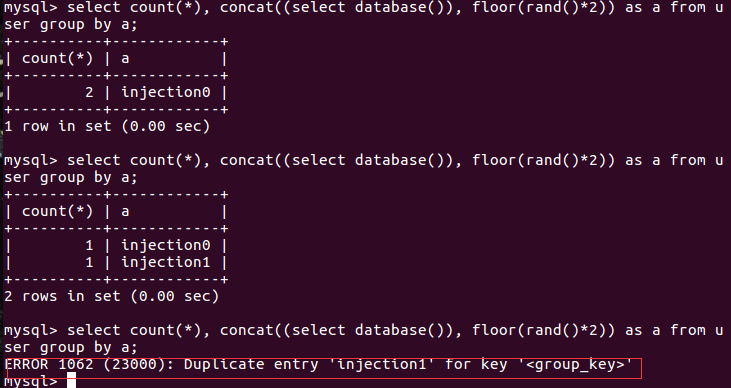
可以看到,第三次执行SQL1的时候,发生了错误. 第一次为什么没错误呢?发生的情况是这样的.
i)针对user表中的第一条记录,产生的a值为injection0,查询阶段的a值就是injection0,查询到临时表中a字段值没有 injection0,于是数据库决定:插入a值. 前面我们说过,由于随机数的关系,在插入阶段a值有可能会变化,有可能变为 injection1,或者还是injection0.不过这时候由于临时表是空的,所以都不会有错误发生,在插入阶段a为injection0时,
就插入injection0,否则插入injection1.显然,这里最终插入的是injection0. ii)针对user表中第二条记录,产生的a值必然是injection0,在查询阶段数据库检查到临时表中a字段值中有injection0, 于是数据库决定:将对应的count(*)字段值加1. 这时候,不论在插入阶段a值变为什么,数据库都不会再执行检查,而是直 接将count(*)字段值加1. 这就是第一次执行SQL1时发生的情况. 那么对于第一次执行SQL1,在什么情况下会发生错误呢? iii)在ii中,针对user表中第二条记录产生的a值若为injection1,在查询阶段数据库检查到临时表中所有a字段值中没有 injection1,于是决定:将injection1插入到临时表中. 不巧,在插入阶段,a值变为了injection0,由于表中本来就存
在injection0了,于是就会报错了. 同样可以这样去分析第二次第三次执行SQL1发生的情况.
(3)记录数为3及以上,都会引发错误.
3. 经过以上分析,我们已经抓到了错误最关键的点了:在查询阶段和插入阶段的主键值不一致导致了错误的产生.
三、结论
在将数据统计到临时表中时(查询阶段和插入阶段的数据不一致),由于主键具有唯一性,如果某主键值在临时表中已经存
在,而在插入阶段还试图插入相同的主键值时,数据库便会报错.
============================ 参考 ==============================
https://www.cnblogs.com/laoxiajiadeyun/p/10278512.html