1.固定学习率的梯度下降
y=x^4+2x ,初值取x=1.5,学习率使用0.01
#coding:utf-8 #求x^4+2x的导数 def g(x): return 4.0*x**3+2; #梯度下降法求f(x)的最小值 x=1.5 a=0.01 y1=x**4+2*x y2=1000 i=0 while y2-y1>10**-20: i=i+1 d=g(x) x-=d*a y2 = y1 y1=x**4+2*x print("%d %f %f " %(i,a,x)) print (y1)
运行结果如下:
迭代次数 学习率 x
…… …… ……
283 0.010000 -0.793701
284 0.010000 -0.793701
285 0.010000 -0.793701
286 0.010000 -0.793701
y=-1.1905507889761484
可知通过286次的迭代达到我们要求得精度
下面做个试验看一下不同的函数对相同的学习率有什么影响
(1) y=x^2 ,初值取x=1.5,学习率使用0.01

分析:
效果还不错,经过200次迭代,x=0.0258543,经过1000次迭代,x=2.52445×10 -9
(2)y=x^4 ,初值取x=1.5,学习率使用0.01
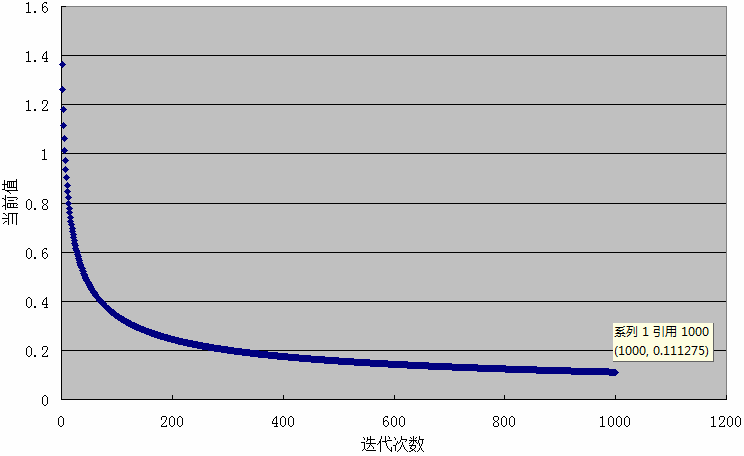
分析:
效果不理想,经过200次迭代,x=0.24436; 经过1000次迭代,x=0.111275
通过对比,明显看到第一个函数更理想,想要达到我们的要求得迭代次数更少。同时发现,不同的学习率对不同的函数时不一样的,每个函数的每次迭代都应该寻找一个最适合的学习率才可以使得迭代次数变少并保证函数收敛,不会震荡。
2.优化学习率
调整学习率: 在斜率(方向导数)大的地方,使用小学习率,在斜率(方向导数)小的地方,使用大学习率
(1)计算学习率的方法
视角转换:
记当前点为x k ,当前搜索方向为d k (如:负梯度方向),因为学习率α是待考察的对象,因此,将下列函数f(x k +αd k )看做是关于α的函数h(α)。
h(α)=f(x k +αd k) ,α>0
当α=0时,h(0)=f(x k )
导数![]()
学习率α的计算标准:
因为梯度下降是寻找f(x)的最小值,那么,在x k 和d k 给定的前提下,即寻找函数f(x k +αd k )的最小值。即:
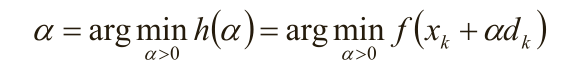
进一步,如果h(α)可导,局部最小值处的α满足:
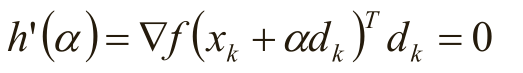
学习率函数导数的分析:
将α=0带入:![]()
下降方向d k 可以选负梯度方向![]()
从而:![]()
如果能够找到足够大的α,使得![]()
则必存在某α,使得![]()
α * 即为要寻找的学习率。
(2)求a的两种方法
1)二分线性搜索:不断将区间[α1, α2]分成两半,选择端点异号的一侧,知道区间足够小或者找到当前最优学习率。
2)回溯线性搜索:基于Armijo准则计算搜素方向上的最大步长,其基本思想是沿着搜索方向移动一个较大的步长估计值,然后以迭代形式不断缩减步长,直到该步长使得函数值f(x k +αd k )相对与当前函数值f(x k )的减小程度大于预设的期望值(即满足Armijo准则)为止。
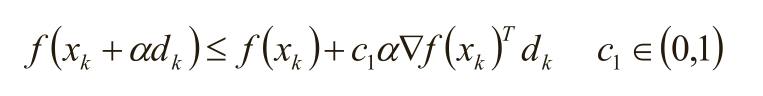
代码实现:
1 def get_A_Atmiho(x,d,a): 2 c1=0.3 3 now=f(x) 4 next=f(x-a*d) 5 #下面的循环是寻找最大的步长a,使得目标函数可以向减小的方向移动 6 count=30 7 while next<now: 8 a=a*2 9 next=f(x-a*d) 10 count=-1 11 if count==0: 12 break 13 #寻找一个比较大的a使得减小后的函数值相对于当前函数值的差满足预设的期望值 14 count=50 15 while next>now-c1*a*d**2: 16 a=a/2 17 next=f(x-a*d) 18 count-=1 19 if count==0: 20 break 21 return a;
加上上面这个求步长的函数后,每次求值不管x的初始值是什么,迭代次数一般不多于20次就可达到要求得精度,而以前固定步长都要迭代200步左右。通过调整c1可以改变预设期望值,当c1比较小时,一般迭代次数就会减少
回溯与二分线性搜索的异同:
(1)二分线性搜索的目标是求得满足h‘(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。
(2)二分线性搜索可以减少下降次数,但在计算最优步长上花费了不少代价;回溯线性搜索找到一个差不多的步长即可。