Antlr(Another Tool for Language Recognition)为开源的语法分析器,可以将输入的内容自动生成语法树;开发者可以使用它自定义自己的领域语言,只需创建语法规则文件,使用Antlr根据该规则文件生成相对应的类,再这些类的基础上我们可以用于实现自己的功能;Antlr4为Antlr的最新版本目前看到的基本也是Antlr4;
这些类主要包括两个方面的内容:1、实现了对输入的内容进行词法分析(Lexer)部分;2、根据词法构建出对应的语法树(Syntax Tree);
使用场景: 1、领域特定语言;2、文本解析;3、算术运算等等;在各类开源框架中也都有看到Antlr4的身影,如Hive、Spark、Presto、Hibernate 等等;
Antlr4基础语法
1、语法基本格式
//声明语法头,生成的Java类将使用此前缀,必须与xx.g4文件同名
grammar Name;
options {} //选项:语言选,输出选项等;项
lnaguage=Java;output=AST
import ... ; //如g4文件过大可拆分,使用import引入
tokens {...} //为那些没有关联词法规则的grammar定义tokens类型
channels {...} // 词法分析时才可定义
@actionName {...} //动作:可将目标语言嵌入到g4中,有可调用对应外部代码
//规则,此语法文件所定义的规则,分为词法规则与语法规则
规则;
rule1
...
ruleN
三个基本动作:
@header { package co.linx.test.antlr; }
此动作可在运行脚本后,所生成的类中自动带上包路径,不用手动移动。
@members {}
将代码中变量或方法注入到recognizer类中
@after {System.out.println("after matching rule;");}
规则:
词法规则(lexer):以大写字母开头,用于词法分析;
语法规则(parser):以小写字母开头,用于语法分析,字符串与lexer组合匹配分析句子;
以 : 开始 ; 结束,用 | 分隔对多规则分隔
2、简单示例
+匹配前一个匹配项最少一次, * 匹配前一个匹配项0次或多次 ?可选 ~ 取反
grammar Hello;
init :'hello' ID ; // parser. 匹配关键字'hello'后⾯跟⼀个ID
ID :[a-z]+ ; // lexer. 匹配⼩写字母组成的ID
WS :[ \t\r\n]+ -> skip ; //lexer. 系统级规则匹配时跳过空格、tabs、换⾏符
一个Antlr4计算器
1、语法文件:
grammar Calc;
prog : stat+;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE:'\r'? '\n' ;
DELIMITER : ';';
WS : [ \t]+ -> skip;
可使用Maven插件、IDEA插件、或Antlr4自带命令行工具生成相关词法、语法分析器类;
Antlr4提供了两种方式可以访问语法树:观察者模式、访问者模式;
观察者模式: 通过结点监听触发处理方法,无需定义遍历语法树顺序,动作与文法解耦,处理时需通过自定义map存储中间结果,继承:XXXBaseListener类实现;
访问者模式: 主动遍历语法树,动作与文法解耦,visitor访问节点时有返回值,无需定义map存储中间结果,继承:XXXBaseVisitor类实现;
2、实现计算逻辑
这里使用访问者模式实现计算器,继承:CalcBaseVisitor类,重写visitMulDiv与visitAddSub方法实现:加减乘除计算逻辑;
@Override
public Integer visitMulDiv(CalcParser.MulDivContext ctx) {
Integer left = ctx.expr(0).accept(this);
Integer right = ctx.expr(1).accept(this);
if (ctx.op.getType() == CalcParser.MUL){
return left * right;
}else{
return left / right;
}
}
@Override
public Integer visitAddSub(CalcParser.AddSubContext ctx) {
Integer left = ctx.expr(0).accept(this);
Integer right = ctx.expr(1).accept(this);
if (ctx.op.getType() == CalcParser.ADD){
return left + right;
}else{
return left - right;
}
}
3、使用该语法树计算器
CharStream input = CharStreams.fromString("22*3+12\r\n");
CalcLexer lexer=new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog(); // parse
EvalVisitor vt=new EvalVisitor();
System.out.printf("%s\n", vt.visit(tree));
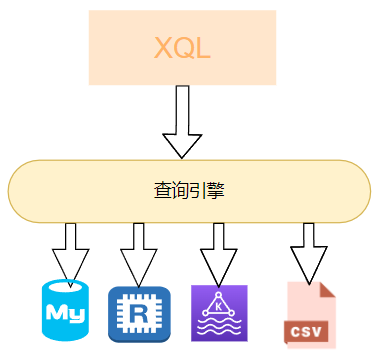
Antlr的实现可不只是计算器这种小玩意,我们通常有多个数据源,在没有统一的查询入口的时候通常只能打开各个客户端工具进行查询,有了Antlr我们可以很方便的实现一种称之为:XQL的语言,可实现通过XQL就可查询Kafka、Redis、MySQL、文件(csv、json、parquet)等数据源的数据;
通过Antlr实现的统一XQL查询引擎:
文章首发地址:https://mp.weixin.qq.com/s/BcuiM3ifm-PCOBZUja7vJg
参考资料:
antlr4
语法规则