RabbitMQ可以理解为软件的路由器。
从AMQP协议可以看出,MessageQueue、Exchange和Binding构成了AMQP协议的核心。
根据绑定规则将队列绑定到交换器上;
消息是发布到交换器上的;
有三种类型的交换器:direct,fanout和topic
基于消息的路由键和交换器类型,服务器决定将消息投递到哪个队列去。
下面我们就围绕这三个主要组件,从应用使用的角度全面的介绍如何利用Rabbit MQ构建消息队列以及使用过程中的注意事项。

一个queue是否可以与多个交换机进行绑定呢?????
可以的,直接在RoutingKey上配置就可以了。
消费者通过以下两种方式从特定队列中接收消息:
(1)通过AMQP的basic.consume命令订阅。这样做会将信道置为接收模式,直到取消对队列的订阅为止。
订阅了消息后,消费者在消费(或者拒绝)最近接收的那条消息后,就能从队列中(可用的)自动接收下一条消息。
如果消费者处理队列消息,并且/或者需要在消息一到达队列时就自动接收的话,你应该使用basic.consume。
(2)某些时候,你只想从队列获得单条消息而不是持续订阅。
向队列请求单条消息是通过AMQP的basic.get命令实现的。这样做可以让消费者接收队列中的下一条消息。
如果要获得更多消息的话,需要再次发送basic.get命令。
你不应该将basic.get放在一个循环里来替代basic.consume。因为这样做会影响Rabbit的性能。大致上讲,basic.get命令会订阅消息,然后取消订阅。
消费者理应始终使用basic.consume来实现高吞吐量。
如果至少有一个消费者订阅了队列的话,消息会立即发送给这些订阅的消费者。
但是如果消息到达了无人订阅的队列呢?
在这种情况下,消息会在队列中等待。一旦有消费者订阅到该队列,那么队列上的消息就会发送给消费者。
更有趣的问题是,当有多个消费者订阅到同一队列上时,消息是如何分发的。
当Rabbit队列拥有多个消费者时,队列收到的消息将以循环(round-robin)的方式发送给消费者。每条消息只会发送给一个订阅者。
消费者接收到的每一条消息都必须进行确认。消费者必须通过AMQP的basic.ack命令显式地向RabbitMQ发送一个确认,或者在订阅队列的时候就将auto_ack参数设置为true。当设置了auto_ack时,一旦消费者接收消息,RabbitMQ会自动视其确认了消息。
需要强调的是:
消费者对消息的确认 【是否成功消费,可以删除队列中的消息】
和
告诉生产者消息已经被接收了【消息已经成功到达队列,生产者的任务已经完成了】 这两件事 毫不相关。
因此,消费者通过确认命令告诉RabbitMQ它已经正确地接收了消息,同时RabbitMQ才能安全地把消息从队列中删除。
如果消费者收到一条消息,然后在确认之前从Rabbit断开连接(或者从队列上取消订阅),RabbitMQ会认为这条消息没有分发,然后重新分发给下一个订阅的消费者。
如果你的应用程序崩溃了,这样做可以确保消息会被发送给另一个消费者进行处理。
另一方面,如果应用程序有bug而忘记确认消息的话,Rabbit将不会给该消费者发送更多消息了。这是因为在上一条消息被确认之前,Rabbit会认为这个消费者并没有准备好接收下一条消息。
这个特性是在削峰场景比较有用。
因为,如果处理消息内容非常耗时或耗资源,则你的应用程序可以延迟确认该消息,直到消息处理完成。这样可以防止Rabbit持续不断的消息涌向你的应用而导致过载。
Rabbit给消费者1发送的消息一直没有确认,在不超时的情况下Rabbit是否会给另一个消费者2发送下一条消息呢?????
不会。只要一个消费者不确认,其它的消费者就都不会消费到消息,即便队列积压了。
在收到消息后,如果你想要明确拒绝而不是确认收到该消息的话,该如何呢?
举例来说,假设在处理消息的时候你遇到了不可恢复的错误,但是由于硬件问题,只影响到当前的消费者(这就是一个很好的示例,直到消息处理完成之前,你绝不能进行确认)。
只要消息尚未确认,则你有以下两个选择:
(1)把消费者从RabbitMQ服务器断开连接。这会导致RabbitMQ自动重新把消息入队并发送给另一个消费者。这样做的好处是所有的RabbitMQ版本都支持。
缺点是,这样 建立/断开连接的方式会额外增加RabbitMQ的负担(如果消费者在处理每条消息时都遇到错误的话,会导致潜在的重大负荷)
(2)如果你正使用RabbitMQ2.0.0或更新的版本,那就使用AMQP的basic.reject命令。顾名思义:basic.reject允许消费者拒绝RabbitMQ发送的消息。
如果把reject命令的requue参数设置成true的话,RabbitMQ会将消息重新发送给下一个订阅的消费者。
如果把reject命令的requeue参数设置为false的话,RabbitMQ立即会把消息从队列中移除,而不会把它发送给新的消费者。
你也可以通过对消息确认的方式来简单地忽略该消息(这种忽略消息的方式的优势在于所有版本的RabbitMQ都支持)。如果你检测到一条格式错误的消息而任何一个消费者都无法处理的时候,这样做就十分有用。
注意:
当丢弃一条消息时,为什么要使用basic.reject命令,并将requeue参数设置成false来替代确认消息呢?
在将来的RabbitMQ版本中会支持一个特殊的“死信”(dead letter)队列,用来存放那些被拒绝而不重入队列的消息。死信队列让你通过检测拒绝/未送达的消息来发现问题。
如果应用程序想自动从死信队列功能中获益的话,需要使用reject命令并将requeue参数设置成false。
还有一件更重要的事情:如何创建队列。
消费者和生产者都能使用AMQP的queue.declare命令来创建队列。
但是如果消费者在同一条信道上订阅了另一个队列的话,就无法再声明队列了。必须首先取消订阅,将信道置为“传输”模式。
当创建队列时,你常常想要指定队列名称。
消费者订阅队列时需要队列名称,并在创建绑定时也需要指定队列名称。
如果不指定队列名称的话,Rabbit会分配一个随机名称并在queue.declare命令的响应中返回(对于构建在AMQP上的RPC应用来说,使用临时“匿名”队列很有用)。
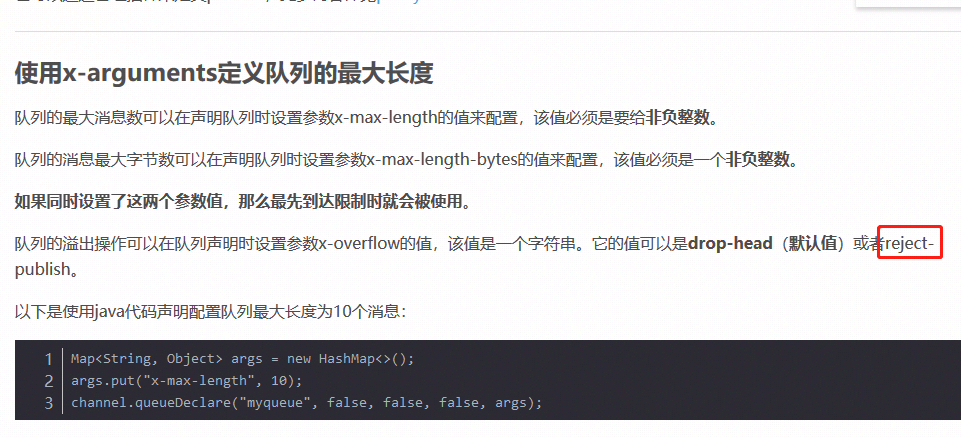
以下是队列设置中另一些有用的参数:
exclusive【专用的、专有的、排他的】:如果设置为true的话,队列将变成私有的,此时只有你的应用程序才能够消费队列消息。当你想要限制一个队列只有一个消费者的时候很有帮助。
auto-delete:当最后一个消费者取消订阅的时候,队列就会自动移除【只有交换器】。如果你需要临时队列只为一个消费者服务的话,请结合使用auto-delete和exclusive。当消费者断开连接时,队列就被移除了。
如果尝试声明一个已经存在的队列会发生什么呢?
只要声明参数完全匹配现存的队列的话,Rabbit就什么也不做,并成功返回,就好像这个队列已经创建成功一样(如果参数不匹配的话,队列声明尝试失败)。
如果只是想检测队列是否存在,则可以设置queue.declare的passive选项为true。在该设置下,如果队列存在,那么queue.declare命令会成功返回;如果队列不存在的话,queue.declare命令不会创建队列而会返回一个错误。
当设计应用程序时,你最有可能会问自己,是该由生产者还是消费者来创建所需的队列呢?
看起来最自然的答案是由消费者来创建队列。毕竟,消费者才需要订阅队列,而且总不能订阅一个不存在的队列,是吧?先别这么快下结论。你首先需要想清楚消息的生产者能否承担得起丢失消息。
发送出去的消息如果路由到了不存在的队列的话,Rabbit会忽略它们。
因此,如果你不能承担得起消息进入“黑洞”而丢失的话,你的生产者和消费者就都应该尝试去创建队列。
另一方面,如果你能承担得起丢失消息,或者你实现一种方法来重新发布未处理的消息的话(我们会向你展现如何做到这一点),你可以只让自己的消费者来声明队列。
队列是AMQP消息通信的基础模块:
(1)为消息提供了存储空间,消息在此等待消费
(2)对负载均衡来说,队列是绝佳方案。只需附加一堆消费者,并让RabbitMQ以循环的方式均匀地分配发来的消息。
(3)队列是Rabbit中消息的最后终点(除非消息进入了“黑洞”)
消息如何到达队列呢?
当你想要将消息投递到队列时,你通过把消息发送给交换器来完成。然后根据确定的规则,RabbitMQ将会决定消息该投递到哪个队列。这些规则被称作路由键(routing key)。
队列通过路由键绑定到交换器。当你把消息发送到代理服务器时,消息将拥有一个路由键----即便是空的-----RabbitMQ也会将其和绑定使用路由键进行匹配。如果相匹配的话,那么消息将会投递到该队列。
如果路由的消息不匹配任何绑定模式的话,消息将进入“黑洞”。
使用交换器和绑定来完成不同使用场景之外,还有另外一个好处是:对于发送消息给服务器的发布者来说,它不需要关心服务器的另一端(整个消息处理环节中的队列和消费者)的逻辑。
direct交换器:如果路由键匹配的话,消息就被投递到对应的队列。
服务器必须实现direct类型交换器,包含一个空白字符串的默认交换器。
当声明一个队列时,它会自动绑定到默认交换器,并以队列名称作为路由键。
这意味着你可以使用如下代码发送消息到之前声明的队列去。前提是你已经获得了信道实例:
$channel->basic_publish($msg,'','queue-name');
第一个参数是你想要发的消息内容;
第二个参数是一个空的字符串,指定了默认交换器;
第三个参数就是路由键。
这个路由键就是之前用来声明队列的名称。
当默认的direct交换器无法满足应用程序的需求时,你可以声明你自己的交换器。只需发送 exchange.declare命令并设置合适的参数就行了。
fanout【扇出;展开;分列(账户)】交接器 会将收到的消息广播到绑定的队列上。
消息通信模式很简单:当你发送一条消息到fanout交换器时,它会把消息投递给所有附加在此交换器上的队列 【一条消息会copy多份分发给不同的消费者】。
这允许对单条消息做不同方式的反应。 类似于监听者模式。
topic交换器:可以将来自不同源头的消息能够到达同一队列。 队列绑定到交换器上的时候可以使用通配符。 譬如“ *.msg-inbox ”,单个“.”把路由键分为了几部分,“*”匹配特定位置的任意文本。为了实现匹配所有规则,你可以使用“#”字符
“*” 操作符会将 “.”视为分隔符;与之不同的是,“#”操作符没有分块的概念,它将任意 “.”字符均视为关键字的匹配部分。
-
1. 声明MessageQueue
在Rabbit MQ中,无论是生产者发送消息还是消费者接受消息,都首先需要声明一个MessageQueue。这就存在一个问题,是生产者声明还是消费者声明呢?要解决这个问题,首先需要明确:
a)消费者是无法订阅或者获取不存在的MessageQueue中信息。
b)消息被Exchange接受以后,如果没有匹配的Queue,则会被丢弃。
在明白了上述两点以后,就容易理解如果是消费者去声明Queue,就有可能会出现在声明Queue之前,生产者已发送的消息被丢弃的隐患。如果应用能够通过消息重发的机制允许消息丢失,则使用此方案没有任何问题。但是如果不能接受该方案,这就需要无论是生产者还是消费者,在发送或者接受消息前,都需要去尝试建立消息队列。这里有一点需要明确,如果客户端尝试建立一个已经存在的消息队列,Rabbit MQ不会做任何事情,并返回客户端建立成功的。
如果一个消费者在一个信道中正在监听某一个队列的消息,Rabbit MQ是不允许该消费者在同一个channel去声明其他队列的。Rabbit MQ中,可以通过queue.declare命令声明一个队列,可以设置该队列以下属性:
a) Exclusive:排他队列,如果一个队列被声明为排他队列,该队列仅对首次声明它的连接可见,并在连接断开时自动删除。这里需要注意三点:其一,排他队列是基于连接可见的,同一连接的不同信道是可以同时访问同一个连接创建的排他队列的。其二,“首次”,如果一个连接已经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同。其三,即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除的。这种队列适用于只限于一个客户端发送读取消息的应用场景。
b) Auto-delete:自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。
c) Durable:持久化,这个会在后面作为专门一个章节讨论。
d) 其他选项,例如如果用户仅仅想查询某一个队列是否已存在,如果不存在,不想建立该队列,仍然可以调用queue.declare,只不过需要将参数passive设为true,传给queue.declare,如果该队列已存在,则会返回true;如果不存在,则会返回Error,但是不会创建新的队列。
-
2. 生产者发送消息
在AMQP模型中,Exchange是接受生产者消息并将消息路由到消息队列的关键组件。ExchangeType和Binding决定了消息的路由规则。所以生产者想要发送消息,首先必须要声明一个Exchange和该Exchange对应的Binding。可以通过 ExchangeDeclare和BindingDeclare完成。在Rabbit MQ中,声明一个Exchange需要三个参数:ExchangeName,ExchangeType和Durable。ExchangeName是该Exchange的名字,该属性在创建Binding和生产者通过publish推送消息时需要指定。ExchangeType,指Exchange的类型,在RabbitMQ中,有三种类型的Exchange:direct ,fanout和topic,不同的Exchange会表现出不同路由行为。Durable是该Exchange的持久化属性,这个会在消息持久化章节讨论。声明一个Binding需要提供一个QueueName,ExchangeName和BindingKey。下面我们就分析一下不同的ExchangeType表现出的不同路由规则。
生产者在发送消息时,都需要指定一个RoutingKey和Exchange,Exchange在接到该RoutingKey以后,会判断该ExchangeType:
a) 如果是Direct类型,则会将消息中的RoutingKey与该Exchange关联的所有Binding中的BindingKey进行比较,如果相等,则发送到该Binding对应的Queue中。

b) 如果是 Fanout 类型,则会将消息发送给所有与该 Exchange 定义过 Binding 的所有 Queues 中去,其实是一种广播行为。

c)如果是Topic类型,则会按照正则表达式,对RoutingKey与BindingKey进行匹配,如果匹配成功,则发送到对应的Queue中。

-
3. 消费者订阅消息
在RabbitMQ中消费者有2种方式获取队列中的消息:
a) 一种是通过basic.consume命令,订阅某一个队列中的消息,channel会自动在处理完上一条消息之后,接收下一条消息。(同一个channel消息处理是串行的)。除非关闭channel或者取消订阅,否则客户端将会一直接收队列的消息。
b) 另外一种方式是通过basic.get命令主动获取队列中的消息,但是绝对不可以通过循环调用basic.get来代替basic.consume,这是因为basic.get RabbitMQ在实际执行的时候,是首先consume某一个队列,然后检索第一条消息,然后再取消订阅。如果是高吞吐率的消费者,最好还是建议使用basic.consume。
如果有多个消费者同时订阅同一个队列的话,RabbitMQ是采用循环的方式分发消息的,每一条消息只能被一个订阅者接收。例如,有队列Queue,其中ClientA和ClientB都Consume了该队列,MessageA到达队列后,被分派到ClientA,ClientA服务器收到响应,服务器删除MessageA;再有一条消息MessageB抵达队列,服务器根据“循环推送”原则,将消息会发给ClientB,然后收到ClientB的确认后,删除MessageB;等到再下一条消息时,服务器会再将消息发送给ClientA。
这里我们可以看出,消费者再接到消息以后,都需要给服务器发送一条确认命令,这个即可以在handleDelivery里显示的调用basic.ack实现,也可以在Consume某个队列的时候,设置autoACK属性为true实现。这个ACK仅仅是通知服务器可以安全的删除该消息,而不是通知生产者,与RPC不同。 如果消费者在接到消息以后还没来得及返回ACK就断开了连接,消息服务器会重传该消息给下一个订阅者,如果没有订阅者就会存储该消息。
既然RabbitMQ提供了ACK某一个消息的命令,当然也提供了Reject某一个消息的命令。当客户端发生错误,调用basic.reject命令拒绝某一个消息时,可以设置一个requeue的属性,如果为true,则消息服务器会重传该消息给下一个订阅者;如果为false,则会直接删除该消息。当然,也可以通过ack,让消息服务器直接删除该消息并且不会重传。
-
4. 持久化:
Rabbit MQ默认是不持久队列、Exchange、Binding以及队列中的消息的,这意味着一旦消息服务器重启,所有已声明的队列,Exchange,Binding以及队列中的消息都会丢失。通过设置Exchange和MessageQueue的durable属性为true,可以使得队列和Exchange持久化,但是这还不能使得队列中的消息持久化,这需要生产者在发送消息的时候,将delivery mode设置为2,只有这3个全部设置完成后,才能保证服务器重启不会对现有的队列造成影响。这里需要注意的是,只有durable为true的Exchange和durable为ture的Queues才能绑定,否则在绑定时,RabbitMQ都会抛错的。持久化会对RabbitMQ的性能造成比较大的影响,可能会下降10倍不止。
-
5. 事务:
对事务的支持是AMQP协议的一个重要特性。假设当生产者将一个持久化消息发送给服务器时,因为consume命令本身没有任何Response返回,所以即使服务器崩溃,没有持久化该消息,生产者也无法获知该消息已经丢失。如果此时使用事务,即通过txSelect()开启一个事务,然后发送消息给服务器,然后通过txCommit()提交该事务,即可以保证,如果txCommit()提交了,则该消息一定会持久化,如果txCommit()还未提交即服务器崩溃,则该消息不会服务器就收。当然Rabbit MQ也提供了txRollback()命令用于回滚某一个事务。
-
6. Confirm机制:
使用事务固然可以保证只有提交的事务,才会被服务器执行。但是这样同时也将客户端与消息服务器同步起来,这背离了消息队列解耦的本质。Rabbit MQ提供了一个更加轻量级的机制来保证生产者可以感知服务器消息是否已被路由到正确的队列中——Confirm。如果设置channel为confirm状态,则通过该channel发送的消息都会被分配一个唯一的ID,然后一旦该消息被正确的路由到匹配的队列中后,服务器会返回给生产者一个Confirm,该Confirm包含该消息的ID,这样生产者就会知道该消息已被正确分发。对于持久化消息,只有该消息被持久化后,才会返回Confirm。Confirm机制的最大优点在于异步,生产者在发送消息以后,即可继续执行其他任务。而服务器返回Confirm后,会触发生产者的回调函数,生产者在回调函数中处理Confirm信息。如果消息服务器发生异常,导致该消息丢失,会返回给生产者一个nack,表示消息已经丢失,这样生产者就可以通过重发消息,保证消息不丢失。Confirm机制在性能上要比事务优越很多。但是Confirm机制,无法进行回滚,就是一旦服务器崩溃,生产者无法得到Confirm信息,生产者其实本身也不知道该消息吃否已经被持久化,只有继续重发来保证消息不丢失,但是如果原先已经持久化的消息,并不会被回滚,这样队列中就会存在两条相同的消息,系统需要支持去重。
-
其他:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
Exchanges, queues, and bindings
exchanges are where producers publish their messages,
queues are where the messages end up and are received by consumers,
and bindings are how the messages get routed from the exchange to particular queues.

VHost
RabbitMQ 用户权限 分两部分:
(1)vhost: 数据隔离。 权限控制的基础,rabbitMQ的用户只能访问分配给自己的vhost
(2)Policy:可以动态更新用户对指定vhost下exchange和queue的访问行为,而不用重启应用。 一些参数也可以变相地用在权限控制方面的,譬如 max Length Bytes,如果设置为0, 对Exchange和queuey设置后,这个用户就无法从这个queue中接收消息,即取消用户对这个队列的权限。
这个功能对操作人员要求比较高。
https://blog.csdn.net/sinat_36553913/article/details/93537601?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4
Message
Queue
bindings and exchanges
fanout exchange 不理会routing key,消息直接广播到所有绑定的queue
Channel
参考资料
https://www.cnblogs.com/linkenpark/p/5393666.html
摘要:本文介绍了rabbitMq,提供了如何在Ubuntu下安装RabbitMQ 服务的方法。最后以RabbitMQ与java、Spring结合的两个实例来演示如何使用RabbitMQ。
一、rabbitMQ简介
1.1、rabbitMQ的优点(适用范围)
1. 基于erlang语言开发具有高可用高并发的优点,适合集群服务器。
2. 健壮、稳定、易用、跨平台、支持多种语言、文档齐全。
3. 有消息确认机制和持久化机制,可靠性高。
4. 开源
其他MQ的优势:
1. Apache ActiveMQ曝光率最高,但是可能会丢消息。
2. ZeroMQ延迟很低、支持灵活拓扑,但是不支持消息持久化和崩溃恢复。
1.2、几个概念说明
producer&Consumer
producer指的是消息生产者,consumer消息的消费者。
Queue
消息队列,提供了FIFO的处理机制,具有缓存消息的能力。rabbitmq中,队列消息可以设置为持久化,临时或者自动删除。
设置为持久化的队列,queue中的消息会在server本地硬盘存储一份,防止系统crash,数据丢失
设置为临时队列,queue中的数据在系统重启之后就会丢失
设置为自动删除的队列,当不存在用户连接到server,队列中的数据会被自动删除Exchange
Exchange类似于数据通信网络中的交换机,提供消息路由策略。rabbitmq中,producer不是通过信道直接将消息发送给queue,而是先发送给Exchange。一个Exchange可以和多个Queue进行绑定,producer在传递消息的时候,会传递一个ROUTING_KEY,Exchange会根据这个ROUTING_KEY按照特定的路由算法,将消息路由给指定的queue。和Queue一样,Exchange也可设置为持久化,临时或者自动删除。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别:
Direct
直接交换器,工作方式类似于单播,Exchange会将消息发送完全匹配ROUTING_KEY的Queue
fanout
广播是式交换器,不管消息的ROUTING_KEY设置为什么,Exchange都会将消息转发给所有绑定的Queue。
topic
主题交换器,工作方式类似于组播,Exchange会将消息转发和ROUTING_KEY匹配模式相同的所有队列,比如,ROUTING_KEY为user.stock的Message会转发给绑定匹配模式为 * .stock,user.stock, * . * 和#.user.stock.#的队列。( * 表是匹配一个任意词组,#表示匹配0个或多个词组)
headers
消息体的header匹配(ignore)
Binding
所谓绑定就是将一个特定的 Exchange 和一个特定的 Queue 绑定起来。Exchange 和Queue的绑定可以是多对多的关系。
virtual host
在rabbitmq server上可以创建多个虚拟的message broker,又叫做virtual hosts (vhosts)。每一个vhost本质上是一个mini-rabbitmq server,分别管理各自的exchange,和bindings。vhost相当于物理的server,可以为不同app提供边界隔离,使得应用安全的运行在不同的vhost实例上,相互之间不会干扰。producer和consumer连接rabbit server需要指定一个vhost。
1.3、消息队列的使用过程
1. 客户端连接到消息队列服务器,打开一个channel。
2. 客户端声明一个exchange,并设置相关属性。
3. 客户端声明一个queue,并设置相关属性。
4. 客户端使用routing key,在exchange和queue之间建立好绑定关系。
5. 客户端投递消息到exchange。
6. exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里
二、环境配置与安装
1、Erlang环境安装
RabbitMQ是基于Erlang的,所以首先必须配置Erlang环境。
从Erlang的官网 http://www.erlang.org/download.html 下载最新的erlang安装包,我下载的版本是 otp_src_R14B03.tar.gz 。
然后:
$ tar xvzf otp_src_R14B03.tar.gz $ cd otp_src_R14B03 $ ./configure
如下图:

注:
可能会报错 configure: error: No curses library functions found
configure: error: /bin/sh '/home/liyixiang/erlang/configure' failed for erts

原因是缺少ncurses包
解决:在ubuntu系统下
配置erlang环境变量
修改/etc/profile文件,增加下面的环境变量:(vim profile i插入 编辑完毕ESC退出 wq!强制修改)
下面是我的

2、RabbitMQ-Server安装
安装完Erlang,开始安装RabbitMQ-Server。安装方法有三种,这里笔者三者都试过了,就只有以下这个方法成功了。
直接使用:
apt-get install rabbitmq-server
安装完成后会自动打开:
使用命令查看rabbitmq运行状态:
rabbitmqctl status

停止
rabbitmqctl stop
开启
rabbitmq-server start
3、rabbitmq web管理页面插件安装
输入以下命令
cd /usr/lib/rabbitmq/bin/
rabbitmq-plugins enable rabbitmq_management

如果安装成功打开浏览器,输入 http://[server-name]:15672/ 如 http://localhost:15672/ ,会要求输入用户名和密码,用默认的guest/guest即可(guest/guest用户只能从localhost地址登录,如果要配置远程登录,必须另创建用户)。
如果要从远程登录怎么做呢?处于安全考虑,guest这个默认的用户只能通过http://localhost:15672来登录,其他的IP无法直接用这个guest帐号。
这里我们可以通过配置文件来实现从远程登录管理界面,只要编辑/etc/rabbitmq/rabbitmq.config文件(没有就新增),添加以下配置就可以了。
4、添加用户
vim /etc/rabbitmq/rabbitmq.config
然后添加
[ {rabbit, [{tcp_listeners, [5672]}, {loopback_users, ["asdf"]}]} ]
现在添加了一个新授权用户asdf,可以远程使用这个用户名。记得要先用命令添加这个命令才行:
5、开放端口
ufw allow 5672
三、简单Java实例
package com.lin.consumer; import java.io.IOException; import java.util.HashMap; import java.util.Map; import org.apache.commons.lang.SerializationUtils; import com.lin.EndPoint; import com.rabbitmq.client.AMQP.BasicProperties; import com.rabbitmq.client.Consumer; import com.rabbitmq.client.Envelope; import com.rabbitmq.client.ShutdownSignalException; /** * * 功能概要:读取队列的程序端,实现了Runnable接口 * * @author linbingwen * @since 2016年1月11日 */ public class QueueConsumer extends EndPoint implements Runnable, Consumer{ public QueueConsumer(String endPointName) throws IOException{ super(endPointName); } public void run() { try { //start consuming messages. Auto acknowledge messages. channel.basicConsume(endPointName, true,this); } catch (IOException e) { e.printStackTrace(); } } /** * Called when consumer is registered. */ public void handleConsumeOk(String consumerTag) { System.out.println("Consumer "+consumerTag +" registered"); } /** * Called when new message is available. */ public void handleDelivery(String consumerTag, Envelope env, BasicProperties props, byte[] body) throws IOException { Map map = (HashMap)SerializationUtils.deserialize(body); System.out.println("Message Number "+ map.get("message number") + " received."); } public void handleCancel(String consumerTag) {} public void handleCancelOk(String consumerTag) {} public void handleRecoverOk(String consumerTag) {} public void handleShutdownSignal(String consumerTag, ShutdownSignalException arg1) {} }



四、Rbbitmq与Spring结合使用

log4j.rootLogger=DEBUG,Console,Stdout #Console log4j.appender.Console=org.apache.log4j.ConsoleAppender log4j.appender.Console.layout=org.apache.log4j.PatternLayout log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n log4j.logger.java.sql.ResultSet=INFO log4j.logger.org.apache=INFO log4j.logger.java.sql.Connection=DEBUG log4j.logger.java.sql.Statement=DEBUG log4j.logger.java.sql.PreparedStatement=DEBUG log4j.appender.Stdout = org.apache.log4j.DailyRollingFileAppender log4j.appender.Stdout.File = E://logs/log.log log4j.appender.Stdout.Append = true log4j.appender.Stdout.Threshold = DEBUG log4j.appender.Stdout.layout = org.apache.log4j.PatternLayout log4j.appender.Stdout.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
接着运行整个工程即可:

