毕业设计做了一个简单的研究下验证码识别的问题,并没有深入的研究,设计图形图像的东西,水很深,神经网络,机器学习,都很难。这次只是在传统的方式下分析了一次。
今年工作之后再也没有整理过,前几天一个家伙要这个demo看下,我把一堆东西收集,打包给他了,他闲太乱了,我就整理记录下。这也是大学最后的一次作业,里面有很多记忆和怀念。
这个demo的初衷不是去识别验证码,是把验证的图像处理方式用到其他方面,车票,票据等。
这里最后做了一个发票编号识别的的案例:
地址:http://v.youku.com/v_show/id_XMTI1MzUxNDY3Ng==.html
demo中包含一个验证码识别处理过程的演示程序,一个自动识别工具类库,还有一个发票识别的演示程序

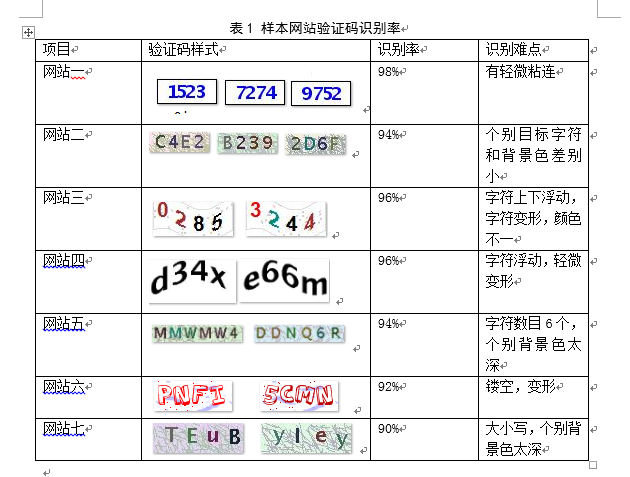
用了7个网站的图形验证码做为案例,当然还是有针对性的,避开了粘连,扭曲太厉害的:







最终的识别率:
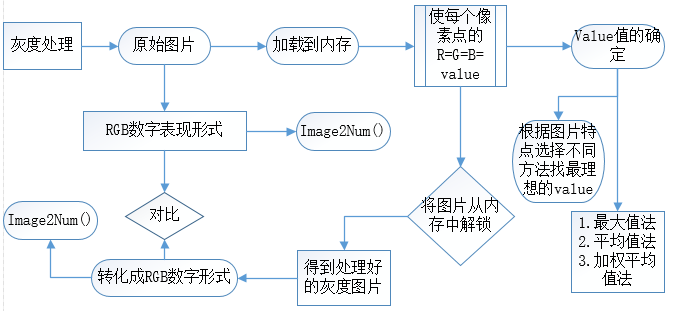
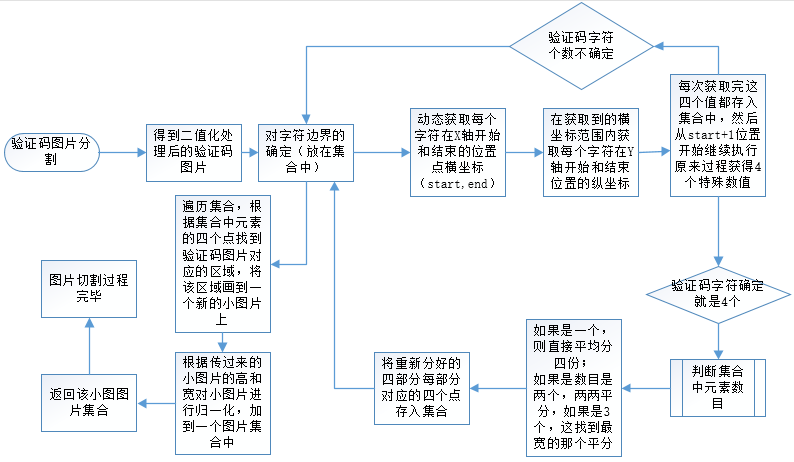
- 在验证码图像的处理过程中,涉及验证码生成,灰度处理,背景色去除,噪点处理,二值化过程,图片字符分割,图片归一化,图片特征码生成等步骤;
灰度处理方式主要有三种:
- 最大值法: 该过程就是找到每个像素点RGB三个值中最大的值,然后将该值作为该点的
- 平均值法:该方法选灰度值等于每个点RGB值相加去平均
- 加权平均值法:人眼对RGB颜色的感知并不相同,所以转换的时候需要给予三种颜色不同的权重
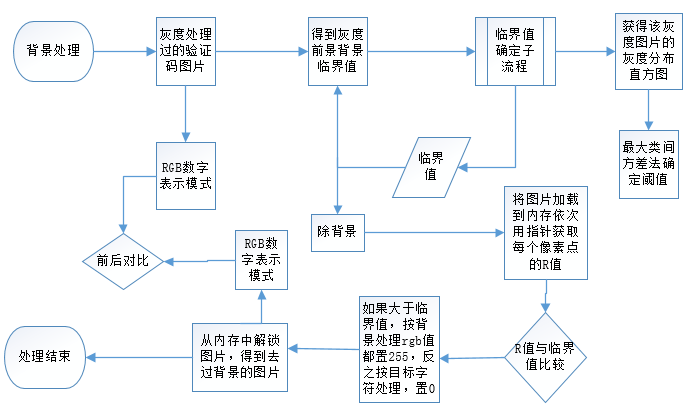
背景去除
该过程就是将背景变成纯白色,也就是尽可能的将目标字符之外的颜色变成白色。该阶段最难的就是确定图片的背景和前景的分割点,就是那个临界值。因为要将这张图片中每个像素点R值(灰度处理后的图片RGB的值是相同的)大于临界值的点RGB值都改成255(白色)。而这个临界点在整个处理过程中是不变的。
能区分前景和背景,说明在该分割点下,前景和背景的分别最明显,就像一层玻璃,将河水分成上下两部分,下面沉淀,相对浑浊,上面清澈,这样,两部分区别相当明显。这个片玻璃的所在位置就是关键。
常用临界点阈值确定算法
- 双峰法,这种算法很简单,假设该图片只分为前景和背景两部分,所以在灰度分布直方图上,这两部分会都会形成高峰,而两个高峰间的低谷就是图片的前景背景阈值所在。这个算法有局限性,如果该图片的有三种或多种主要颜色,就会形成多个山峰,不好确定目标山谷的所在,尤其是验证码,多种颜色,灰度后也会呈现不同层次的灰度图像。故本程序没有采用这种算法。
- 迭代法,该算法是先算出图片的最大灰度和最小灰度,取其平均值作为开始的阈值,然后用该阈值将图片分为前景和背景两部分,在计算这两部分的平均灰度,取平均值作为第二次的阈值,迭代进行,直到本次求出的阈值和上一次的阈值相等,即得到了目标阈值。
- 最大类间方差法,简称OTSU,是一种自适应的阈值确定的方法,它是按图像的灰度特性,将图像分成背景和目标2部分。背景和目标之间的类间方差越大,说明构成图像的2部分的差别越大,当部分目标错分为背景或部分背景错分为目标都会导致2部分差别变小。因此,使类间方差最大的分割意味着错分概率最小。而该方法的目标就是找到最符合条件的分割背景和目标的阈值。本程序也是采用的该算法进行背景分离的。
- 灰度拉伸算法,这是OTSU的一种改进,因为在前景背景差别不大的时候,OTSU的分离效果就会下降,此时需要增加前景背景的差别,这是只要在原来的灰度级上同时乘以一个系数,从而扩大灰度的级数。
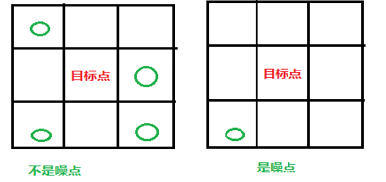
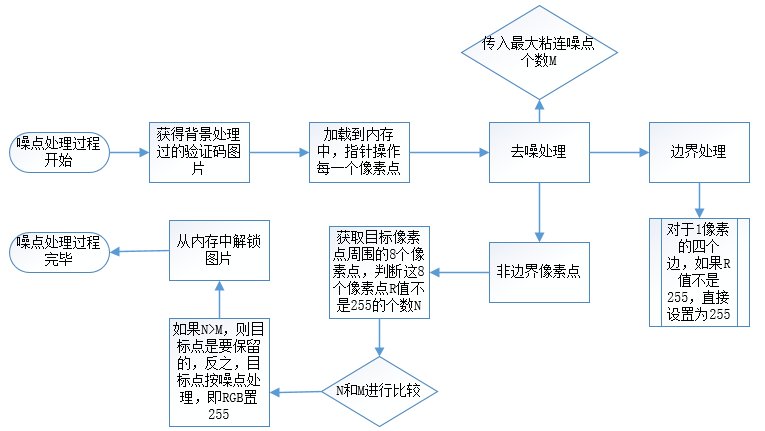
噪点判断及去除
首先是去除边框,有的验证码在图片边界画了一个黑色边框,根据去背景的原理这个边框是没有被去掉的。去除这个边框很简单,对加载到二维数组中每个像素点进行判断,如果该点的横坐标等于0或者图片宽度减一,或者总坐标等于0或者纵坐标等于图片高度减一,它的位置就是边框位置。直接RGB置0去除边框。
对于非边框点,判断该目标像素点是不是噪点不是直接最目标点进行判断的,是观察它周围的点。以这个点为中心的九宫格,即目标点周围有8个像素点,计算这8个点中不是背景点(即白色)点的个数,如果大于给定的界定值(该值和没中验证码图片噪点数目,噪点粘连都有关,不能动态获取,只能根据处理结果对比找到效果好的值),则说明目标点是字符内某个像素点的几率大些,古改点不能作为噪点,否则作为噪点处理掉。假设此次的界定值是2,则:
二值化
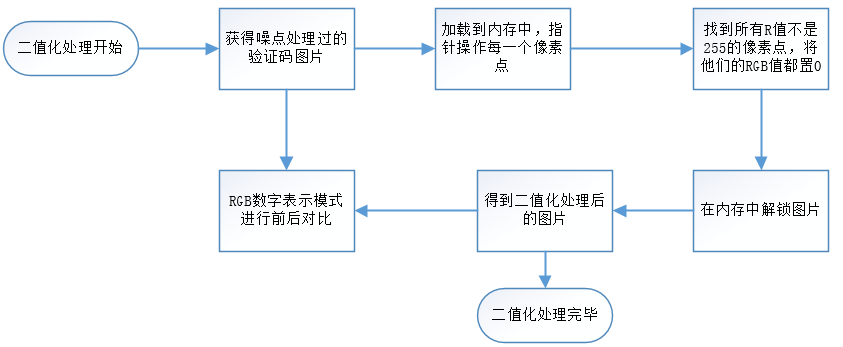
二值化区别于灰度化,灰度化处理过的图片,每个像素点的RGB值是一样的,在0-255之间,但是二值化要求每个像素点的RGB值不是0就是255.将图片彻底的黑白化。
二值化过程就是对去噪后的验证码图片的每个像素点进行处理,如果该点的R值不是255,那么就将该点的RGB值都改成0(纯黑色),这样整个过程下来,这正图片就变成真正意义上的黑白图片了。
图片分割
图片分割的主要算法
图片分割技术在图形图像的处理中占有非常重要的地位,图片是一个复杂的信息传递媒介,相应的,不是每个图片上的所有信息都是预期想要的,因次,在图片上”筛选“出目标区域图像就显得很重要,这就用到了图片分割技术。
图片字符的分割是验证码识别过程中最难的一步,也是决定识别结果的一步。不管多么复杂的验证码只要能准确的切割出来,就都能被识别出来。分割的方式有多种多样,对分割后的精细处理也复杂多样。
下面介绍几种成熟的分割算法:
- 基于阈值的分割,这种分割方式在背景处理中已经用到,通过某种方式找到目标图片区域和非目标图片区域间的分界值,进而达到将两个区域分离的目的,这种方式达不到区分每个字符的效果,所以在分割阶段没有采用。
- 投影分割,也叫做基于区域的分割,这种分割算法也很简单,就是将二值化后的图片在X轴方向做一次像素点分布的投影,在峰谷的变化中就能定位到每个目标区域了,然后对单个区域进行Y轴投影,进而确定区域位置。该方式对轻微粘连有一定的处理效果,但是,对与噪点会也会产生过分的分割,还有对‘7’,‘T’,‘L’等会产生分割误差,所以,程序中没有采用这种算法。
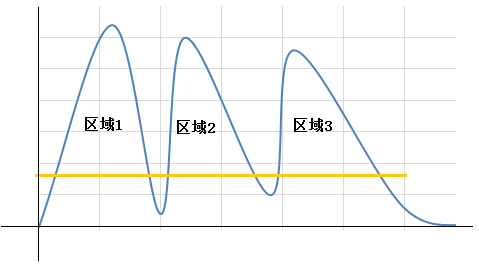
图3-7投影法
- 边缘检测分割,也叫做点扫描法,这种分割方式能一定程度满足程序的要求,因此,本程序也是采用了这种分割算法,后面会详细介绍。
- 聚类,聚类法进行图像分割是将图像空间中的像素用对应的特征空间点表示,根据它们在特征空间的聚集对特征空间进行分割,然后将它们映射回原图像空间,得到分割结果。这种方式处理复杂,但是对粘连,变形等复杂图像处理有良好的效果。由于时间有限,本次课题并没有对该方式进行深入分析实现。
3.6.2边缘检测分割算法
程序采用的是边缘检测的方式确定每个字符边界的。该算法的步骤如下:
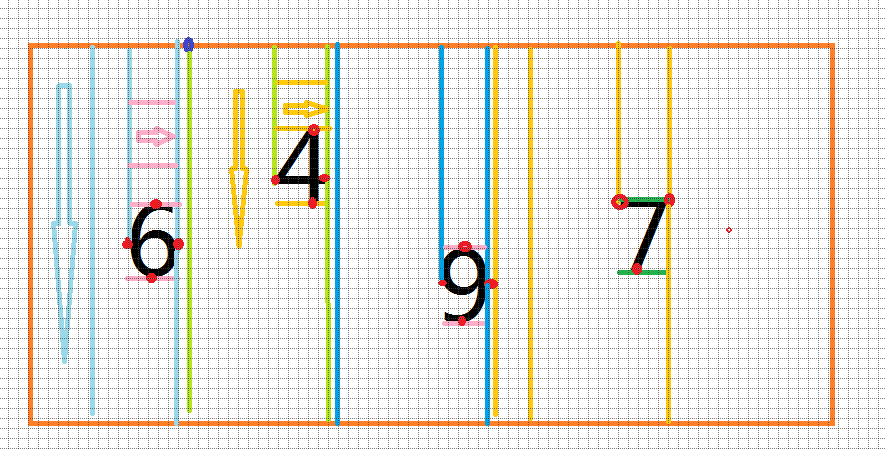
图3-8图片分割示意图
从图中可以看到,当程序判断”6“这个字符的边界时:
- 从扫描指针从图片最左边像素点X轴坐标为0开始,向下扫描,扫描宽度为1px,如果碰到了像素点R值是0的,记下此时X坐标A ,如果扫描到底部都没有遇到,则从指针向右移动一位,继续纵向扫描直到得到A。
- 扫描指针从A+1开始,纵向扫描每个像素点,遇到R值是255的,变量K(初始值0)自增一,扫描到底部判断K的值,如果K值等于图片高度,则停止后续扫描,记下此时X轴坐标B,否则指针向右移动一位,继续扫描直到得到B。
- 在X区间(A,B-1)中,指针从Y坐标是0点横向扫描,判断每个点的R值,如果R值等于0,则停止扫描,记下此时Y轴坐标C。否则,指着下移一个单位,继续横向扫描
- 在X区间(A,B-1),指针从C+1处开始横向扫描,判断每个像素点的R值,如果R值等于255,使N(初始值0)自增一,这行扫描结束后判断N的值,如果该值等于B-A,则停止扫描记下此时的Y轴坐标D,否则指针向下移动以为,继续横向扫描,知道得到D。
“4“这个字符边界的获取也是一样的,只是步骤一中扫描开始的位置X坐标0变成了B+1.
每次判断一下B-A,如果他的值小于你验证码字符中宽度最小的那个,(假设这里定的是4),则停止找边界把坐标加到集合中就可以了。
如学校的验证码字符中,宽度最窄的是1,但它的宽度是大于4的所以该设定没有问题,根据情况来定,一般宽度小于4的,验证码就很小了,不利于人看。
上述过程走完之后,就得到了左右,上下四个边界点的横坐标,纵坐标,即(A,B-1,C ,D-1);把这四个点确定的区域对应的原验证码所在的区域画到一张小图片上。然后把这张小图片按照设定的高宽进行归一化处理,把处理好的图片放入集合中返回。等待下一步处理。
分割前: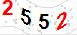 分割后的四张效果:
分割后的四张效果:
分割后的特殊处理
在这一过程中,由于图像的部分粘连,往往分割的结果都不会达到预期的效果,分割出的小图片也是千奇百怪。但是,考虑到现在大多数网站的验证码字符都是4个,意味着切割出来的小图片也得是四个,针对这种情况,我就做了进一步处理,首先看下切割后可能出现的情况:
这张验证码是二值化处理过的验证码,很明显,第一个和第二个字符是相互粘连的,利用程序的切割方式切出来的图片应该是3个小图片,类似这样:
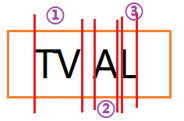
显然,①不是程序想要的情况,对于这种情况,即第一次切完是3部分的,就找到最宽的一个,然后从中间剁开。得到4部分图片。
相应的,还有2部分的时候:

这也不是我们理想的情况,也是同样的道理,把两部分中中间剁开,得到4个小图片。
还有这种情况,第一次切割完全是一张的:

我们只需把它均分4分就可以了。
当然上述处理会造成相应的误差,但是只要后面字模数量足够大,这样切割处理效果还是可以的。
此次只对4个字符的情况做了特殊的处理,其他个数的没有做,具体做法会在总结中介绍。
字模制作
这个过程是将切割好的图片转化成特征矩阵,把图片切割过程中返回的小图片集合进行特征值获取。在图片切割过程,程序已经将切割好的小图片进行了归一化处理,即长宽都相同,遍历每一个像素,如果该点R值是255,则就记录一个0,如果该点的R值是255,则记录一个1,这样按着顺序,记录好的0,1拼成字符串,这个字符串就是该图片的特征码。然后前面拼上该图片对应的字符,用‘--’连接。这样,一个图片就有一个特征值字符串对应了,把这个特征值字符串写入文本或数据库中,基本的字模库就建立好了。由于图片归一化的时候小图规格是20*30,所以,每个字模数据就是20*30+3+2(回车换行)=605个字符。
字模库的量越大,后面的识别正确率也就越高,但是,并不是越大越好,字模数据越多,比对消耗的时间就越多,相比来说效率就会下降。下面是一张字模库的部分图样:


验证码识别
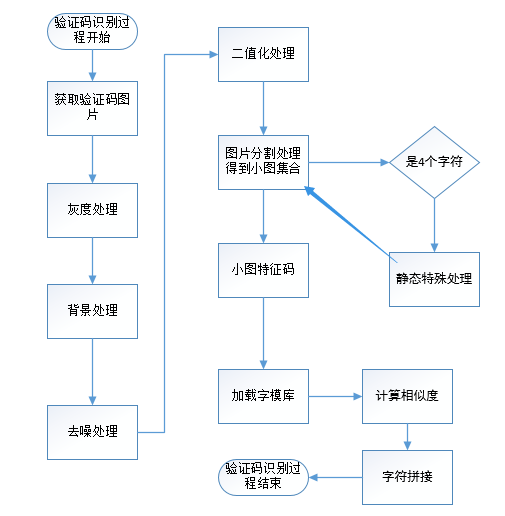
要想识别验证码,必须要有制作好的字模数据库,然后一次进行下面过程:
- 验证码图片的获取,该步骤验证码的来源可以是从网络流中获取验证码, 也可以从磁盘中加载图片。
- 图片处理,包括灰度,去噪,去背景,二值化,字符分割,图片归一化,图片特征码获取。
3.计算相似度,读取字模数据库中的字模数据,用归一化后的小图的特征码和字模数据进行对比,并计算相似度,记录相似度最高的字模数据项所对应的字符C。
4.识别结果,依次将所得到的字符C拼接起来,得到的字符串就是该验证码的识别结果。
下面是验证码识别的具体流程:
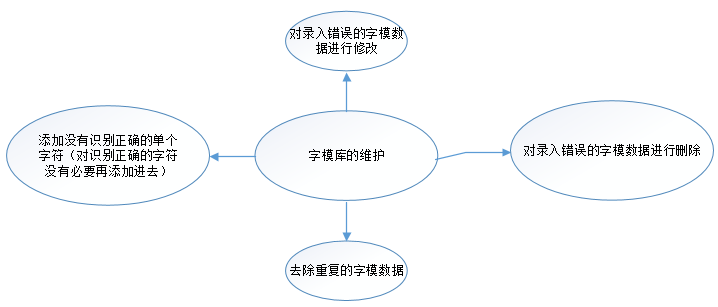
字模库维护
验证码的识别过程已经详细的分析,识别关键点一个在切割,一个在字模库的质量。字模库涉及两个问题,一个就是重复的问题,一个就是字模数据。这个阶段主要实现:
- 重复字模数据的过滤剔除。
- 对于插入错误的字模可以进行修改。
- 可以删除不需要的字模数据
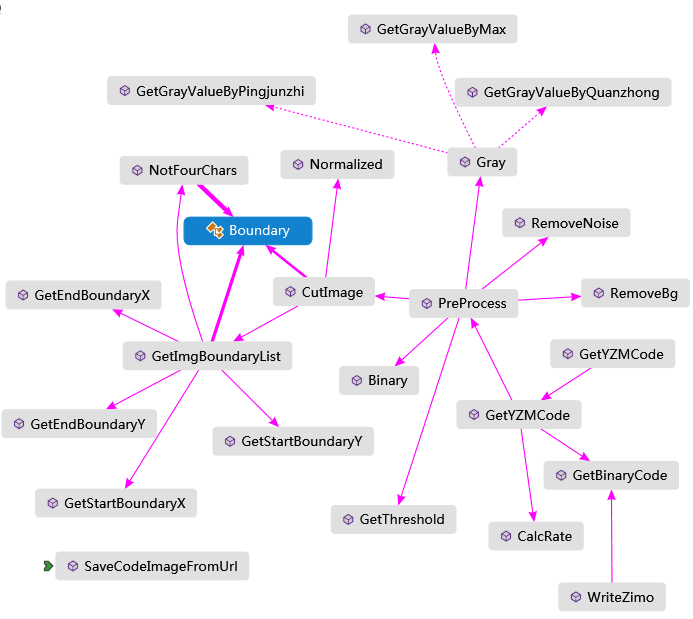
图片处理类的设计
图像处理类是遵循面向对象的思想设计的,将图像处理过程中用到的方法进行封装,对常用参数值进行参数默认值和可变参数设置,方法重载。该类是静态类,方便开发人员调用,其中Boundry是存储小图片边界信息的类,里面有四个边界值属性。
开发人员可以直接调用GetYZMCode()方法进行验证码的识别处理,这是一个重载方法,其余的方法会在下面具体实现中介绍具体方法的设计,下面是这个类图表示了ImageProcess类中主要的处理方法和之间的关系:
发票编号识别
这个是基于aforge.net实现的,参考国外一位扑克牌识别的代码。
过程是先确定发票的位置,然后定位到发票编号,切出发票编号,调用自动识别类库识别数字,然后再将识别数据写到屏幕上。当然也要实现训练字模;
完成这个demo过程还是比较有趣,感谢活跃在博客园,csdn,github,开源中国strackoverflow等社区的前辈,他们对开源社区分享,奉献让更多的开发者收益,在他们的肩膀上,我们这些菜鸟才能走的更远。
最后附上源码:
https://github.com/ccccccmd/ReCapcha
具体案例都在源代码中。