关系:
所有的关系都是指表与表之间的关系。
将实体与实体的关系,反应到最终数据库表的设计上来,可以将关系分成三种:一对一,一对多(多对一)和多对多。
一对一:
一张表的一条记录一定只能与另外一张表的记录进行对应,反之亦然。

数据库表设计成以上形式是符合要求的。其中姓名、性别、年龄、身高、体重属于常用数据;但是婚姻、籍贯、住址、联系人属于不常用数据。如果每次查询都是查询所有数据,不常用数据就会影响效率。
解决方案:
将常用数据和不常用数据分离,分成两张表进行存储。
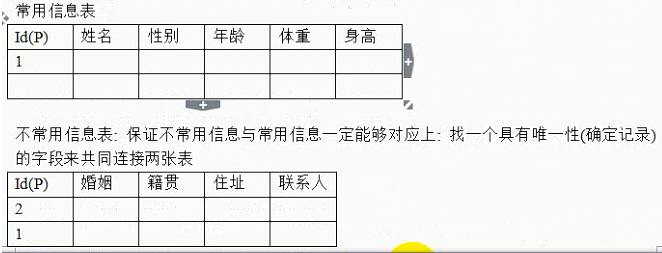
一个常用表中的一条记录,永远只能在一张不常用表中匹配一条记录;反过来,一个不常用表中的一天记录在常用表中也只能陪陪一条记录;一对一的关系。
一对多:
一张表中有一条记录,可以对应另外一张表中的多条记录;但反过来,另一张表中的一条记录只能对应第一张表中的一条记录;一对多或者多对一关系。
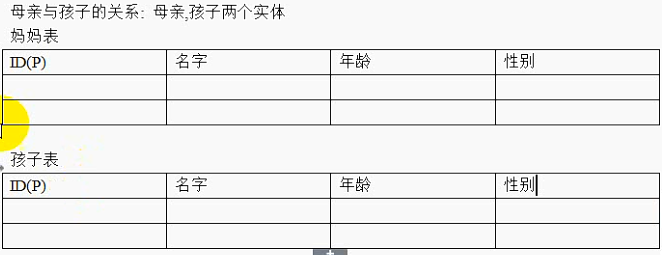
以上关系一个妈妈可以在多个孩子表中找到对应记录(也可能是一条);但是在一个孩子表中,只能找到一个妈妈,这是一种典型的一对多关系。
在上面设计中,解决了实体的设计表问题,但是没有解决关系问题,这样孩子是找不到妈妈的,妈妈也找不到孩子,解决方案:
在孩子表中增加一个字段指向妈妈表,因为孩子表的记录只能匹配到一条妈妈表的记录。

多对多:
一张表中(A)的一条记录能够对应另外一张表(B)中的多条记录,同时B表中的一条记录也能对应A表中的多条记录;多对多的关系。

以上设计方案:实现了实体的设计,但是没有维护实体的关系。一个老师教过多个学生,一个学生也被多个老师教过。
解决方案:
在学生表中增加老师字段:不管在哪张表中增加字段,都会出现一个问题,该字段要保存多个数据,而且是与其他表有关系的字段,不符合表的设计规范。所以增加一张新表,专门维护两张表之间的关系。


增加中间表之后,中间表与老师表形成一对多关系,而且中间表是多表,维护了能够唯一找到老师表的关系。同样,学生表与中间表也是一个一对多的关系,一对多的关系可以匹配到关联表之间的数据。

范式(Normal Format):
是一种离散数学中的知识,为了解决一种数据的存储于优化的问题,保存数据的存储之后,凡是能够通过关系寻找出来的数据,坚决不再重复存储,终极目标是为了减少数据的冗余。
范式是一种分层结构的规范,共分为六层,每一层都比上一层更加严格。若要满足下一层范式,前提是满足上一层范式。
六层范式:1NF,2NF,3NF,4NF,5NF,6NF。1NF是最底层,要求最低;6NF是最高层,要求最严格。
MySQL属于关系层数据库,有空间浪费,也是致力于节省存储空间,与范式所解决的问题不谋而合,在设计数据库的时候,会利用到范式来指导设计。
但是数据库不单是要解决空间问题,要保证效率问题;范式只为解决空间问题,所以数据库的设计又不可能完全按照范式的要求实现,一般情况下,只有前三种范式需要满足。
范式在数据库的设计当中是有指导意义,但不是强制规范。
1NF:
第一范式:在设计存储数据的时候,如果表中设计的字段存储的数据,在取出来使用之前还需要额外的处理(拆分),那么说明表的设计不满足第一规范。
第一范式要求字段的数据具有原子性:不可再分。
讲师代课时间:
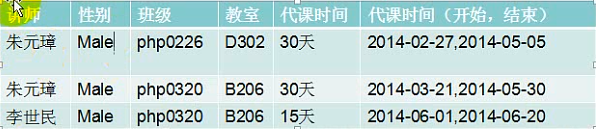
上课表设计不存在问题,但是如果需求是将数据查出来之后,要求显示一个老师从什么时候开始上课,到什么时候结课,需要将代课时间进行拆分,不符合1NF,数据不具有原子性,可以再拆分。
解决方案:将代课时间拆分为两个字段就能解决问题。

2NF:
第二范式:在数据表设计的过程中,如果有复合主键(多字段主键),且表中有字段并不是由整个主键来确定,而是依赖主键中的某个字段(主键部分),存在字段依赖主键的部分的问题,称之为部分依赖,第二范式就是要解决表设计不允许出现的部分依赖。
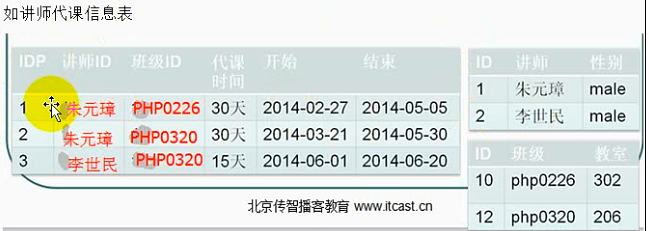
讲师代课表:

之上表中:因为讲师没有办法作为独立主键,需要结合班级才能作为主键(复合主键:一个老师在一个班永远只带一个阶段的课程),代课时间,开始和结束字段都与当前的代课主键(讲师和班级),但是性别并不依赖班级,教室不依赖讲师,性别只依赖讲师,教室只依赖班级,出现了性别和教室依赖主键中的一部分,部分依赖,不符合第二范式。


3NF:
要满足第三范式,必须满足第二范式
第三范式理论上讲,应该在一张表中的所有字段都应该直接依赖主键(逻辑主键:代表的是业务主键),如果表设计中存在一个字段,并不直接依赖主键,而是通过某个非主键字段依赖,最终实现依赖主键,把这种不是直接依赖主键,而是依赖非主键字段的依赖关系称之为传递依赖。第三范式就是要解决传递依赖的问题。

上表中:性别依赖讲师存在,讲师依赖主键;教室依赖班级,班级依赖主键;性别和教室都存在传递依赖。
解决方案:将存在传递依赖的字段,以及依赖的字段本身单独取出,形成一个单独的表,然后再续约对应的信息的时候,使用对应的实体表的主键加进来。

逆规范化:
有时候,在设计表的时候,如果一张表中有几个字段是需要从另外的表中去获取信息。理论上讲,的确可以获取到想要的数据,但是就是效率低一点。会刻意的在某些表中,不去保存另外的主键(逻辑主键),而是直接保存想要的数据信息,这样一来,在查询数据的时候,一张表可以直接提供数据,而不需要多张表查询(效率低),但是会导致数据冗余增加。
逆规范化:磁盘利用率与效率的对抗。