第一节:UTF-8和GBK编码概述
UTF-8 (8-bit Unicode Transformation Format) 是一种针对Unicode的可变长度字符编码,又称万国码,它包含全世界所有国家需要用到的字符,是国际编码,通用性强,是用以解决国际上字符的一种多字节编码。由Ken Thompson于1992年创建。UTF-8用1到4个字节编码UNICODE字符,它对英文使用8位/8Bit(即1个字节/1Byte),中文使用24位/24Bit(3个字节/3Byte)来编码。用在网页上可以同一页面显示中文简体繁体及其它语言(如日文,韩文)。
GBK (Chinese Internal Code Specification) 是汉字编码标准之一,全称《汉字内码扩展规范》,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准(GB2312共收录了7445个字符,包括6763个汉字和682个其它符号;GBK共收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字)。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示(注意,GB系列编码是利用了字节中的最高位和ASCII编码区分的,可以和ASCII码混用。所以全角模式下英文是2字节,半角模式英文还是1字节)。为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。
简单概况就是:
UTF-8英文1字节中文3字节,在编码效率和编码安全性之间做了平衡,适合网络传输,是理想的中文编码方式.
GBK英文1字节(半角1字节,全角2字节),中文2字节,GBK的范围比GB2312广,GBK兼容GB2312。
参考文章:
http://blog.csdn.net/mydriverc2/article/details/50525203
http://blog.csdn.net/liudajiang/article/details/41133077
http://www.cnblogs.com/xiaomia/archive/2010/11/28/1890072.html
第二节:UTF-8和GBK在Web传输中的区别
PHP示例代码:
$str='中文'; // 2个中文
echo strlen($str),','; // UTF-8长度是:6 (UTF-8编码: 1个中文3byte,2个中文加起来是6byte)
echo strlen(iconv('utf-8', 'GBK', $str)),','; // GBK长度是:4 (GBK编码:1个中文2byte,2个中文加起来是4byte)
$str='a0'; // 1个英文1个数字
echo strlen($str),','; // UTF-8长度是:2 (UTF-8编码: 1个英文或数字是1byte,1个英文和1个数字加起来是2byte)
echo strlen(iconv('utf-8', 'GBK', $str)),','; // GBK长度是:2 (GBK编码:1个英文或数字是1byte, 1个英文和1个数字加起来是2byte)
$str='E汉'; // 1个英文1个中文
echo strlen($str),','; // UTF-8长度是:4 (UTF-8编码: 1个中文3byte,1个英文1byte,加起来是4byte)
echo strlen(iconv('utf-8', 'GBK', $str)); // GBK长度是:3 (GBK编码:1个中文2byte,1个英文或数字是1byte, 加起来是3byte)
代码截图:

输出结果:
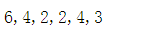
第三节:UTF-8和GBK在数据库存储中的区别
====================MySQL测试====================
MySQL示例代码(UTF8编码):
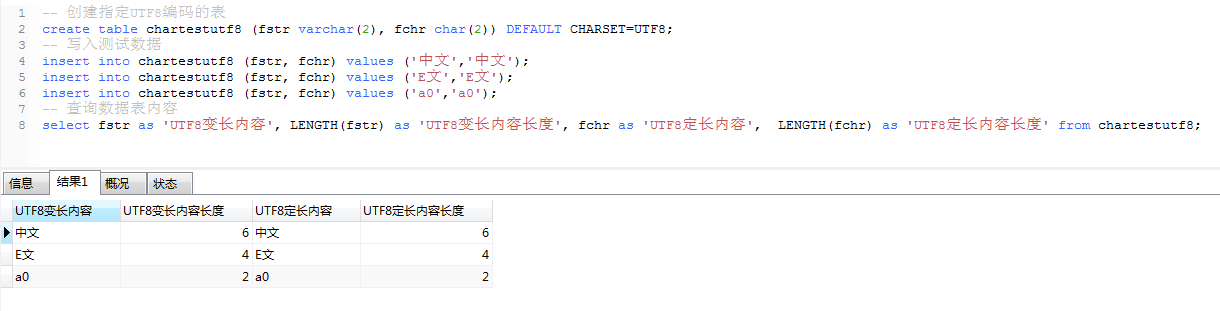
-- 创建指定UTF8编码的表
create table chartestutf8 (fstr varchar(2), fchr char(2)) DEFAULT CHARSET=UTF8;
-- 写入测试数据
insert into chartestutf8 (fstr, fchr) values ('中文','中文');
insert into chartestutf8 (fstr, fchr) values ('E文','E文');
insert into chartestutf8 (fstr, fchr) values ('a0','a0');
-- 查询数据表内容
select fstr as 'UTF8变长内容', LENGTH(fstr) as 'UTF8变长内容长度', fchr as 'UTF8定长内容', LENGTH(fchr) as 'UTF8定长内容长度' from chartestutf8;
代码截图:
内容说明:
UTF-8用1到4个字节编码UNICODE字符,英文一个字节/1byte (8位/8bit),中文三个字节/3byte (24位/24bit)
'中文' 2个汉字的长度是 3byte * 2 = 6byte
'E文' 1个英文+1个汉字的长度是 1byte + 3byte = 4byte
'a0' 1个英文+1个数字的长度是 1byte + 1byte = 2byte
MySQL示例代码(GBK编码):
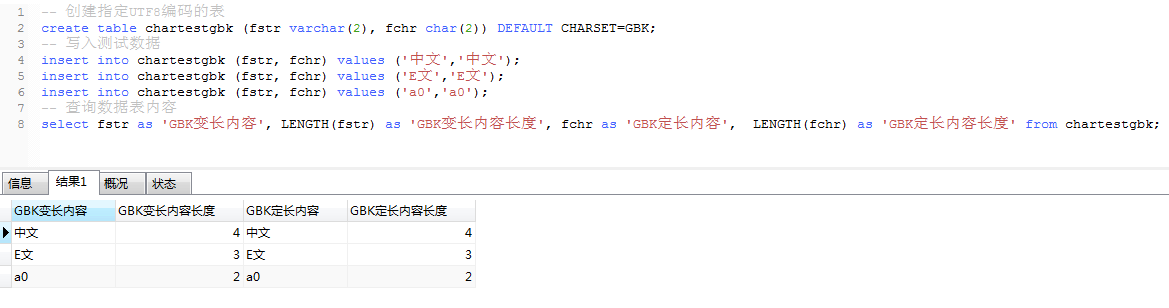
-- 创建指定GBK编码的表
create table chartestgbk (fstr varchar(2), fchr char(2)) DEFAULT CHARSET=GBK;
-- 写入测试数据
insert into chartestgbk (fstr, fchr) values ('中文','中文');
insert into chartestgbk (fstr, fchr) values ('E文','E文');
insert into chartestgbk (fstr, fchr) values ('a0','a0');
-- 查询数据表内容
select fstr as 'GBK变长内容', LENGTH(fstr) as 'GBK变长内容长度', fchr as 'GBK定长内容', LENGTH(fchr) as 'GBK定长内容长度' from chartestgbk;
代码截图:
内容说明:
GBK的文字编码用双字节来表示,即不论中、英文字符均使用双字节来表示
'中文' 2个汉字的长度是 2byte * 2 = 4byte
'E文' 1个英文+1个汉字的长度是 1byte + 2byte = 3byte
'a0' 1个英文+1个数字的长度是 1byte + 1byte = 2byte
补充说明:
1. varchar(M), 这里的M是指字符数,并不是字节数.占用的字节数与编码有关。
2. VARCHAR的最大实际长度由行定义的长度和使用的字符集确定,MySQL要求一个行的定义长度不能超过65535字节。字符类型若为GBK,每个字符最多占2个字节,则最大长度不能超过32766个字符;字符类型若为UTF8,每个字符最多占3个字节,最大长度不能超过21845个字符(一个中文、英文、数字等都算一个字符)。
参考文章:
http://www.oschina.net/question/199396_37127
http://blog.csdn.net/ppiao1970hank/article/details/6289647
http://www.cnblogs.com/fakis/archive/2011/03/07/1976532.html
====================SQL Server测试====================
SQL Server示例代码(Varchar):
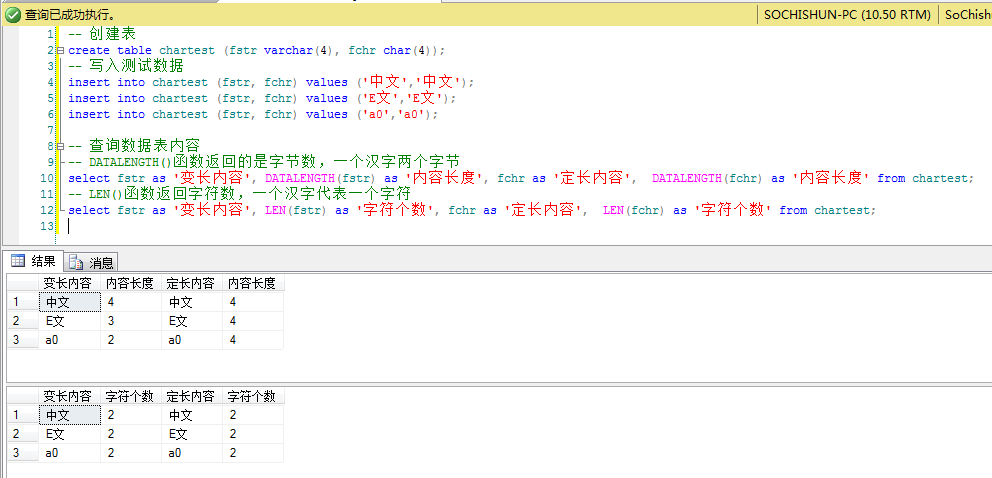
-- 创建表
create table chartest (fstr varchar(4), fchr char(4));
-- 写入测试数据
insert into chartest (fstr, fchr) values ('中文','中文');
insert into chartest (fstr, fchr) values ('E文','E文');
insert into chartest (fstr, fchr) values ('a0','a0');
-- 查询数据表内容
-- DATALENGTH()函数返回的是字节数,一个汉字两个字节
select fstr as '变长内容', DATALENGTH(fstr) as '内容长度', fchr as '定长内容', DATALENGTH(fchr) as '内容长度' from chartest;
-- LEN()函数返回字符数,一个汉字代表一个字符
select fstr as '变长内容', LEN(fstr) as '字符个数', fchr as '定长内容', LEN(fchr) as '字符个数' from chartest;
代码截图:
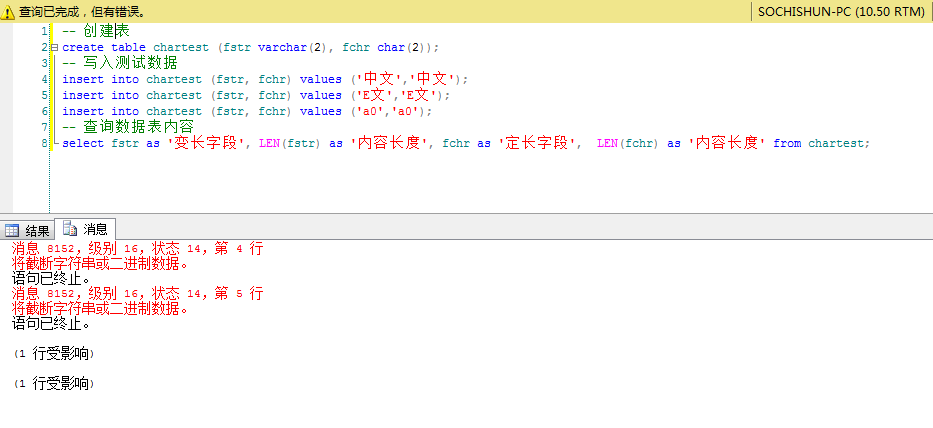
内容说明:
'中文' 2个汉字的长度是 2byte * 2 = 4byte,所以定义varchar(2)会提示将截断字符串或二进制数据的错误。
'E文' 1个英文+1个汉字的长度是 1byte + 2byte = 3byte
'a0' 1个英文+1个数字的长度是 1byte + 1byte = 2byte
SQL Server定长数据类型(char(n)),不足的补英文半角空格,所以查询出来的长度都是固定的。
SQL Server示例代码(NVarchar):
-- 创建表
create table chartestn (fstr nvarchar(2), fchr nchar(2));
-- 写入测试数据
insert into chartestn (fstr, fchr) values ('中文','中文');
insert into chartestn (fstr, fchr) values ('E文','E文');
insert into chartestn (fstr, fchr) values ('a0','a0');
-- 查询数据表内容
-- DATALENGTH()函数返回的是字节数,一个汉字两个字节
select fstr as '变长内容', DATALENGTH(fstr) as '内容长度', fchr as '定长内容', DATALENGTH(fchr) as '内容长度' from chartestn;
-- LEN()函数返回字符数,一个汉字代表一个字符
select fstr as '变长内容', LEN(fstr) as '字符个数', fchr as '定长内容', LEN(fchr) as '字符个数' from chartestn;
代码截图:
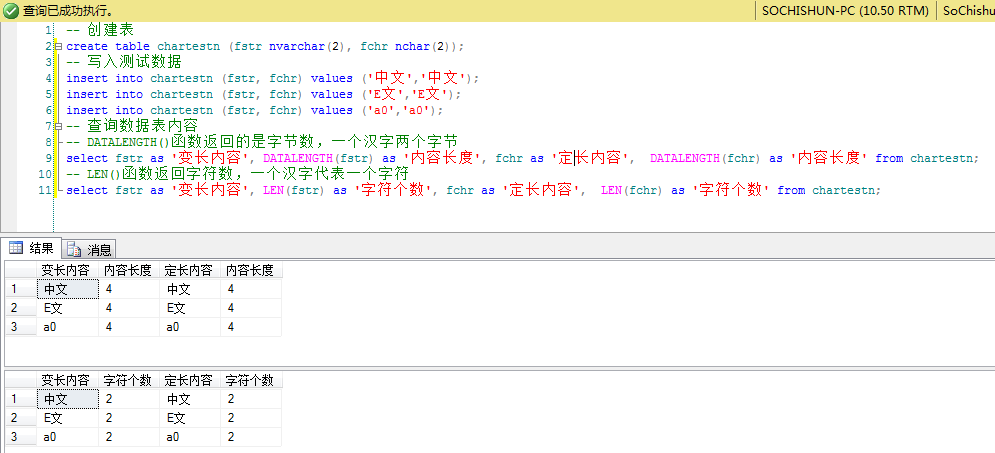
补充说明:
sql server中的Varchar和Nvarchar的区别:
1. Varchar按实际字节长度存储,1个汉字1字节,1个英文1字节,长度介于1和8000之间,存储大小为输入数据的字节的实际长度
2. Nvarchar按字符数量存储,不论汉字或英文,都是2字节,长度介于1与4000之间,存储大小是所输入字符个数的两倍(n前缀的,n表示Unicode字符,即所有字符都占两个字节)
3. 从存储方式上,nvarchar是按字符存储的,而 varchar是按字节存储的
4. 从存储量上考虑, varchar比较节省空间,因为存储大小为字节的实际长度,而 nvarchar是双字节存储
5. 如果你做的项目可能涉及不同国家语言之间的转换,建议用nvarchar,因为nvarchar是使用Unicode编码,会减少乱码的出现几率
6. Char/NChar固定长度数据类型,不足的补英文半角空格。
LEN()函数:返回给定字符串表达式的字符(而不是字节)个数,其中不包含尾随空格。(Len只返回字符数,一个汉字代表一个字符)
DATALENGTH()函数:返回任何表达式所占用的字节数。(Datalength返回的是字节数,一个汉字两个字节)
Len()不包含空格在内长度,而DATALENGTH()包含空格。
参考文章:
http://www.cnblogs.com/14lcj/archive/2012/07/08/2581234.html
http://blog.163.com/rihui_7/blog/static/212285143201211123342333/?NdsKey=246770
实际项目的应用:
1. 1个中文用UTF8编码是3字节(Byte),用GBK编码是2字节(Byte)。1个英文或数字不管什么编码都是1字节(属于ASCII编码)。
2. UTF8比GBK多使用1字节存储空间。UTF8可以存储包括其他任意国家语言的字符,而GBK仅限中文,但包含UTF8没有的中文生僻字。
3. MySQL数据库的varchar(N),N表示的是字符数量,而不是字节数量,占用的字节数和数据表使用的编码有关。(MySQL要求一个行的定义长度不能超过65535字节,因此varchar的长度理论上最大是65535字节,编码若为gbk,每个字符最多占2个字节,最大长度不能超过32766个字符;编码若为utf8,每个字符最多占3个字节,最大长度不能超过21845个字符,即不论字母、数字或汉字,只能存储21785个)
4. SQLServer数据库的nvarchar(N),N表示的是字符数量,但不论汉字还是英文,都是2字节,长度范围是1-4000,而varchar(N),N表示的是字节长度,1个汉字2个字节,1个英文或数字是1字节,长度范围是1-8000。(所以nvarchar(2)可以存储2个汉字,而varchar(2)只能存储1个汉字)
|
版权声明:本文采用署名-非商业性使用-相同方式共享(CC BY-NC-SA 3.0 CN)国际许可协议进行许可,转载请注明作者及出处。 |