1.如何配置各个节点之间无密码互通?
2.启动hadoop,看不到进程的原因是什么?
3.配置hadoop的步骤是什么?
4.有哪些配置文件需要修改?
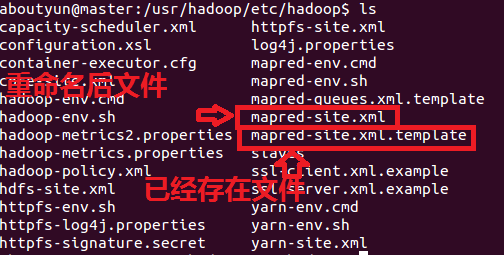
5.如果没有配置文件,该如何找到该配置文件?
6.环境变量配置了,但是不生效的原因是什么?
7.如何查看hadoop2监控页面

- sudo chown -R aboutyun:aboutyun mv.sh
sudo是linux系统管理指令,是允许系统管理员让普通用户执行一些或者全部的root命令的一个工具,如halt,reboot,su等等。这样不仅减少了root用户的登录 和管理时间,同样也提高了安全性。sudo不是对shell的一个代替,它是面向每个命令的。
2.chown-》change own的意思。即改变所属文件。对于他不了解的同学,可以查看:让你真正了解chmod和chown命令的用法
- tar zxvf hadoop-2.2.0_x64.tar.gz
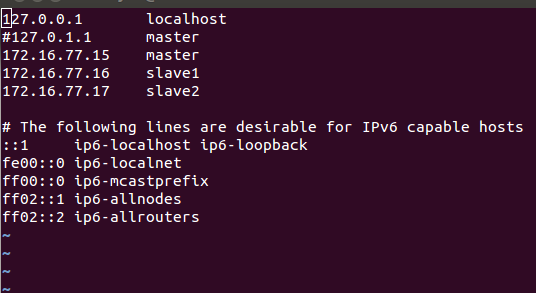
- vi /etc/hosts
- vi /etc/hostname

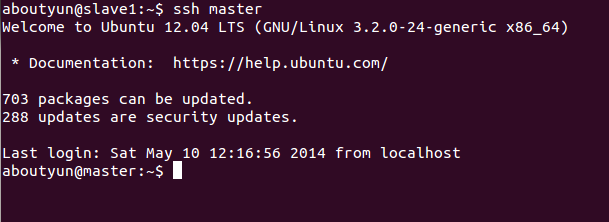
- ssh localhost

<ignore_js_op>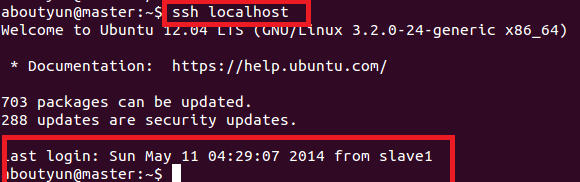
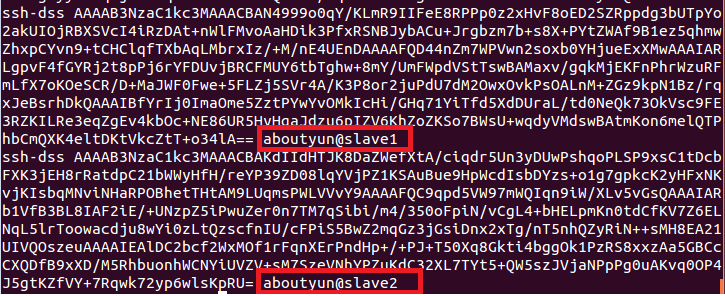
就是把工钥放到里面,然后本台机器就可以ssh无密码登录了。如果想彼此无密码登录,那么就需要把彼此的工钥(*.pub)放到authorized_keys里面
<ignore_js_op>
这里提供一个简单的方法:
通过下面命令
1.export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
通过cat命令,可以查看![]()
2.为了保证生效执行下面命令
- source /etc/environment
二、CLASSTH配置
上面只是配置了PATH,还需在配置CLASSTH
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
执行配置完毕
如果不起作用,采用通过下面配置:
java.sh配置
因为重启之后,很有会被还原,下面还需要配置java.sh
这里可以通过
cd /etc/profile.d
vi java.sh
把下面两行放到java.sh
export PATH=$PATH:/usr/java/jdk1.7.0_51/bin
export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib
保存。这样就配置完毕了。
- source java.sh
![]()
一、需要注意的问题
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/home/aboutyun/tmp</value>
- <description>Abase forother temporary directories.</description>
- </property>
- /home/aboutyun/tmp
- /home/zhangsan/tmp
<ignore_js_op>
hdfs-site.xml
上面讲完,我们开始配置
- tar zxvf hadoop-2.2.0_x64.tar.gz
- mv hadoop-2.2.0 hadoop
解压到/usr路径下

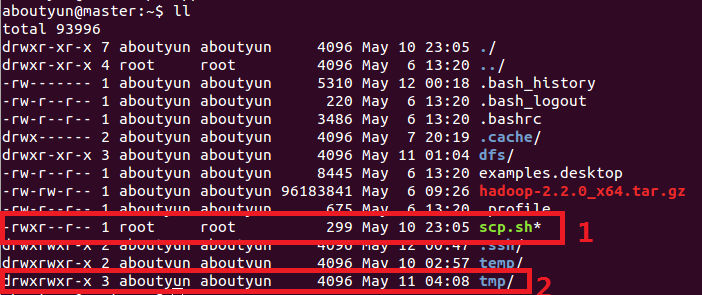
这里文件权限:创建完毕,你会看到红线部分,注意所属用户及用户组。如果不再新建的用户组下面,可以使用下面命令来修改:让你真正了解chmod和chown命令的用法
<ignore_js_op>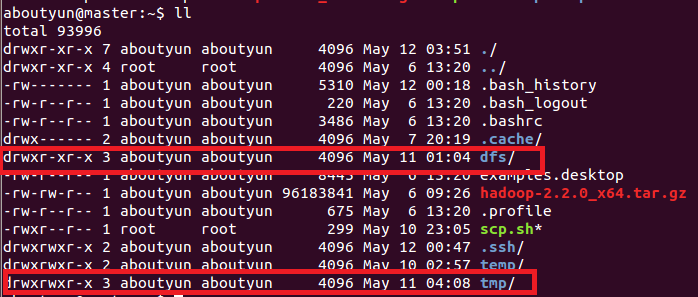
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://master:8020</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/home/aboutyun/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>hadoop.proxyuser.aboutyun.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.aboutyun.groups</name>
- <value>*</value>
- </property>
- </configuration>
- <configuration>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>master:9001</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/home/aboutyun/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/home/aboutyun/dfs/data</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <property>
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
- </configuration>
- <configuration>
- <property> <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
- </configuration>
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>master:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>master:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>master:8031</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>master:8033</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>master:8088</value>
- </property>
- </configuration>
- sudo scp -r /usr/hadoop aboutyun@slave1:~/
一、节点之间传递数据:第一步:vi scp.sh第二步:把下面内容放到里面(记得修改下面红字部分,改成自己的)#!/bin/bash#slave1scp /usr/hadoop/etc/hadoop/core-site.xml aboutyun@slave1:~/scp /usr/hadoop/etc/hadoop/hdfs-site.xml aboutyun@slave1:~/#slave2scp /usr/hadoop/etc/hadoop/core-site.xml aboutyun@slave2:~/scp /usr/hadoop/etc/hadoop/hdfs-site.xml aboutyun@slave2:~/第三步:保存scp.sh第四步:bash scp.sh执行二、移动文件夹:可以自己写了。
- vi /etc/environment

- hdfs namenode –format
- hadoop namenode format
- start-dfs.sh
namenodesecondarynamenode
- start-yarn.sh
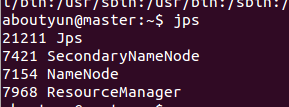
slave1有如下进程
<ignore_js_op>
然后我们输入:(这里有的同学没有配置hosts,所以输出master访问不到,如果访问不到输入ip地址即可)
- http://master:8088/
如何修改hosts:
win7 进入下面路径:
- C:WindowsSystem32driversetc
找打hosts
<ignore_js_op>
然后打开,进行如下配置即可看到
<ignore_js_op>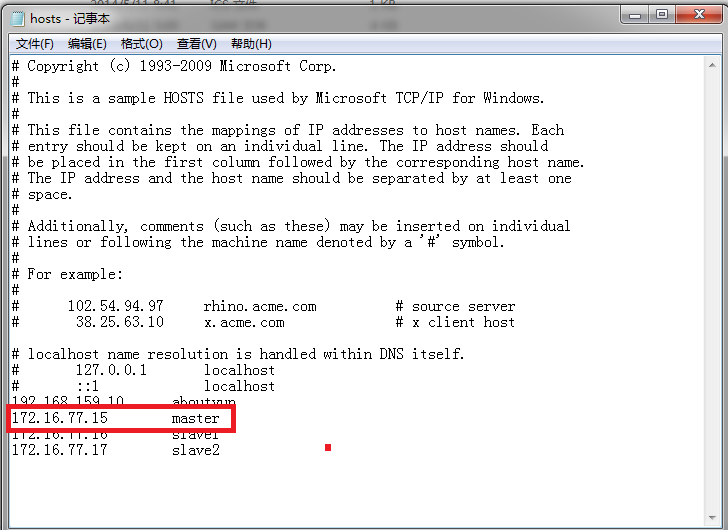
看到下图:
<ignore_js_op>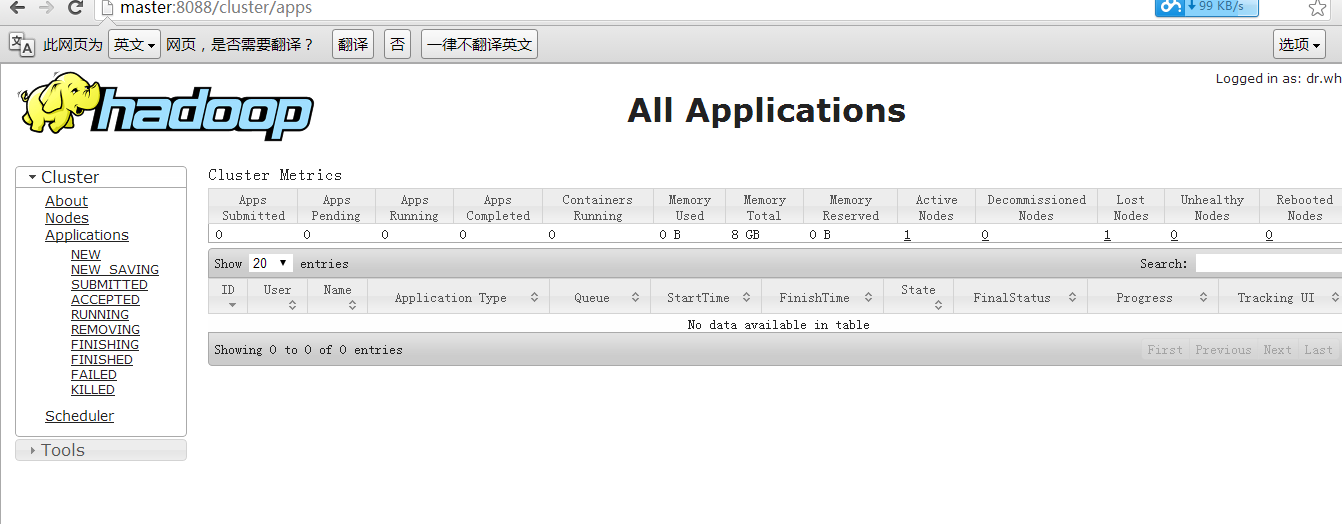
到此全部完毕。
使用hadoop集群,更详细内容,可以查看
hadoop2.X使用手册1:通过web端口查看主节点、slave1节点及集群运行状态
hadoop2.X使用手册2:如何运行自带wordcount
hadoop2.2运行mapreduce(wordcount)问题总结
本文链接
http://www.aboutyun.com/thread-7684-1-1.html