
背景
保证kafka高吞吐量的另外一大利器就是消息压缩。就像上图中的压缩饼干。
压缩即空间换时间,通过空间的压缩带来速度的提升,即通过少量的cpu消耗来减少磁盘和网络传输的io。
消息压缩模型
消息格式V1

kafka不会直接操作单条消息,而是直接操作一个消息集合。
消息格式V2:
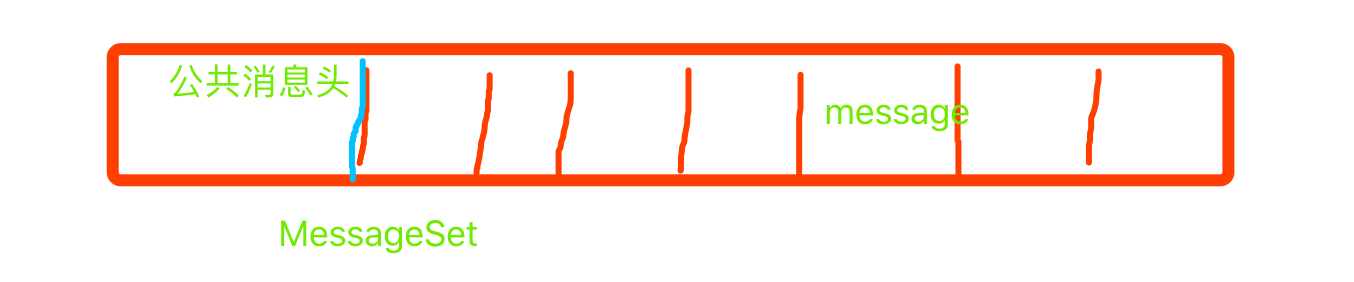
1, 抽取了消息的公共部分放到消息集合中;去掉每条消息的公共部分,减少了总体积。
2,消息的CRC校验由对每一条消息,移动到了对消息集合进行校验,减少了校验次数,节省了cpu;
3, 对单个消息进行压缩,放到消息的body字段 pk 对消息集合整个进行压缩 更好的压缩效果;
压缩过程模型

压缩算法比较
如何衡量一个压缩算法的好坏。

常见的压缩算法对比:
Zstandard 算法(简写为 zstd)。它是 Facebook 开源的一个压缩算法,能够提供超高的压缩比

启用压缩场景
如果cpu负载比较高,不适合启用压缩;
如果带宽不足,而cpu负载不高,最适合启用压缩,节约大量的带宽;
尽量避免消息格式不一致带来的解压缩消耗。
小结
压缩的目的是较少空间占用,带来传输速度的提升,但是需要消耗一定的cpu ;
是一种提高kafka消息吞吐量的有效办法。
本节回顾了新版的kafka是如何对消息进行压缩的,压缩和解压缩的流程是怎样的,
然后对比了常见的4种压缩算法,根据具体的使用场景来选择是否启用压缩,以及选择合适的压缩算法。
然后给出了压缩的配置参数,在producer和borker端都可以使用compression.type来设置。
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!
