
使用场景
大数据:数据量和速率激增,数据类型越来越复杂
应用开发:消息引擎,应用解耦,分布式存储,流处理
Kafka的体系结构
topic : 主题(消息的逻辑分类)
客户端: 细分为生产者(朝主题发送消息), 消费者(读取主题的消息);
服务端: broker (1 处理客户端发送和提供消费支持 2 消息持久化)
消息架构

1,一个主题可以划分为X个领导分区,分布在Y个的broker上;
2,每个领导分区有Z个副本,跟领导分布区在不同的broker上;(领导分区负责读写,随从分区负责复制领导分区的数据)
3,每个领导分区有A条消息,从0开始,依次增加;
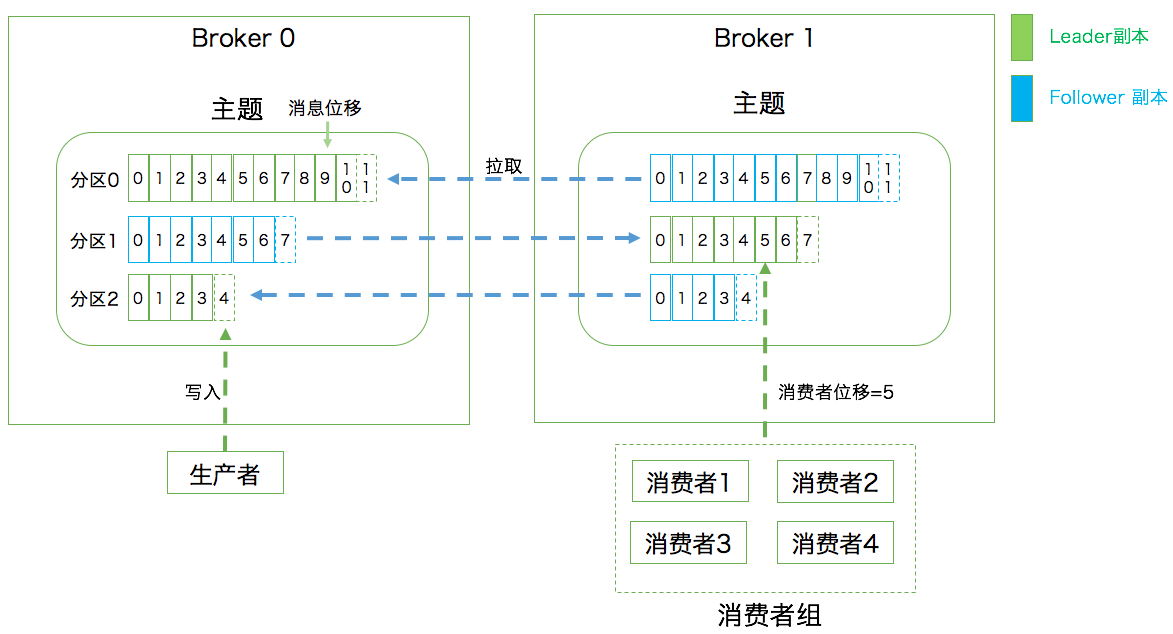
概念从小到大:
生产者 -》消息-》分区-》主题->broker (分区内部的offset)
消费者组-》消费者-》主题(消费者的offset)
持久化数据和回收数据
记录在日志文件里,按照顺序写的方式,io效率比较高;
日志文件是分段的 log segment , 当当前段用完,会分配新的日志段,然后有定时任务会定期回收可以回收的log segment ;
消费消息
如何防止消息被重复消费?
消费组:不同的消费者实体分配了不一样的分区。 一个分区对应了唯一的一个消费者。所以不会出现消息重复。
可靠性和性能
高可用
broker部署在不同的机器上;
备份机制,以分区为单位保存副本,副本分为leader rep, follower rep ; 分布在不同的broker上;
leader rep : 跟客户端交互,生产和消费消息;
follower rep: 复制leader的 rep 数据;
扩展性
分区: 一个主题分为多个分区,分区分布在不同的broker上,方便进行扩展。
高性能
消费高性能:消费组的消费者分配得到不同的分区,并行消费,并且增加或者减少消费者会自动rebalance,即重新分配分区;
生产高性能:分区在不同的broker,可以并发的写消息;
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!
