网络udp
socket的作用
进程指的是:运行的程序以及运行时用到的资源这个整体称之为进程
socket(简称 套接字) 是最通用的进程间通信的一种方式
创建socket
import socket socket.socket(AddressFamily, Type)
函数 socket.socket 创建一个 socket,该函数带有两个参数:
Address Family:可以选择 AF_INET(用于 Internet 进程间通信 表示IPv4协议) 或者 AF_INET6(表示IPv6协议 未来很快可能用上) 等
Type:套接字类型,可以是 SOCK_DGRAM(数据报套接字,主要用于 UDP 协议)或者 SOCK_STREAM(流式套接字,主要用于 TCP 协议)等
UDP和TCP是两种比较常见的套接字类型 UDP使用比较简单。
创建一个udp socket(tcp套接字)
import socket # 创建udp的套接字 s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # ...这里是使用套接字的功能(省略)... # 不用的时候,关闭套接字 s.close()
说明
套接字使用流程 与 文件的使用流程很类似
- 创建套接字
- 使用套接字收/发数据
- 关闭套接字
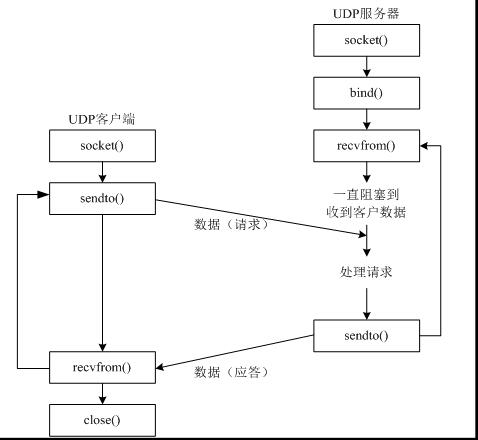
udp网络程序-发送、接收数据
创建一个基于udp的网络程序流程很简单,具体步骤如下:
- 创建客户端套接字
- 发送/接收数据
- 关闭套接字
代码如下:


#coding=utf-8 from socket import * # 1. 创建udp套接字 udp_socket = socket(AF_INET, SOCK_DGRAM) # 2. 准备接收方的地址 # '192.168.1.103'表示目的ip地址 # 8080表示目的端口 dest_addr = ('192.168.1.103', 8080) # 注意 是元组,ip是字符串,端口是数字 # 3. 从键盘获取数据 send_data = input("请输入要发送的数据:") # 4. 发送数据到指定的电脑上的指定程序中 udp_socket.sendto(send_data.encode('utf-8'), dest_addr) # 5. 关闭套接字 udp_socket.close()
python3编码转换
str->bytes:encode('utf-8') 编码
bytes->str:decode('utf-8') 解码
其中decode()与encode()方法可以接受参数,其声明分别为:
bytes.decode(encoding="utf-8", errors="strict")
- 其中 encoding是指在解码/编码(动词)过程中使用的字符编码(名词)
- errors是指错误的处理方案,errrors参数默认值是strict(严格的)意味着如果编解码出错将会抛出 UnicodeError;
- 如果想忽略编解码错误 可以将errors设置为ignore。
udp绑定信息
绑定示例
#coding=utf-8 from socket import * # 1. 创建套接字 udp_socket = socket(AF_INET, SOCK_DGRAM) # 2. 绑定本地的相关信息,如果一个网络程序不绑定,则系统会随机分配 local_addr = ('', 7788) # ip地址和端口号,ip一般不用写,表示本机的任何一个ip udp_socket.bind(local_addr) # 3. 等待接收对方发送的数据 recv_data = udp_socket.recvfrom(1024) # 1024表示本次接收的最大字节数 # 4. 显示接收到的数据 print(recv_data[0].decode('gbk')) # 5. 关闭套接字 udp_socket.close()
- bind()函数的作用就让操作系统不再默认分配的随机端口,而是使用参数指定的端口。
TCP简介
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为 TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
TCP特点:
- 面向连接
- TCP通信需要经过创建连接、数据传送、终止连接三个步骤。在通信开始之前,一定要先建立相关的链接,才能发送数据
- 可靠传输
- TCP采用发送应答机制:TCP发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功
- 超时重传:1.发送时启动定时器,如果没收到就重传. 2.TCP给每个包一个序号,序号也保证接收顺序 ,然后接收端发回一个相应的确认(ACK),如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。
- 错误校验: TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验
- 流量控制和阻塞管理: 流量控制用来避免主机发送得过快而使接收方来不及完全收下。
TCP与UDP的不同点
- 面向连接(确认有创建三方交握,连接已创建才作传输。)
- 有序数据传输
- 重发丢失的数据包
- 舍弃重复的数据包
- 无差错的数据传输
- 阻塞/流量控制
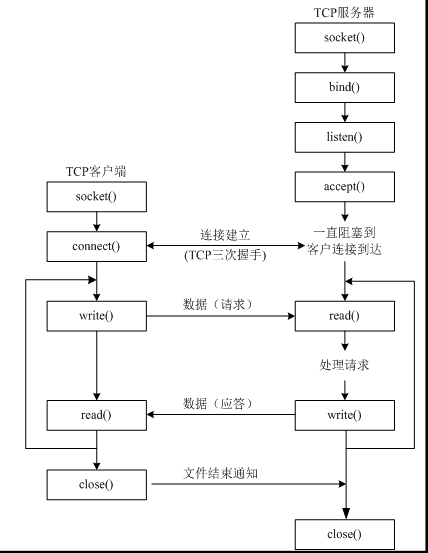
tcp客户端构建流程
from socket import * # 创建socket tcp_client_socket = socket(AF_INET, SOCK_STREAM) # 目的信息 server_ip = input("请输入服务器ip:") server_port = int(input("请输入服务器port:")) # 链接服务器 tcp_client_socket.connect((server_ip, server_port)) # 提示用户输入数据 send_data = input("请输入要发送的数据:") tcp_client_socket.send(send_data.encode("gbk")) # 接收对方发送过来的数据,最大接收1024个字节 recvData = tcp_client_socket.recv(1024) print('接收到的数据为:', recvData.decode('gbk')) # 关闭套接字 tcp_client_socket.close()
tcp服务器
- socket创建一个套接字
- bind绑定ip和port
- listen使套接字变为可以被动套接字
- accept取出一个客户端连接 用以服务
- recv/send接收发送数据
from socket import * # 创建socket tcp_server_socket = socket(AF_INET, SOCK_STREAM) # 本地信息 address = ('', 7788) # 绑定 tcp_server_socket.bind(address) # 使用socket创建的套接字默认的属性是主动的,使用listen将其变为被动的,这样完成之后 下一步就可以接受accept别人的连接connect请求了 tcp_server_socket.listen(128) # 如果有新的客户端来链接服务器,那么就产生一个新的套接字专门为这个客户端服务 # client_socket用来为这个客户端服务 # tcp_server_socket就可以省下来专门等待其他新客户端的链接 client_socket, clientAddr = tcp_server_socket.accept() # 接收对方发送过来的数据 recv_data = client_socket.recv(1024) # 接收1024个字节 print('接收到的数据为:', recv_data.decode('gbk')) # 发送一些数据到客户端 client_socket.send("thank you !".encode('gbk')) # 关闭为这个客户端服务的套接字,只要关闭了,就意味着为不能再为这个客户端服务了,如果还需要服务,只能再次重新连接 client_socket.close()
tcp注意点
- tcp服务器中通过listen可以将socket创建出来的主动套接字变为被动的
- 当客户端需要链接服务器时,就需要使用connect进行链接,udp是不需要链接的而是直接发送,但是tcp必须先链接,只有链接成功才能通信
- 当一个tcp客户端连接服务器时,服务器端会有1个新的套接字,这个套接字用来标记这个客户端,单独为这个客户端服务
- listen后的套接字是被动套接字,用来接收新的客户端的连接请求的,而accept返回的新套接字是标识这个新客户端的
- 关闭listen后的套接字意味着被动套接字关闭了,会导致新的客户端不能够链接服务器,但是之前已经链接成功的客户端正常通信。
- 关闭accept返回的套接字意味着这个客户端已经服务完毕
- 当客户端的套接字调用close后,服务器端会recv解阻塞,并且返回的长度为0,因此服务器可以通过返回数据的长度来区别客户端是否已经下线;同理 当服务器断开tcp连接的时候 客户端同样也会收到0字节数据。
多任务-线程
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务在同一时间段执行。
并行:指的是多核cpu情况下,多个任务的一些任务往往是在同一时间点执行的。
使用threading模块
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
# 创建线程的执行计划 target指定线程执行的函数 thd = threading.Thread(target=sing) # 启动线程的执行计划 - 创建并且运行子线程 thd.start()
# 查看当前进程内部的所有存活的线程列表
threading.enumerate()
多线程在调度执行的时候 顺序是不确定的 无序的
target指定线程执行的函数 args指定函数运行时所需的参数<元组>
thd = threading.Thread(target=say_sorry, args=(i,))
多线程共享全局变量
创建线程第二种方式:
继承子Thread类 实现启动的run方法 创建子类对象 .start()"
import threading import time class MyThread(threading.Thread): """继承子Thread类 实现启动的run方法 创建子类对象 .start()""" def run(self): """run方法会在子线程执行的时候自动调用""" while True: print("runnnnnn") time.sleep(1) if __name__ == '__main__': # 创建子线程执行计划 mt = MyThread() # 启动子线程的创建和执行 mt.start() while True: print("这是主线程") time.sleep(1)
资源竞争问题
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
解决办法:
创建一把互斥锁 能够保证在任意时间点只有一个线程能够成功获取. 如果已经被锁定 还有一个新任务需要这把锁 默认会这个新任务阻塞等待
lock = threading.Lock()
死锁问题 代码
import time import threading g_number = 0 """死锁是怎么产生的 如何解决死锁问题""" def worker1(lock1): global g_number for i in range(1000000): # 尝试加锁 如果没有被锁定就能成功锁定 如果已经被锁定 那么将会阻塞当前线程 直到锁被释放 # 默认情况下 默认参数为True就会阻塞 # 返回值表示有没有成功获取到锁 如果参数是False表示不阻塞获取锁资源 # 表示阻塞等待 最多等3s # if lock1.acquire(True, 3): if lock1.acquire(True): # 不阻塞等待获取锁 如果锁未锁定就获取 如果被锁定就直接继续执行 g_number += 1 # 释放锁资源 lock1.release() else: print("没有成功获取到锁") time.sleep(1) def worker2(lock1): global g_number for i in range(1000000): # print("in worker2 %d" % g_number) lock1.acquire() g_number += 1 lock1.release() if __name__ == '__main__': # 创建一把互斥锁 能够保证在任意时间点只有一个线程能够成功获取 # 如果已经被锁定 还有一个新任务需要这把锁 默认会这个新任务阻塞等待 # 创建锁 lock = threading.Lock() w1 = threading.Thread(target=worker1, args=(lock,)) w1.start() w2 = threading.Thread(target=worker2, args=(lock,)) w2.start() w1.join() w2.join() print("运算结果是%d" % g_number)
同步就是协同步调,按预定的先后次序进行运行
进程
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
进程间通信-Queue
使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序