---每一模式的出现都是为了解决某一种或某一类问题,或者对某种对象间的耦合关系进行解耦合,使紧耦合变成松耦合的关系。
1.前言(解耦过程)
当我们阅读了之前的“简单工厂”那篇读书笔记之后,很多朋友都会有这样类似的一个问题就是---为什么笔记中只提到简单工厂的优点而且没有提到缺点呢? 这里将和大家一起分析简单工厂的缺点或者遗留的问题:
当我们习惯于简单工厂之后,都很喜欢把简单工厂应用到自己的项目中,比如最简单的应用就是创建数据库连接或者创建服务层接口等。我们用久了会发现一个问题就是:
我们需求是不可能一直不变的,比如就拿“简单工厂”中的水果示例来说:
我们已经有了一个苹果类、葡萄类、香蕉类,那如果客户想吃梨子呢?怎么办?
我们就马上会想到 我添加一个梨子的类就可以了,代码如下:
 View Code
View Code 
2 {
3 public string Name { get; set; }
4 public string Skin { get; set; }
5
6 public void Display()
7 {
8 Console.WriteLine("我是梨子");
9 }
10 }
然后在简单工厂中添加一个创建梨子的办法,如果是参数工厂(简单工厂中的工厂,靠接收来的参数创建对象)的话, 那更好办,在方法中添加一个判断条件IF-ELSE,然后实例化下梨子的对象就可以了,那以后想要别的呢?难道一个个添加么?
简单工厂代码:
View Code 2 {
3 public IFruit ProvideApple()
4 {
5 return new Apple { Name = "苹果", Skin = "Green" };
6 }
7 public IFruit ProvideBanana()
8 {
9 return new Banana { Name = "香蕉", Skin = "Yellow" };
10 }
11 public IFruit ProvideGrape()
12 {
13 return new Grape { Name = "葡萄", Skin = "Grape" };
14 }
15
16 public IFruit ProvidePear()
17 {
18 return new Pear { Name = "梨子", Skin = "Pear" };
19 }
20 }
参数工厂代码:
View Code 2 {
3 public IFruit ProvideFruit(string fruitName)
4 {
5 IFruit refFruit = null;
6
7 if ("Apple".Equals(fruitName))
8 {
9 refFruit = new Apple { Name = "苹果", Skin = "Green" };
10 }else if ("Banana".Equals(fruitName))
11 {
12 refFruit = new Banana { Name = "香蕉", Skin = "Yellow" };
13 }else if ("Grape".Equals(fruitName))
14 {
15 refFruit = new Grape { Name = "葡萄", Skin = "Grape" };
16 }else if ("Pear".Equals(fruitName))
17 {
18 refFruit = new Pear { Name = "梨子", Skin = "Pear" };
19 }
20
21 return refFruit;
22 }
23 }
从上面代码中看出,无论是简单工厂还是参数工厂他们都无法解决的问题就是每次有新产品出现的时候,它们必须做两件事:第一件是添加新产品(这里就是Pear类),第二件 是他们都会修改工厂对象里面的逻辑(添加一个创建方法或者修改方法中的判断逻辑),从上面问题中可以看出,第二件事情违背了开闭原则(对扩展开放,对修改关闭)。
我们再观察下简单工厂结构图
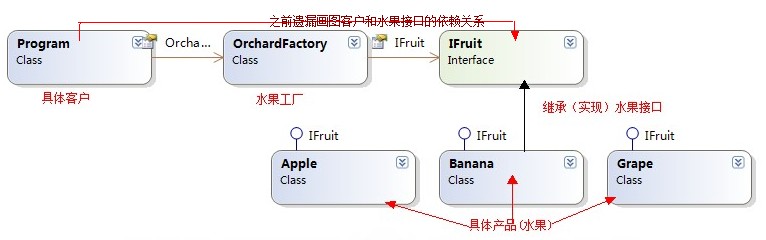
图1-1
从上面结构图中看到,我们简单工厂本来依赖是客户跟具体实现之间紧耦合,然后修改后变成客户依赖于工厂和水果接口,这里我们得到一个提示就是,我们应该依赖于接口,我们 就会想到一句话:“要针对接口编程,而不是针对实现编程”。我们尝试去定义一个接口,我们想到了一个办法就是,我们可以定义一个抽象(接口或者抽象类),这里为什么要定义一个这样的抽象?因为抽象对我们来说是稳定的,这样我们客户端依赖于抽象,而不是依赖于具体的工厂,每个具体工厂都实现抽象工厂中创建的产品方法。
抽象接口代码如下:
View Code 2 {
3 IFruit CreateFriut();
4 }
具体实现工厂代码如下:
View Code 2 /// 苹果工厂
3 /// </summary>
4 public class AppleFactory:IFactory
5 {
6 public IFruit CreateFriut()
7 {
8 return new Apple { Name = "苹果", Skin = "Green" };
9 }
10 }
11
12 /// <summary>
13 /// 香蕉工厂
14 /// </summary>
15 public class BananaFactory:IFactory
16 {
17 public IFruit CreateFriut()
18 {
19 return new Banana { Name = "香蕉", Skin = "Yellow" };
20 }
21 }
22
23 /// <summary>
24 /// 葡萄工厂
25 /// </summary>
26 public class GrapeFactory:IFactory
27 {
28 public IFruit CreateFriut()
29 {
30 return new Apple { Name = "葡萄", Skin = "Purple" };
31 }
32 }
33
34 /// <summary>
35 /// 梨子工厂
36 /// </summary>
37 public class PearFactory:IFactory
38 {
39 public IFruit CreateFriut()
40 {
41 return new Apple { Name = "梨子", Skin = "LightYellow" };
42 }
43 }
代码结构图:
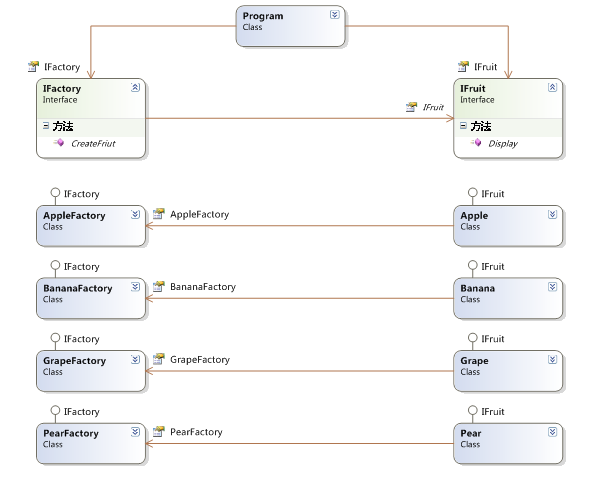
图1-2
从以上结构图中可以看出,客户依赖于抽象工厂和抽象产品,刚刚的步骤其实就是把客户跟工厂的紧耦合关系,解耦到松耦合关系。把客户的对具体工厂的依赖转移到了抽象工厂,又因为抽象是稳定的,所以解决了刚刚上面出现的问题。这里用到了一个设计模式中很重要的原则就是:依赖倒转原则,要依赖于抽象,不要依赖具体类。这里依赖大家都很好理解,但是倒转是如何理解的?
在Head First设计模式中见到一般的OO设计思路是低层组件跟依赖于低层组件的抽象,然后高层主件也依赖相同的抽象。 但这里工厂(高层组件)依赖于IFruit接口(低层组件),而具体的产品如苹果(低层组件)也依赖于IFruit接口(高层组件)。这样就是倒转了依赖关系。
这样就引出了一个设计模式“工厂方法模式”。
2.概要
什么是工厂方法:是定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法让类把实例化推迟到了子类。
工厂方法模式是一种创建型模式。
3.结构图分析:
图1-1 简单工厂模式结构图(补充了之前简单工厂中未画出客户跟抽象水果的依赖关系)
图1-2 工厂方法模式结构图:把简单工厂中的客户与具体工厂的紧耦合关系转移到了客户对抽象工厂的依赖,因为抽象是稳定的,所以可以解决添加新产品,而修改工厂类的问题。
4.目的:
工厂方法的目的在于:
从依赖关系的角度看:对客户跟具体产品之间的关系进行解耦,让他们变成松耦合关系,而把紧耦合的关系转移到抽象工厂。
从代码的角度看:解决简单工厂违反开闭原则的问题,解决了添加新产品的时候,不用去修改工厂类的问题。
5.使用场合:
从抽象角度来看满足产品请求者、产品提供者、提供相同父类或接口的不同产品(同一产品族)。如果存在以上关系就可以用简单工厂。但这里需要注意的是,如果请求者的请求, 这种情况下比较适合。也就是说简单工厂是创建是类似于数据库连接池之类的,因为数据库只有固定的几种,所以需求相对来说比较稳定,修改几率比较小,所以可以用简单工厂。 但如果用来创建服务接口的话就不是很适应,比如我这里有一个用户验证接口,我开发一段时间之后需求说需要提供一个日志功能,那么服务层就要添加一个日志接口,因为系统模块的数量跟需求有关,经常变换,所以接口的数量也经常变换。所以对工厂是修改频率会很高。所以用工厂方法比较合适。
从实际应用来看:适用于如数据库创建连接池,也可以和其他设计模式一起适用。
6.附加代码:点击下载