第二周笔记---「时序数据」和「比例数据」的可视化
本周主题:图标选择。
学习目标:
- 了解时序数据的特点,熟练掌握不同类型的时序数据分别适合的图表类型;
- 了解比例型数据可视化的目的,学会根据数据集的特征去选择合适的图表;
- 实践:从给定的4个数据集中挑选两个,自行选择合适图表并进行可视化呈现;
1.大纲
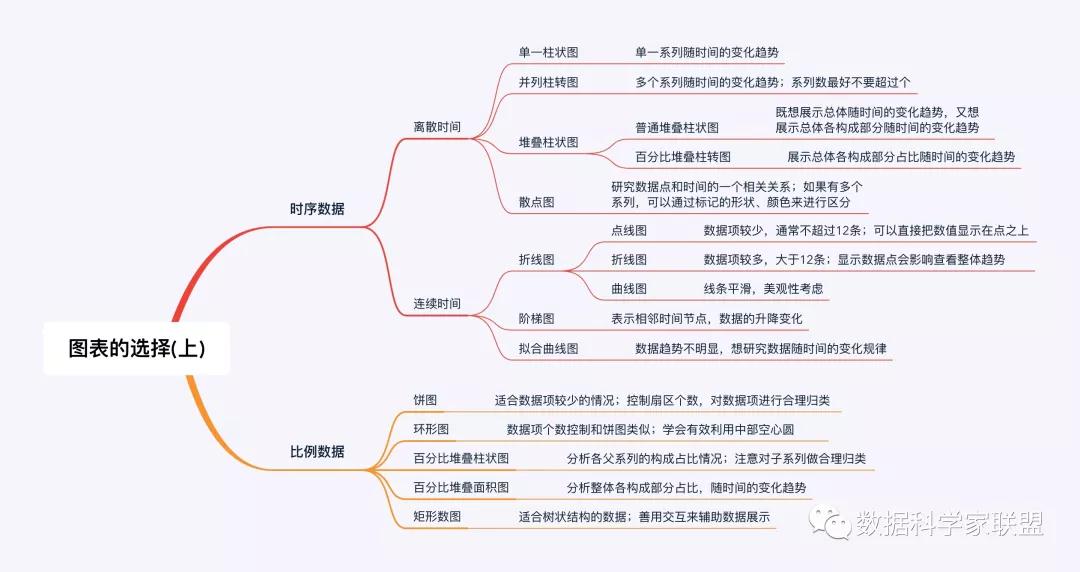
转载自木东居士
2.时序可视化
时序数据是指任何随着时间而变化的数据,如一天中气温随时间变化。(可用于时间序列分析)
前提,了解时间具有的特征:
- 有序性:时间都是有序的,事件有先后顺序;
- 周期性:许多自然或商业现象都有循环规律,如季节等周期性的循环;
- 结构性:时间的尺度可以按照年,季度,月,周,日,时,分,秒等去切割。
时间数据按是否连续可分为:离散型时间和连续型时间。
2.1 离散时间的可视化
由于下面的数据没有找到合适的,所以没有自由发挥了.
定义:离散时间:数据来源于具体的时间点或者时间段,而且时间数据的可能取值时有限的。
适用图形:柱状图,堆叠柱状图,散点图。
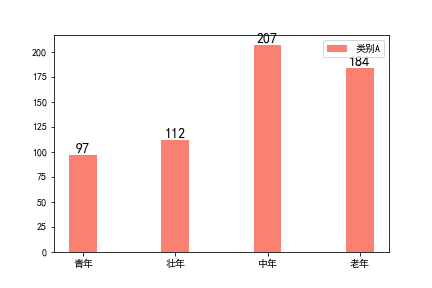
(1)单一柱状图
适用场景
- 适合表示离散时间数据的趋势,而且数据条个数一般不超过12条.
- 适用于但类别数据的时间趋势表示,即系列值单一的数据.
图片展示;
代码展示:
# 单一柱状图
plt.rcParams['font.sans-serif']=['SimHei']#设置字体以便支持中文
x = np.arange(4)#柱状图在横坐标上的位置
#列出你要显示的数据,数据的列表长度与x长度相同
y = age_num.values()
bar_width=0.3#设置柱状图的宽度
tick_label=age_num.keys()
# 记上标签,贴上数值
for a,b in zip(x,y):
plt.text(a,b,'%.0f'%b,ha = 'center',va = 'bottom',fontsize=14) # fontsize是字体
#绘制单一柱状图
plt.bar(x,y,bar_width,color='salmon',label='类别A')
plt.legend()#显示图例,即label
plt.xticks(x,tick_label)#显示x坐标轴的标签,即tick_label,调整位置,使其落在直方图中间位置
plt.savefig('squares.png') # 保存为squares.png
plt.show()
不适用场景:
- 连续时间的变化趋势;
- 数据条过多的离散时间的趋势展示(可以升维,划分更大的类)
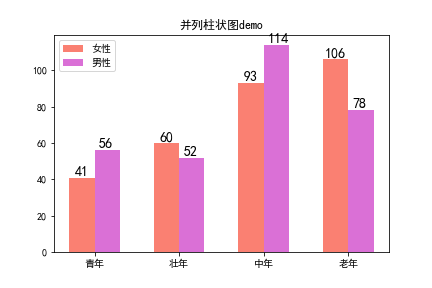
(2)并列柱状图
要对比同意离散时间多个系列的情况,考虑使用并列柱状图,注意柱状图通常不超过三条,否则效果不好.
图示:
代码:
# 并列柱状图
# 考虑将性别和年龄进行对比
x=np.arange(4)#柱状图在横坐标上的位置
#列出你要显示的数据,数据的列表长度与x长度相同
y1= [i[1] for i in ageSexCount.items() if i[0][1] == "FEMALE"]
y2= [i[1] for i in ageSexCount.items() if i[0][1] == "MALE"]
bar_width=0.3#设置柱状图的宽度
tick_label=age_num.keys()
#绘制并列柱状图
plt.title("并列柱状图demo")
plt.bar(x,y1,bar_width,color='salmon',label='女性')
plt.bar(x+bar_width,y2,bar_width,color='orchid',label='男性')
# 记上标签,贴上数值
for a,b in zip(x,y1):
plt.text(a,b,'%.0f'%b,ha = 'center',va = 'bottom',fontsize=14) # fontsize是字体大小
for a,b in zip(x,y2):
plt.text(a+0.2,b,'%.0f'%b,ha = 'left',va = 'bottom',fontsize=14) # fontsize是字体大小,通过不断调整a和b的大小调整标签位置
plt.legend()#显示图例,即label
plt.xticks(x+bar_width/2,tick_label)#显示x坐标轴的标签,即tick_label,调整位置,使其落在两个直方图中间位置
plt.savefig("demo2.png")
plt.show()
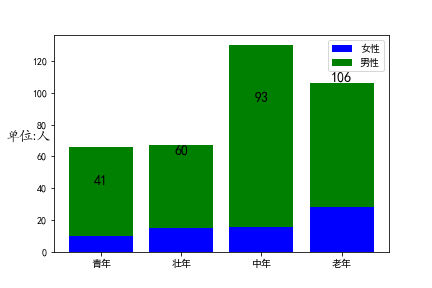
(3)堆叠柱状图
单一柱状图展示各个离散时间点,我们想知道总体构成的时候就需要引入堆叠柱状图.
- 普通柱状图,展示实际体量;
- 百分比堆叠柱状图,展示相对体量.
1)普通堆叠柱状图
普通堆叠柱状图,整体的构成部分,最好不要超过5项。若实际构成项大于5个时,需要做适当的归类,以保证图表重点突出。
图示:
代码:
# 堆叠柱状图
# 这里不能用dict_keys,只能转化成list
name_list = [i for i in age_num.keys()]
num_list1 = [i[1] for i in ageSexCount.items() if i[0][1] == "FEMALE"]
num_list2 = [i[1] for i in ageSexCount.items() if i[0][1] == "MALE"]
z1 = plt.bar(range(len(num_list)), num_list1, label='女性', fc='b')
z2 = plt.bar(range(len(num_list)), num_list2, bottom=num_list, label='男性', tick_label=name_list, fc='g')
plt.ylabel("单位:人", # 坐标轴文本标签
fontproperties="stkaiti", # 中文字体
rotation="horizontal", # 文本方向,还可以为vertical(默认)
fontsize = 14, # 字号
verticalalignment = "bottom", # 设置垂直对齐,还可以为top或center
horizontalalignment = "center" # 还可以为left或者right
)
# 显示高度
for a,b in zip(x,y1):
plt.text(a,b,'%.0f'%b,
ha = 'center',
va = 'bottom',# va可以为bottom,center,top
fontsize=14) # fontsize是字号
plt.legend()
plt.savefig("demo3.png")
plt.show()
# 堆叠不太熟悉,似乎有点问题
2)百分比堆叠柱状图
百分比python不太会做,只能用excel或者tableau进行加工了.这里借助别人的例子.
展示:
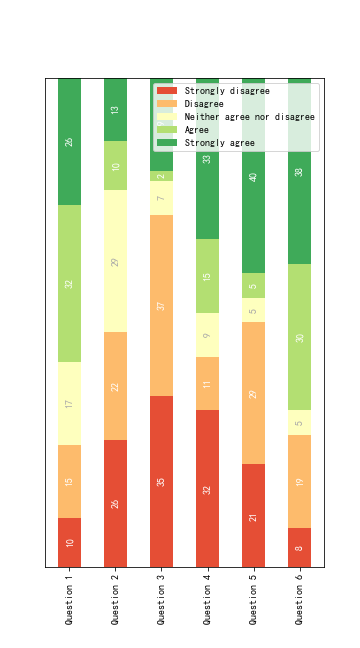
代码:
import numpy as np
import matplotlib.pyplot as plt
category_names = ['Strongly disagree', 'Disagree',
'Neither agree nor disagree', 'Agree', 'Strongly agree']
results = {
'Question 1': [10, 15, 17, 32, 26],
'Question 2': [26, 22, 29, 10, 13],
'Question 3': [35, 37, 7, 2, 19],
'Question 4': [32, 11, 9, 15, 33],
'Question 5': [21, 29, 5, 5, 40],
'Question 6': [8, 19, 5, 30, 38]
}
def survey(results, category_names):
labels = list(results.keys())
# 获取标签
data = np.array(list(results.values()))
# 获取具体数值
data_cum = data.cumsum(axis=1)
# 逐项加和
category_colors = plt.get_cmap('RdYlGn')(np.linspace(0.15, 0.85, data.shape[1]))
"""
在cmmap中取出五组颜色
category_colors:
[[0.89888504 0.30549789 0.20676663 1. ]
[0.99315648 0.73233372 0.42237601 1. ]
[0.99707805 0.9987697 0.74502115 1. ]
[0.70196078 0.87297193 0.44867359 1. ]
[0.24805844 0.66720492 0.3502499 1. ]]
"""
print(category_colors)
# 常见颜色序列, 在cmap中取色
fig, ax = plt.subplots(figsize=(5, 9))
# 绘图
# ax.invert_xaxis()
# 使其更符合视觉习惯,index本身从下到上
ax.yaxis.set_visible(False)
ax.set_xticklabels(labels=labels, rotation=90)
# 不需要可见
ax.set_ylim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
heights = data[:, i]
# 取第一列数值
starts = data_cum[:, i] - heights
# 取每段的起始点
ax.bar(labels, heights, bottom=starts, width=0.5,
label=colname, color=color)
xcenters = starts + heights / 2
r, g, b, _ = color
text_color = 'white' if r * g * b < 0.5 else 'darkgrey'
for y, (x, c) in enumerate(zip(xcenters, heights)):
ax.text(y, x, str(int(c)), ha='center', va='center',
color=text_color, rotation = 90)
ax.legend()
return fig, ax
survey(results, category_names)
plt.show()
(3)散点图
散点图一般表示两个变量之间的相关关系. 表示离散时间数据的时候,其表达的是某一变量随时间的变化关系.
柱状图是用高度作为数值的映射,而散点图是用位置来作为数值的视觉通道.
图示
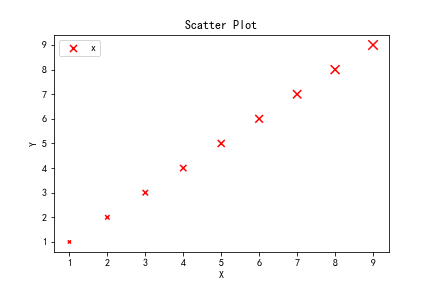
代码
#产生测试数据
x = np.arange(1,10)
y = x
fig = plt.figure()
ax1 = fig.add_subplot(111)
#设置标题
ax1.set_title('Scatter Plot')
#设置X轴标签
plt.xlabel('X')
#设置Y轴标签
plt.ylabel('Y')
#画散点图
sValue = x*10
ax1.scatter(x,y,s=sValue,c='r',marker='x')
#设置图标
plt.legend('x1')
#显示所画的图
plt.savefig("demo5.png")
plt.show()
2.2 连续时间
连续时间:连续时间数据的可视化和离散时间数据的可视化相似. 因为就算数据连续的,我们采集的数据大部分是离散且有限.
可以看出四种趋势:长期性趋势,季节性趋势,周期性趋势,不规则波动.
(1)折线图
折线图用于显示数据在一个连续的时间间隔或者时间跨度的变化. 在折线图中,一般水平轴(x轴)表示时间的推移,并且间隔相同,而垂直轴(y轴)代表不同时刻的数据的大小.
折线图包括:点线图,折线图,曲线图.
- 点线图:当数据集中的数据项有限,不超过12个小时,采用此种点线图比较合适.
- 折线图:当数据集中的数据项比较多,大于12条时,采用点线图,会让整条线上的点很密集,影响看数据的趋势,采用折线图;
- 曲线图:相比折线图,曲线图相邻节点的连线更加平滑.
点线图
图示:
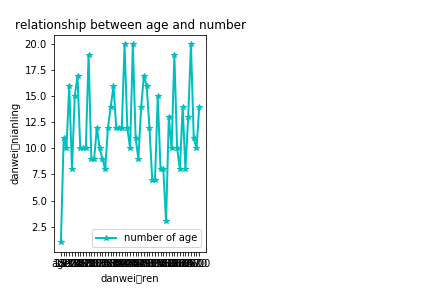
代码:
# 点线图
# coding:utf8
fig = plt.figure()
ax1 = fig.add_subplot(1,2,1)
x = [i for i in age.keys()]
y = [i for i in age.values()]
ax1.plot(x,y,'c*-', label='number of age', linewidth=2)
# 坐标轴标记
ax1.set_title("relationship between age and number")
ax1.set_xlabel("danwei:ren")
ax1.set_ylabel("danwei:nianling")
ax1.legend()
plt.savefig("demo6.png")
plt.show()
折线图
图示:
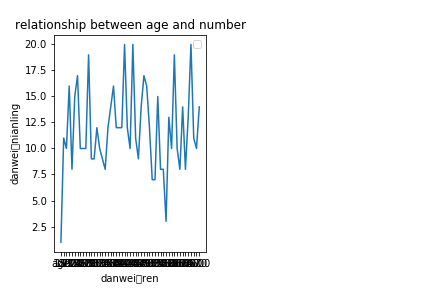
代码:
# 点线图
# coding:utf8
fig = plt.figure()
ax1 = fig.add_subplot(1,2,1)
x = [i for i in age.keys()]
y = [i for i in age.values()]
ax1.plot(x,y)
# 坐标轴标记
ax1.set_title("relationship between age and number")
ax1.set_xlabel("danwei:ren")
ax1.set_ylabel("danwei:nianling")
ax1.legend()
plt.savefig("demo7.png")
plt.show()
曲线图(插值法)(插值是曲线一定经过点,拟合是曲线不一定经过点)
图示
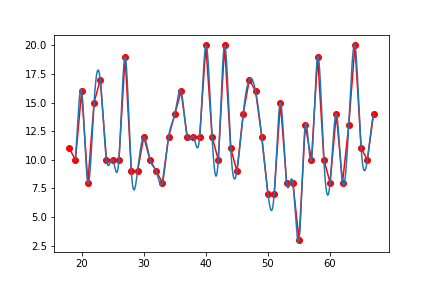
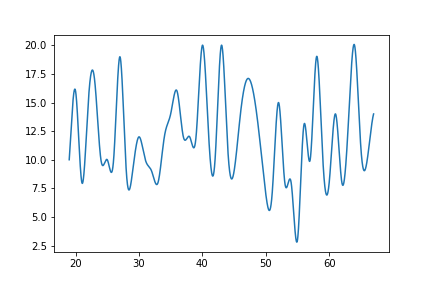
代码
#coding:utf8
# 实现平滑曲线图
# 两种方式:插值法或者拟合(机器学习生成的我认为可以归为拟合)
# 插值法
from scipy import interpolate
x = [i for i in age.keys() if i != "age"]
x.sort()
y = list(age.values())[1:]
func = interpolate.interp1d(x, y, kind='cubic')
# 插值法之后的x轴值,表示从0到9的若干个数
xnew = np.linspace(x[1], x[-1], 10000)
# 利用xnew和func函数生成ynew,xnew的数量等于ynew数量
ynew = func(xnew)
# 画图部分
# 原图
# plt.plot(x, y, 'ro-')
# 拟合之后的平滑曲线图
plt.plot(xnew, ynew)
# plt.savefig("demo8.png")
plt.savefig("demo9.png")
plt.show()
# 注意可能会出现如下错误:
# TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
# 原因是元素个数不一致导致。
# 参见链接:https://www.cnblogs.com/Yanjy-OnlyOne/p/11189547.html
(2)阶梯图
阶梯图常用来表示,某两个相邻的节点,后一个节点的数据相对前一个节点数据的升降变化,一般用在商品价格变动,股票价格变动,税率变化等.
阶梯图有三个关键值:
1)前一时间节点数值;
2)当前时间节点数值;
3)当前节点较前一节点的差值.
图示:
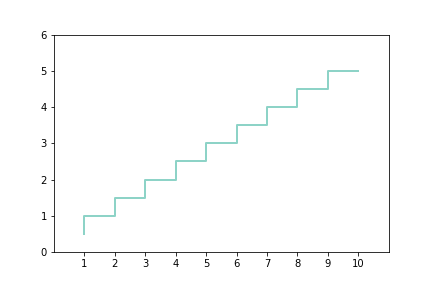
代码:
# 阶梯图(原来准备的数据用不了不清楚为什么)
import matplotlib.pyplot as plt
import numpy as np
x = [1,2,3,4,5,6,7,8,9,10]
y = [i/2 for i in x]
plt.step(x, y, color="#8dd3c7", where="pre", lw=2)
plt.xlim(0, 11)
plt.xticks(np.arange(1, 11, 1))
plt.ylim(0, 6)
plt.savefig("demo10.png")
plt.show()
(3)拟合曲线图
之前说插值的时候有所涉及,比如说做传统的回归或者流行的机器学习,在此不做扩展.
3.比例型数据可视化
1.饼图
饼图是通过角度来映射各类别对应的数值。
当构成整体的数据项较少时,采用饼图是一种不错的选择。
但是一个维度下属性较多会失去美感,杂乱不堪,重点不突出。
因此,对于饼图来说,建议扇区个数最大值在5~7个之间。当数据项超过一定数量时,可以按照占比,把排名最末的几项归位「其他」。
- 当数据项n<=6时,直接显示各扇区原始类别的名称。
- 当数据项n>6时,直接显示占比排名TOP5扇区的原始类别名称,剩余的数据项则归为「其他」。
图示:
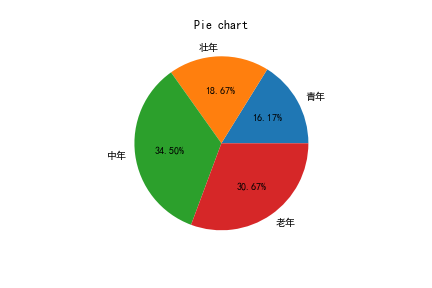
代码:
# coding:utf8
# 饼图
x = age_rangeCount.keys()
y = age_rangeCount.values()
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
labels=x
Y=y
fig = plt.figure()
plt.pie(Y,labels=labels,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("Pie chart")
plt.savefig("demo11.png")
plt.show()
# 无法显示中文怎么办?
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
2.环形图
环形图中心部位是空的,可以放置标签、整体数值、平均数值或其他内容。环形图中,数据项的分类和饼图类似,就不在赘述。
图示:
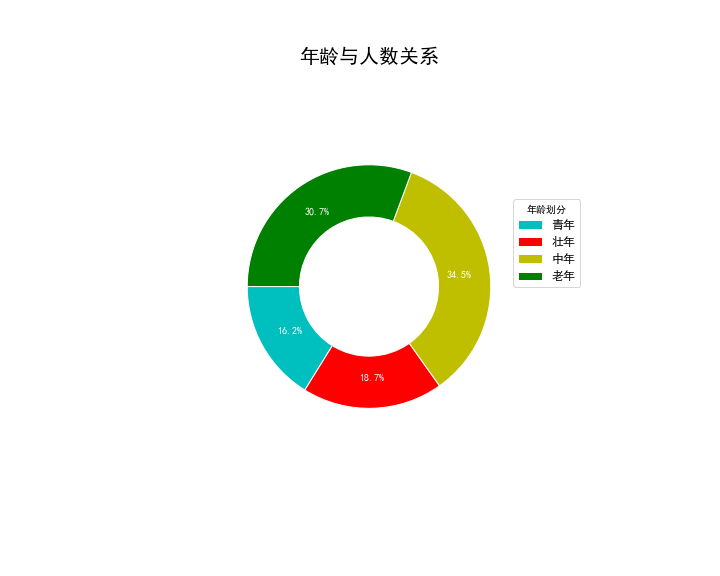
代码:
import matplotlib as mpl
import matplotlib.pyplot as plt
# 设置图片大小
plt.figure(figsize = (10, 8))
# 生成数据
X = x
Y = y
colors = ['c', 'r', 'y', 'g']
# 内环
wedges2, texts2, autotexts2 = plt.pie(Y,
autopct = '%3.1f%%',
radius = 0.7, # 控制半径
pctdistance = 0.75, # 控制文字位置
colors = colors,
startangle = 180,
textprops = {'color': 'w'},
wedgeprops = {'width': 0.3, 'edgecolor': 'w'}
)
# 图例
plt.legend(wedges1,
X,
fontsize = 12,
title = '年龄划分',
loc = 'center right',
bbox_to_anchor = (1, 0.6))
# 设置文本样式
plt.setp(autotexts1, size=15, weight='bold')
plt.setp(texts1, size=15)
# 标题
plt.title('年龄与人数关系', fontsize=20)
plt.savefig('demo12.png')
plt.show()
from matplotlib import pyplot as plt
import numpy as np
fig = plt.figure(figsize=[13.44,7.5],facecolor=(235/255,235/255,235/255))
ax1=fig.add_subplot(1,1,1,facecolor=(235/255,235/255,235/255),projection='polar')
ax1.axis('off')
ax1.barh(height=0.005,width=-0.4*3,y=0.4,color=(243/255,133/255,36/255))
ax1.scatter(-0.4*3,0.4,color=(243/255,133/255,36/255))
ax1.barh(height=0.005,width=-0.5*3,y=0.5,color=(243/255,10/255,36/255))
ax1.scatter(-0.5*3,0.5,color=(243/255,10/255,36/255))
ax1.barh(height=0.005,width=-2*2,y=0.6,color=(243/255,133/255,36/255))
ax1.scatter(-2*2,0.6,color=(243/255,133/255,36/255))
ax1.barh(height=0.005,width=-0.5*np.pi*2,y=0.7,color=(243/255,133/255,36/255))
ax1.scatter(-0.5*np.pi*2,y=0.7,color=(243/255,133/255,36/255))
3.百分比堆叠柱状图
当比例数据中存在多个父系列,每个父系列又由多个子类构成,且各个系列的子类相同时,此时展示比例数据,可以采用百分比堆叠柱状图。
- 各个系列对应的柱形条的高度是相同的,顶部刻度都为100%。
- 每根柱形条内部,各子项柱形条的高度,代表在该系列中的占比。
- 当各系列的子类数目较少时,可以直接在矩形内部展示占比;当数目较多时,建议隐藏。
- 当各系列的子类目较多时,为了保证重点突出和视觉效果,需要对子类目进行归类,归类方法参照饼图。
作图方法参照上文.
4.百分比堆叠面积图
当比例数据中存在多个父系列,且父系列的数据类型为时间,要分析父系列的各构成部分占比随时间的变化趋势,此时可以采用堆叠面积图来表示比例关系的变化。如果从某一点上对堆叠面积图进行垂直切片,那么就可以得到该时间段上的比例分布情况。
暂未找到用Python写的教程,这里用Excel实现.
(Excel写的很详细了,直接选取即可,这里因为没有太好的数据,做出来效果很差,就不展示了)
5.矩形树图
矩形树图,是一种基于面积的可视化方法。外部矩形代表父级类别,内部矩形代表子类别。相比于其他表示比例型的数据,矩形树图更适合展示具有树状结构的数据。
树状结构,简单理解,就是首先按一级分类来观测各构成部分的比例,然后再看某个一级分类下,是由哪些二级分类构成的,依次类推,逐步细化,可以直到叶子结点。
这里推荐用tableau制作矩形树图.
4.总结
时序数据,主要目的是研究数据随时间的变化,这种变化包括总量的变化、构成部分的变化、以及变化的趋势和规律。
比例数据,区别于其他数据类型的一个关键,在于它是为了寻求整体中的各个构成部分,及其相互关系。
5.问题回答
柱状图、趋势图中,坐标轴不从0开始可以吗?说明原因?
当然可以,而且在某种程度上还会起警示或误导的作用. 比如说30,32,这种情况放在0看波动很平缓,如果从28开始看的话波动剧烈,容易误导人.