Python之中,一切皆对象.
本文分为4部分:
1. 面向对象:初识
2. 面向对象:进阶
3. 面向对象:三大特性----继承,多态,封装
4. 面向对象:反射
0. 楔子
面向过程和面向对象的是两种思路:
面向过程是流水线,闷着头一口气写下来就行;
面向对象,感觉自己像是个上帝,先构思好,然后再去写,这也是我们写程序时候要做到的.
例子如下:
#面向过程,函数: def login(): pass def regisgter(): pass def func1(): pass def func2(): pass #面向对象,类: class Account: def login(self): pass def regisgter(self): pass class Account: def func1(self): pass def func2(self): pass
从上面的式子,我们很容易发现:
1.类相当于函数的集合,能够让你的函数更加集中,不是那么散乱.
2.用类的话有上帝视角. 倒也算不上哪个好哪个坏,无非是复杂的话用类好,简单的话用函数好.
1. 面向对象:初识
1.1 什么是对象和类
什么是对象? 人说,Python中,一切皆对象. 这么说似乎有些宽泛, 一切, 究竟包括什么呢?
其实,这里的一切是指所有的变量. 在之前我们已经学习了字符串等数据类型,也学习了函数和内置函数,还学会了内置模块和第三方模块的调用. 那么,这些都是对象吗?是的,一切皆对象. 只要我们能够将其赋给变量,甚至连模块都可以赋给变量,那么还有什么不是变量呢?
最近学到的一个经典例子:人狗大战. 这个例子可以生动形象的解释.
如果我们需要进行人和狗进行战斗这样一个场景,我们需要的内容是:
人的要素,比如生命值,攻击力,防御力,职业;狗的要素,生命值,攻击力,防御力,种类.
创建完两个角色的属性后,我们需要让他们发生互动,也就是'fight'.
但如果这时候,我们想要创建好几个人和狗怎么办呢? 很简单,我们只要把人和狗做成模子即可,就像活字印刷术,排完版之后蘸上墨水刷一下就好啦. 光想着这么多的东西,如果要是用函数的话,很容易没有条理的,尤其是创建人物和动物形象的时候.
用函数做法如下:
def Person(name,hp,ad,sex): # 模子 dic = {'name':name,'blood':hp,'attack':ad,'sex':sex} def fight(dog): # 攻击 属于人 # 狗掉血,就是人的攻击力 dog['blood'] -= dic['attack'] print('%s打了%s,%s掉了%s血' % (dic['name'], dog['name'], dog['name'], dic['attack'])) dic['fight'] = fight return dic def Dog(name,hp,ad,kind): dic = {'name': name, 'blood': hp, 'attack': ad, 'kind': kind} def bite(person): # 咬 属于狗 person['blood'] -= dic['attack'] print('%s咬了%s,%s掉了%s血' % (dic['name'], person['name'], person['name'], dic['attack'])) dic['bite'] = bite return dic
# 互相打 smith = Person('smith',20,1,'不详') print(smith) hei = Dog('小黑',3000,10,'哈士奇') print(hei) smith['fight'](hei) hei['bite'](smith)
说实话,是不是感觉乱乱的?
这时候,救星来了! 我们用类可以轻松做到!!!
class Dog: def __init__(self,name,blood,ad,kind): self.name = name # 向对象的内存空间中添加属性 self.hp = blood # 可以通过self在类的内部完成 self.ad = ad self.kind = kind def bite(self,person): person.hp -= self.ad print('%s攻击了%s,%s掉了%s点血' % (self.name, person.name, person.name, self.ad)) class Person: def __init__(self,name,hp,ad,sex): self.name = name self.hp = hp self.ad = ad self.sex = sex def fight(self,dog): dog.hp -= self.ad print('%s攻击了%s,%s掉了%s点血'%(self.name,dog.name,dog.name,self.ad))
这样,两个模子已经刻好了,并且将动作也定义完了(此处就是方法),当我们想创建的时候,就可以轻松创建,如下:
hei = Dog('小黑',300,20,'哈士奇') alex = Person('alex',20,1,'不详') alex.fight(hei) print(hei.hp) hei.bite(alex) print(alex.hp)
这样,上面的就是创建类,下面的就是实例化对象并且进行方法的调用.(其中__init__是属性)
类:具有相同方法和属性的一类事物
对象:具有相同的属性值的实际存在的例子. 此处,对象仅指实例化的对象.是狭义的.
广义的对象包括类.
1.2 类的结构和类的操作
类的结构基本如下:
class 类名:#切记,类名首字母大写,为了和系统内置的类区分开 def __init__():#可有可无,不是必须写的 pass def 方法名(): pass
查看类中变量的两种方法如下:
def 函数: pass class Dog: pass class Dog: 变量 = 1000 变量2 = 'abc' # 变量3 = [(1,2),(3,4)] 查看类当中的变量,方法一 print(Dog.__dict__['变量']) print(Dog.__dict__['变量2']) print(Dog.__dict__['变量3']) 查看方法二(常用) print(Dog.变量) print(Dog.变量2) print(Dog.变量3)
其中,若用Dog.__dict__可查看Dog的全部属性,当然也可以用此方法查看实例化的对象等.
调用类中静态变量的方法一致.
#续上列: class Cat: cat_of_producing = '猫舍'#理解为刷怪区吧,是静态变量 def __init__(self,name,hp): self.name = name self.hp = hp def catch(self): print('捕捉成功') print(Cat.cat_of_producing)#此时就能调用静态变量 #类名可以调用动态方法,但一般不用. #实例化对象也可以调用静态变量,能查能改. #但改的话一般用类名调用.
非常需要注意:::::::::::::::::::::::::::::::::::::

注意,当编译完了的时候,class就出现了其内存空间.当进行实例化的时候,其实例化对象也产生了一个内存空间.切记.
实例化的过程 :
1.开辟了一块空间,创造了一个self变量来指向这块空间
2.调用init,自动传self参数,其他的参数都是按照顺序传进来的
3.执行init
4.将self自动返回给调用者
PS:
1.类名可以调用所有定义在类中的名字
变量
函数名
2.对象名 可以调用所有定义在对象中的属性
在init函数中和self相关的
调用函数的,且调用函数的时候,会把当前的对象当做第一个参数传递给self
2. 面向对象:进阶
2.0 回顾
回顾上述内容,记得设置完属性和动作之后让他们进行互动.
class Monster: # 先生成一个怪物的形象 def __init__(self, name, hp, attack, type): self.name = name self.hp = hp self.attack = attack self.type = type # 然后再生成一个怪物的动作 def fight(self, person): person.hp -= self.attack print('%s对%s造成%s点伤害,%s还剩%s点血' % (self.name, person.name, self.attack, person.name, person.hp)) class Hero: # 同理,先生成一个英雄的形象 def __init__(self, name, hp, attack, sex): self.name = name self.hp = hp self.attack = attack self.type = type # 然后再生成一个怪物的动作 def fight(self, monster): monster.hp -= self.attack print('%s对%s造成%s点伤害,%s还剩%s点血' % (self.name, monster.name, self.attack, monster.name, monster.hp)) # 对人物和怪兽进行实例化 arthur = Hero('King_Arthur', 50, 20, 'male') siren1 = Monster('海妖1号', 200, 10, 'siren') #经过千辛万苦,我们的亚瑟王最终和海妖战斗在一起,并且各砍一刀 arthur.fight(siren1)#King_Arthur对海妖1号造成20点伤害,海妖1号还剩180点血 siren1.fight(arthur)#海妖1号对King_Arthur造成10点伤害,King_Arthur还剩40点血 #天呐,看来我们的亚瑟王如果不逃走的话将会命丧海妖之手,但是,,,,,,这跟我有什么关系呢哈哈哈哈哈 #为了增加游戏的趣味性,我们可以再加上武器系统,比如再建一个class Weapon,然后通过动作进行武器装备,还可以加上防御力和 # 闪避等属性,可操作性太多了.
为了纪念这场差点把亚瑟王杀死的旷世大战,我准备把这个小游戏命名为世纪之战.
记得,只要上面的世纪之战吃透,简单的写一个小小的自娱自乐的游戏至少是没问题哒.
2.1 内存空间
2.2 私有化(正常来说应当放到封装,但因为一些特殊原因放于此)
2.3 类的特殊成员(前面有两道下划线的内置方法)
2.1 内存空间
内存空间:一般是指主存储器空间(物理地址空间)或系统为一个用户程序分配内存空间。
内存地址:内存地址是内存当中存储数据的一个标识,并不是数据本身,通过内存地址可以找到内存当中存储的数据。由4位或8位16进制表示.
2.2 私有化
在前面加__即可,表明只有这个方法是由某类私有的.别的是调用不了的.
2.3 类的特殊成员
用到的时候可参考:https://www.jianshu.com/p/bf3166d8faf0
https://www.cnblogs.com/pyxiaomangshe/p/7927540.html
之前的方法已经能够解决日常的90%了,我们需要解决的10%可以从内置方法中找到答案.
内置方法又被称为双下方法,魔术方法.都是python的对象内部自带的,并且都不需要我们自己去调用它.
2.3.1 __str__和__repr__
class Course: def __init__(self,name,price,period): self.name = name self.price = price self.period = period # def __str__(self):# # """ # 打印这个对象的时候自动触发__str__ # :return: # """ # return '%s,%s,%s'%(self.name,self.price,self.period) # def __repr__(self):#备胎(str没有的时候才用repr) # """ # 打印这个对象的时候自动触发__str__ # :return: # """ # return '%s,%s,%s'%(self.name,self.price,self.period) python = Course('python',25000,'6 mouths') print(type(python)) # print('course:%s'%python) # print(f'course:{python}')
如果str存在,repr也存在,那么print(obj)和使用字符串格式化format,%s这两种方式 调用的都是__str__,而repr(obj)和%r格式化字符串,都会调用__repr__ ;
如果str不存在,repr存在,那么print(obj),字符串格式化format,%s,%r 和repr(obj)都调用__repr__.
如果str存在,repr不存在,那么print(obj)和使用字符串格式化format,%s这两种方式 调用的都是__str__.
repr(obj)和%r格式化字符串,都会打印出内存地址.
class Course: def __init__(self,name,price,period): self.name = name self.price = price self.period = period def __repr__(self):#备胎(str没有的时候才用repr) """ 打印这个对象的时候自动触发__str__ :return: """ return '%s,%s,%s'%(self.name,self.price,self.period) # def __str__(self): # return self.name class Python(Course): pass def __repr__(self): return '%s--%s--%s' % (self.name, self.price, self.period) # def __str__(self): # return '全栈开发:'+self.name python = Python('python',25000,'6mouths') print(python) #放开Courese和Python的str,显示为:全栈开发:python #放开Courese的str和Python的repr,显示为:python #放开Courese的repr和Python的str,显示为:全栈开发:python #放开Courese和Python的repr,显示为:python--25000--6mouths
有了repr或者str在打印对象的时候 就不会显示用户不关心的内存地址了.
增强了用户的体验 在程序开发的过程中,如果我们需要频繁打印对象中的属性,需要从类的外部做复杂的拼接,
实际上是一种麻烦.
如果这个拼接工作在类的内部已经完成了,打印对象的时候直接就能显示.
2.3.2 __new__和__del__
__new__ 构造方法 生产对象的时候用的 - 单例模式
__del__ 析构方法 在删除一个对象之前用的 - 归还操作系统资源
实例化一个Foo的对象,先开辟一块儿空间,使用的是Foo这个类内部的__new__.
如果我们的Foo类中是没有__new__方法的,调用object类的__new__方法了
在使用self之前,都还有一个生产self的过程,就是在内存中开辟一块属于这个对象的空间,并且在这个空间中存放一个类指针,以上就是__new__做的所有事情.
#__new__的实例: class Foo(object): def __new__(cls, *args, **kwargs): # cls永远不能使self参数,因为self在之后才被创建 obj = object.__new__(cls) # self是在这里被创造出来的 print('new : ',obj) return obj def __init__(self): print('init',self) Foo()
#关于__del__的一些解释
#在所有的代码都执行完毕之后,所有的值都会被python解释器回收
#python解释器清理内存
#1.我们主动删除 del obj
#2.python解释器周期性删除
#3.在程序结束之前 所有的内容都需要清空
#__del__的实例1: import time class A: def __init__(self,name,age): self.name = name self.age = age def __del__(self): #只和del obj语法有关系,在执行del obj之前会来执行一下__del__中的内容 print('执行我了') a = A('gh',84) # print(a.name) # print(a.age) # del a print(a)#执行完后自动清理
#__del__的实例2: import time class A: def __init__(self,path): self.f = open(path,'w') def __del__(self): '''归还一些操作系统的资源的时候使用''' '''包括文件网络数据库连接''' self.f.close() a = A('userinfo') time.sleep(1)
PS:拓展:单例模式
设计模式 - 单例模式
一个类 有且只能有一个实例
保证一个类无论 被实例化多少次,只开辟一次空间,始终使用的是同一块内存地址
class A:pass a1 = A() a2 = A() print(a1) print(a2) class A: __flag = None def __new__(cls, *args, **kwargs): if cls.__flag is None: cls.__flag = object.__new__(cls) return cls.__flag def __init__(self,name=None,age=None): self.name = name if age: self.age = age a1 = A('alex',84) print(a1) a2 = A('alex',83) print(a2) a3 = A('alex') print(a3) print(a1.age)#结果为83,说明最后一次覆盖掉了
2.3.3 __call__
#__call__ #源码里用比较多 Flask web框架 #对象()自动触发__call__中的内容 class A: def call(self): print('in call') def __call__(self, *args, **kwargs):#自动调用__call__ print('in __call__') # A()() obj = A() obj() obj.call()
转载自:https://segmentfault.com/q/1010000006113393?_ea=1020343(好吧,表示现在看的还不是太懂)
用一句话描述是, Python 的 __call__ 方法可以让类的实例具有类似于函数的行为,通常用于定义和初始化一些带有上下文的函数。 既然说是妙处,那不得不提及 Python 世界中的那几个经典实现了。 一个例子来源于 bottle 框架源码的 cached_property(被我改动了一些细节,但用法基本是一样的),为了在逻辑上构成一个封闭的整体,我们把一个实例当作函数来使用: class CachedProperty(object): _cache = {} def __call__(self, fn): @property @functools.wraps(fn) def wrapped(self): k = '%s:%s' % (id(self), fn.__name__) v = CachedProperty._cache.get(k) if v is None: v = fn(self) CachedProperty._cache[k] = v return v return wrapped cached_property = CachedProperty() 使用的时候可以直接替换掉内置的 property 来缓存动态属性: class DB(object): def __init__(self, ...): .... @cached_property def conn(self): return create_connection(...) db = DB() db.conn # 创建连接并缓存 还有个更复杂但非常实用的例子,Pipline,把函数封装成支持管道操作的运算过程: class Pipe(object): def __init__(self, fn): self.fn = fn def __ror__(self, other): return self.fn(other) def __call__(self, *args, **kwargs): op = Pipe(lambda x: self.fn(x, *args, **kwargs)) return op 可以像这样调用: @Pipe def sort(data, cmp=None, key=None, reverse=False): return sorted(data, cmp=cmp, key=None, reverse=reverse) [{'score': 1}, {'score': 3}, {'score': 2}] | sort(key=lambda x: x['score']) 可以看出,类 Pipe 被当作一个装饰器使用,所以 sort 函数的原始定义被传递给 Pipe.__init__,构造出一个 Pipe 实例,所以被装饰过的 sort 函数,也就是我们后面使用的那个,实际上是一个 Pipe 类的实例,只是因为它有 __call__ 方法,所以可以作为函数来使用。 这种用法在写一些 ORM 框架以及有大量细粒度行为的库时有奇效。
2.3.4 __enter__,__exit__与with的完美结合
自动识别__enter__和__exit__
判定__enter__执行为开始,__exit__为结束
应用场景应当有很多:比如
执行语句体: class File: def __enter__(self): print('start') def __exit__(self, exc_type, exc_val, exc_tb): print('exit') with File(): print('wahaha')#相当于装饰器,输出顺序是 #start #wahaha #exit
写入文件: class myopen: def __init__(self,path,mode = 'r'): self.path = path self.mode = mode def __enter__(self): print('start') self.f = open(self.path,mode=self.mode) return self.f def __exit__(self, exc_type, exc_val, exc_tb): self.f.close() print('exit') with myopen('userinfo','a')as f: f.write('hello,world')
用pickle模块写入文件: import pickle class MypickleDump: def __init__(self,path,mode='ab'): self.path = path self.mode = mode def __enter__(self): self.f = open(self.path,self.mode) return self def dump(self,obj): pickle.dump(obj,self.f) def __exit__(self, exc_type, exc_val, exc_tb): self.f.close() with MypickleDump('pickle_file')as pickle_obj: pickle_obj.dump({1,2,3})
第三种写入文件,请比较异同:
class MypickleDump: def __init__(self,path,mode = 'ab'): self.path = path self.mode = mode def __enter__(self): self.f = open(self.path,self.mode) return self def dump(self,obj): pickle.dump(obj,self.f) def __exit__(self, exc_type, exc_val, exc_tb): self.f.close() with MypickleDump('pickle_file') as obj: obj.dump({1,2,3,4}) with MypickelLoad('pickle_file') as obj: for i in obj.loaditer(): print(i)
在一个函数的前后添加功能
利用使用 装饰器函数中的内容
with语句 就是和 __enter__,__exit__完美结合,请注意使用哦.
############################
划 重 点
############################
基础:
__new__
__del__
__call__
重点:
__str__
__repr__
__enter__
__exit__
3. 面向对象:继承,多态,封装
初入对象,感觉的确挺有意思,凡事都是那么简单的感觉,上帝视角,随意调用人物属性,随意设置任务动作,那滋味简直不要太爽!!!
然而,记得一个公式:痛苦==有益,爽==有害.一旦只沉迷于这种感觉,很容易不思进取,因为再往下就会感觉有些难度了.
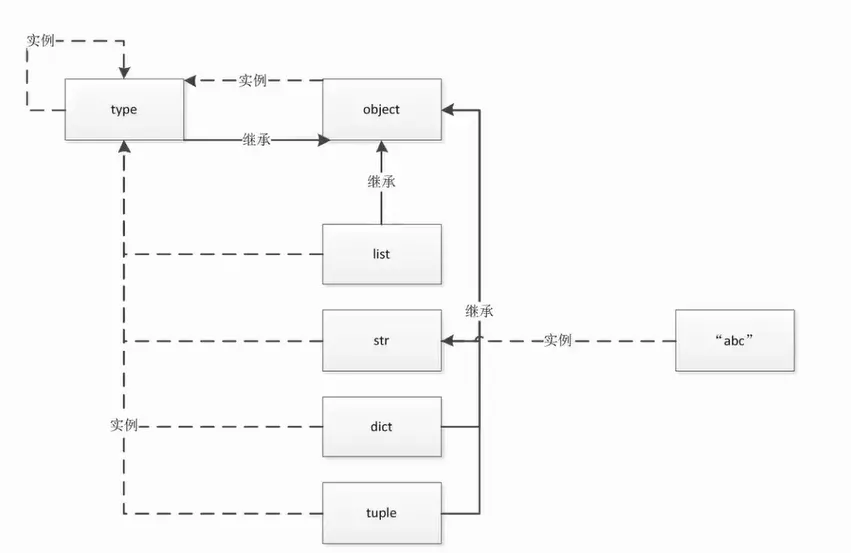
图中虚线代表实例关系,实线表示继承关系,从这个图中得出几点:
-
list、str、dict、tuple、type都继承了object,所以object是最顶层的基类
-
type是本身的对象(实例),object、list、str、dict、tuple都是type的对象,所以type创建了所有的对象
-
综合1、2可知,一切皆对象的同时又继承了object类,这就是python的灵活之处,Python的面向对象更加彻底.
其实,object也是继承元类(metaclass)得来的.
PS:(转载自王sir)
关于抽象类的理解: 1.抽象类的意义是?或者说为什么要有抽象类? 抽象类是对多个类中共同方法的抽取,但是子类又有不同的实现,父类只能抽取出方法的名字,而不明确方法的具体实现. 这种只规定子类拥有哪些方法,而不明确具体实现的父类,就应该定义为抽象类. 抽象类只用来规范子类应该具有哪些行为,而不明确具体的动作. 2.抽象类的特点是? 抽象类和普通类的最主要区别在于: 1.抽象类继承的()中写的是metaclass=ABCMeta 2.在类体中有用@abstractmethod修饰的方法(需要子类重写的方法) 3.抽象类中是否可以有非抽象方法? 可以. 4.抽象类中的抽象方法是否可以有方法体? 可以. 5.抽象类中是否可以有__init__方法?为什么? 可以,因为抽象类中也可以有实例属性供子类继承. 而实例属性必须在父类中初始化,子类对象才能继承. 抽象类的__init__方法不能手动调用,只能是子类创建对象时自动调用的.
4. 面向对象:反射
首先,要明确一点的是,反射的格式:a.b <====> getattr(a,'b') 诸如此类,这是核心概念!!!!!
所有的a,b都可以变成getattr(a,'b')
用字符串数据类型的变量名 来获取实际的变量值
用字符串数据类型的变量名 找到这个变量对应的内存地址
4.1 两个内置函数
issubclass
# class A:pass # class B(A):pass # class C(A):pass # print(issubclass(B,A)) # print(issubclass(C,A)) # print(issubclass(B,C))#只针对类 # print(isinstance(B,A))#只针对对象与类
isinstance
# a = 1 # ret1 = type(a) is int # print(ret1) # ret2 = isinstance(a,int) # ret3 = isinstance(a,object) # print(ret2) # print(ret3)
小结:
两个内置函数
isinstance()判断对象与类是否有继承关系
type()判断对象与类是否有关系(只承认实例化对象的那个类,不承认继承关系)
issubclass()判断类与类是否有继承关系
4.2 一个套餐,4个函数
内置函数:
getattr
hasattr
setattr
delattr
4.2.1 hasattr()
用途:hasattr#判断是否找到对象,判断True 或者 False
格式:hasattr(a,'b'),返回True或者False. 常与getattr()连用,判断是否可以调用,避免报错.
4.2.2 getattr()
用途:getattr#找到对象对应的内存地址,调用字符串作为属性名
格式:getattr(a,'b'),等同于a.b
if hasattr(s,'choose_goods'): # 判断s对象有没有choose_goods func = getattr(s,'choose_goods') # 使用s找到choose_goods对应的内存地址 print(func) func()
PS:若想调用变量a或b,但只能输入'a'或'b'.
a = 1 b = 2 getattr(modules[__name__],'变量名')#这个一定要牢记!!!
4.2.3 setattr()
用途:用于添加,有三个变量.
格式:setattr(x, 'y', v) is equivalent to ``x.y = v''#官方解释
setattr(alex,'wahaha',wahaha) print(alex.__dict__) alex.wahaha(alex)
4.2.4 delattr()
用途:用于删除
格式:delattr(x, 'y') is equivalent to ``del x.y''#官方解释
delattr() print(smith.__dict__) delattr(smith,'name') # del smith.name print(smith.__dict__)
4.3 四种反射情况
4.3.1 使用对象反射
obj.属性名
obj.方法名()
# 1.使用对象反射(先列出类) # class Manager: # 管理员用户 # def __init__(self,name): # self.name = name # def create_course(self): # 创建课程 # print('in Manager create_course') # # def create_student(self): # 给学生创建账号 # print('in Manager create_student') # # def show_courses(self): # 查看所有课程 # print('in Manager show_courses') # # def show_students(self): # 查看所有学生 # print('in Manager show_students')
# 不用反射
# alex = Manager('alex')
# operate_lst = ['创建课程','创建学生账号','查看所有课程','查看所有学生']
# for index,opt in enumerate(operate_lst,1):
# print(index,opt)
# num = input('请输入您要做的操作 :')
# if num.isdigit():
# num = int(num)
# if num == 1:
# alex.create_course()
# elif num == 2:
# alex.create_student()
# elif num == 3:
# alex.show_courses()
# elif num == 4:
# alex.show_students()
# 使用反射 # alex = Manager('alex') # operate_lst = [('创建课程','create_course'),('创建学生账号','create_student'), # ('查看所有课程','show_courses'),('查看所有学生','show_students')] # for index,opt in enumerate(operate_lst,1): # print(index,opt[0]) # num = input('请输入您要做的操作 :') # if num.isdigit(): # num = int(num) # if hasattr(alex,operate_lst[num-1][1]): # getattr(alex,operate_lst[num-1][1])()
4.3.2 使用模块反射
import time time.time() 调用函数和方法 地址+() def func(): print(1) func() a = func a()
# 反射模块中的方法 import re # ret = re.findall('d+','2985urowhn0857023u9t4') # print(ret) # 'findall' # getattr(re,'findall') # re.findall # ret = getattr(re,'findall')('d','wuhfa0y80aujeiagu') # print(ret) # def func(a,b): # return a+b # wahaha = func # ret = wahaha(1,2) # print(ret)
4.3.3 使用类反射
cls.静态变量名
cls.类方法名()
cls.静态方法名()
# 两种方式 # 对象名.属性名 / 对象名.方法名() 可以直接使用对象的方法和属性 # 当我们只有字符串数据类型的内容的时候 # getattr(对象名,'方法名')() # getattr(对象名,'属性名')
4.3.4 反射当前文件
# 反射本文件中的内容 :只要是出现在全局变量中的名字都可以通过getattr(modules[__name__],字符串数据类型的名字) from sys import modules # print(modules) # DICT KEY是模块的名字,value就是这个模块对应的文件地址 # import re # print(re) # <module 're' from 'D:\python3\lib\re.py'> # print(modules['re']) # 选课系统 # 're': <module 're' from 'D:\python3\lib\re.py'> # print(re.findall) # print(modules['re'].findall) # a = 1 # b = 2 # while True: # name = input('变量名 :') # print(__name__) # print(getattr(modules[__name__],name)) # '__main__': <module '__main__' from 'D:/PyCharmProject/s20/day23/5.反射.py'> # print(a,b) # print(modules['__main__'].a) # print(modules['__main__'].b) # # print(getattr(modules['__main__'], 'a')) # print(getattr(modules['__main__'], 'b'))
4.3.5 总结
# hasattr和getattr # 只要是a.b这种结构,都可以使用反射 # 用对象类模块反射,都只有以下场景 # 这种结构有两种场景 # a.b b是属性或者变量值 # getattr(a,'b') == a.b # a.b() b是函数或者方法 # a.b() # getattr(a,'b')() # a.b(arg1,arg2) # getattr(a,'b')(arg1,arg2) # a.b(*args,**kwargs) # getattr(a,'b')(*args,**kwargs) # 如果是本文件中的内容,不符合a.b这种结构 # 直接调用func() # getattr(sys.modules[__name__],'func')() # 直接使用类名 Person() # getattr(sys.modules[__name__],'Person')() # 直接使用变量名 print(a) # getattr(sys.modules[__name__],'a') # 所有的getattr都应该和hasattr一起使用 # if hasattr(): getattr() # setattr 只用来修改或者添加属性变量,不能用来处理函数或者是其他方法 # a.b = value # setattr(a,'b',value) # delattr 只用来删除 属性变量 # del a.b 删除属性 相当于删除了a对象当中的b属性 # delattr(a,'b')