一.性能测试的概念:
性能测试:通过一定的手段,在多并发下情况下,获取被测系统的各项性能指标,验证被测系统在高并发下 的处理能力、响应能力,稳定性等,能否满足预期。定位性能瓶颈,排查性能隐患,保障系统的 质量,提升用户体验。
二.适合做性能测试的系统:
◼ 用户量大,PV比较高的系统
◼ 系统核心模块/接口
◼ 业务逻辑/算法比较复杂
◼ 促销/活动推广计划
◼ 新系统,新项目
◼ 线上性能问题验证和调优
◼ 新技术选型
◼ 性能容量评估和规划
◼ 日常系统性能回归
三.性能测试的指标
1.【TPS(Transaction Per Second )】:每秒处理的事务数。
事务:在性能测试领域里,衡量一个系统性能的好坏,主要看的是单位时间内,系统可以处理多少业务量。 各个系统的业务各不相同,为了方便使用统一指标来衡量业务的性能。用事务来代表业务操作,一 个事务可以代表一个业务,也可以代表多个业务操作。事务是用户定义的,想测试什么业务的性能, 就把该业务加到事务中。
比如:查询银行卡的余额是一个业务;取钱也是一个业务;查询+取钱也是一个业务。
2.【平均响应时间】:在测试过程中,所有请求的平均耗时。
一个请求的响应时间包含的时间有:
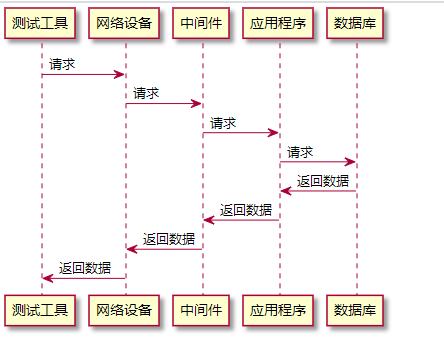
响应时间=网络传输的总时间+各组件业务处理时间
3.【TOP响应时间】:将所有请求的响应时间先从大到小进行排序,计算指定比例的请求都是小于某个时间。该指标统计 的是大多数请求的耗时。
Tp90(90%响应时间):90%的请求耗时都低于某个时间
Tp95(95%响应时间):95%的请求耗时都低于某个时间
Tp99(99%响应时间):99%的请求耗时都低于某个时间
4.【并发数/虚拟用户(Vuser)】:压测工具中设置的并发线程/进程数量。
5.【成功率】:请求的成功率。
6.【PV(Page View)】: 页面/接口的访问量。
7.【UV(Unique Visitor)】 :页面/接口的每日唯一访客。
8.【吞吐量】: 网络中上行和下行的流量总和,吞吐量代表网络的流量,TPS越高,吞吐量越大。
思考:TPS,响应时间和并发数三者之间的关系是怎样的?
1)在系统达到性能瓶颈之前,TPS和并发数成正比关系
2)在一定的并发数下,响应时间与TPS成反比关系
3)响应时间单位为秒的情况下:(理论上,适合单接口的业务)
TPS = 1 / 响应时间 * 并发数
TPS = 并发数 / 响应时间
9.【操作系统级别监控】: CPU使用率、内存使用率、网络IO(input/output)、磁盘(read/write/util)
10.【中间件监控】 :连接数、长短连接、使用内存
11.【应用层监控】: 线程状态、JVM参数、GC频率、锁
12.【DB层监控】: 连接数、锁、缓存、内存、SQL效率
四.性能测试的流程
1• 需求调研
|
◼ 项目背景 ◼ 测试范围 ◼ 业务逻辑 & 数据流向 ◼ 系统架构 ◼ 配置信息 ◼ 测试数据量(量级要一致) ◼ 外部依赖 ◼ 系统使用场景,业务比例 ◼ 日常业务量 ◼ 预期指标 ◼ 上线时间 |
2• 测试计划
|
◼ 项目描述 ◼ 业务模型及性能指标 ◼ 测试环境说明 ◼ 测试资源 ◼ 测试方法以及场景设计原则: ◼ 基准测试 ◼ 单交易负载测试 ◼ 混合场景测试 ◼ 高可用性测试 ◼ 异常场景测试 ◼ 稳定性测试 ◼ 其他特殊场景 ◼ 测试进度安排及测试准则 |
3• 环境搭建
|
测试要点: 测试机器硬件配置尽量和线上一致 ◼ 系统版本与线上一致 ◼ 测试环境部署线上最小单元模块 ◼ 应用、中间件、数据库配置要与线上一致 ◼ 其他特殊配置 |
4• 数据准备
|
测试数据分为两部分:基础数据和参数化数据 通常采用以下三种方法进行构造 : ◼业务接口 -- 适合数据表关系复杂 -- 优点:数据完整性比较好 ◼存储过程 -- 适合表数量少,简单 -- 优点:速度最快 ◼脚本导入 -- 适合数据逻辑复杂 -- 自由度比较高 |
5• 脚本编写
|
选择工具(Loadrunner、Jmeter、Locust等) ◼ 选择协议(Http、TCP、RPC) ◼ 参数化 ◼ 关联 ◼ 检查点 ◼ 事务判断 |
6• 压测执行
|
◼分布式执行 ◼ 监控 -- Linux -- Jvm -- 数据库 ◼ 收集测试结果 ◼ 数据分析 ◼ 瓶颈定位 |
7• 调优回归
|
◼ 性能调优需要整个团队完成 ◼ 反复尝试 ◼ 回归验证 ◼ 监控工具 ◼ 全链路排查 ◼ 日志分析 ◼ 模块隔离 |
8• 测试报告
|
◼ 概述 ◼ 测试环境 ◼ 结果与分析 ◼ 调优说明 ◼ 项目时间表 ◼ 结论 ◼ 建议 |