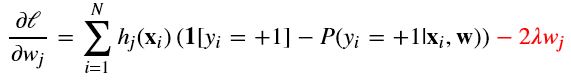华盛顿大学 machine learning: Classification 笔记。
linear classifier 线性分类器

多项式:

Logistic regression & 概率模型

P(y = +1 | x) = ?
使用 logistic函数

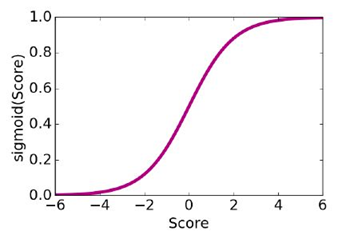
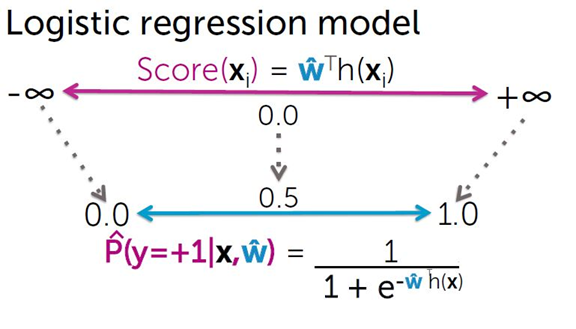
这个概率模型怎么来的?
(李航《统计学习方法》)

即
![]()
考虑对输入x进行分类的线性函数 w x,其值域为实数域,线性函数wx可转换为概率:
![]()
这时,线性函数值越接近正无穷,概率值就越接近1;线性函数值越接近负无穷,
概率值就越接近0。
这种概率描述适用于这样的情况:即在P=0或P=1附近,P对X的变化不敏感。这种概率模型的应用场景主要是分类。
极大似然估计模型参数w
Maximize Likelihood Estimation(MLE) 极大似然估计
![]()
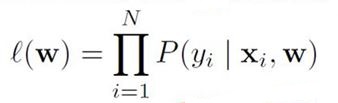
即 选择使 l(w) 最大的参数 w。
对 l(w) 取对数:

展开得
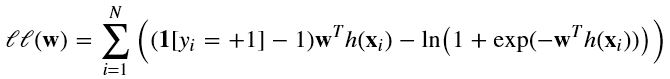
梯度下降(Gradient-descent):

防止过拟合:

即
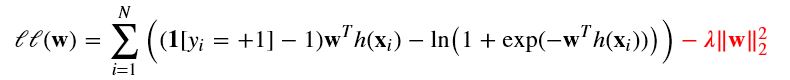
梯度下降