原题网址:http://hihocoder.com/problemset/problem/1312
时间限制:10000ms
单点时限:1000ms
内存限制:256MB
描述
在小Ho的手机上有一款叫做八数码的游戏,小Ho在坐车或者等人的时候经常使用这个游戏来打发时间。
游戏的棋盘被分割成3x3的区域,上面放着标记有1~8八个数字的方形棋子,剩下一个区域为空。
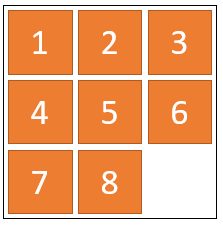
游戏过程中,小Ho只能移动棋子到相邻的空区域上。当小Ho将8个棋子都移动到如下图所示的位置时,游戏就结束了。
小Hi:小Ho,你觉得如果用计算机来玩这个游戏应该怎么做?
小Ho:用计算机来玩么?我觉得应该是搜索吧,让我想一想。
输入
第1行:1个正整数t,表示数据组数。1≤t≤8。
接下来有t组数据,每组数据有3行,每行3个整数,包含0~8,每个数字只出现一次,其中0表示空位。
输出
第1..t行:每行1个整数,表示该组数据解的步数。若无解输出"No Solution!"
样例输入
3
1 2 3
4 5 6
7 8 0
1 2 3
4 5 6
8 7 0
8 0 1
5 7 4
3 6 2
样例输出
0
No Solution!
25
提示:启发式搜索
小Ho:这个问题和上一次一样嘛,用宽度优先搜索来求解。
然后把这个3x3的二维数组拉伸成一个长度为9的数组,将长度为9的数组作为状态。
那么最终状态就是{1,2,3,4,5,6,7,8,0}。
由于每一个位置的有9种可能,所以我建立一个9维数组来判重进行搜索就好了。
小Hi:9维数组,每一维的大小为9。小Ho,你确定这不会超过内存限制么?
小Ho:9的9次方等于387420489,好像是挺大的。不过应该没问题吧。
小Hi:怎么可能没问题!这个数据已经很大了好么!
小Ho:那该怎么办啊?
小Hi:小Ho,你仔细观察题目的状态。由于每个数字一定只会出现一次,每个状态对应的恰好是1~9的一个排列。
那么1~9的全排列有多少种呢?
小Ho:这个我知道,是9!,一共362880种。
小Hi:没错,总共只有不到40万种不同的情况。如果我们能够使用一个方法来表示不同排列的状态,那么是不是就可以把判重的状态数量压缩到40万以内了呢?
小Ho:恩,没错。但是有什么好的方法么?
小Hi:当然有啦,这里我们需要用的事全排列的知识。小Ho你知道全排列是有顺序的么?
小Ho:恩,知道。比如3个数的全排列,按顺序就是:
123, 132, 213, 231, 312, 321
小Hi:没错,那么第二个问题:假如我给你一个全排列,你能计算出它是第几个排列么?
小Ho:(⊙v⊙),这个我不知道。
小Hi:我就知道你不知道,让我来告诉你吧。这里我们需要用到一个叫做康托展开的方法。
对于一个长度为n的排列num[1..n],其序号X为:
X = a[1]*(n-1)!+a[2]*(n-2)!+...+a[i]*(n-i)!+...+a[n-1]*1!+a[n]*0!
其中a[i]表示在num[i+1..n]中比num[i]小的数的数量
举个例子,比如213:
num[] = {2, 1, 3}
a[] = {1, 0, 0}
X = 1 * 2! + 0 * 1! + 0 * 1! = 2
我们如果将3的全排列从0开始编号,2号对应的正是213。
其写做伪代码为:
Cantor(num[])
X = 0
For i = 1 .. n
tp = 0
For j = i + 1 .. n
If (num[j] < num[i]) Then
tp = tp + 1
End If
End For
X = X + tp * (n - i)!
End For
Return X
那么接下来,第三个问题!
小Ho:你说吧!
小Hi:已知X,如何去反向求解出全排列?
小Ho:我觉得应该还是从康托展开的公式入手。
< 小Ho拿出草稿纸,在上面推算了一会儿 >
根据X的求值公式,可以推断出对于a[i]来说,其值一定小于等于n-i。那么有:
a[i]≤n-i, a[i]*(n-i)!≤(n-i)*(n-i)!<(n-i+1)!
也就是说,对于a[i]来说,无论a[i+1..n]的值为多少,其后面的和都不会超过(n-i)!
那么也就是说,如果我用X除以(n-1)!,得到商c和余数r。其中c就等于a[1],r则等于后面的部分。
这样依次求解,就可以得到a[]数组了!
比如求解3的全排列中,编号为3的排列:
3 / 2! = 1 ... 1 => a[1] = 1
1 / 1! = 1 ... 0 => a[2] = 1
0 / 0! = 0 ... 0 => a[3] = 0
然后就是根据a[]来求解num[],让我想一想。
...
我知道了!由于a[i]表示的是num[i+1..n]中比num[i]还小的数字。
那么只需要从num[1]开始,依次从尚未使用的数字中选取第a[i]+1小的数字填入就可以了!
紧接着上面的例子:
a[] = {1, 1, 0}
unused = {1, 2, 3}, a[1] = 1, num[1] = 2
unused = {1, 3}, a[2] = 1, num[2] = 3
unused = {1}, a[3] = 0, num[3] = 1
=> 2, 3, 1
231也确实是3的全排列中编号为3的排列。
小Hi:小Ho,你真棒!你使用的这个方法也被称为逆康托展开,写作代码的话:
unCantor(X):
a = []
num = []
used = [] // 长度为n的boolean数组,初始为false
For i = 1 .. n
a[i] = X / (n - i)!
X = X mod (n - i)!
cnt = 0
For j = 1 .. n
If (used[j]) Then
cnt = cnt + 1
If (cnt == a[i] + 1) Then
num[i] = j
used[j] = true
Break
End If
End If
End For
End For
Return num
通过康托展开以及康托逆展开,我们就将该问题的状态空间压缩到了9!,在空间复杂度上得到了优化。
小Ho:那么这次的问题不就解决了!
小Hi:远远没那么简单哦,其实这个问题还有一个时间上的优化。
小Ho:但是宽度优先搜索不就是最快寻找到解的方法了么?还有更好的方法么?
小Hi:当然有了,我们有一种叫做启发式搜索的方法。
在启发式搜索的过程中,不再是一定按照步数最优的顺序来搜索。
首先在启发式搜索中,我们每次找到当前“最有希望是最短路径”的状态进行扩展。对于每个状态的我们用函数F来估计它是否有希望。F包含两个部分:
F = G + H
G:就是普通宽度优先搜索中的从起始状态到当前状态的代价,比如在这次的问题中,G就等于从起始状态到当前状态的最少步数。
H:是一个估计的值,表示从当前状态到目标状态估计的代价(步数)。
H是由我们自己设计的,H函数设计的好坏决定了A*算法的效率。H值越大,算法运行越快。
但是在设计评估函数时,需要注意一个很重要的性质:评估函数的值一定要小于等于实际当前状态到目标状态的代价(步数)。
否则虽然你的程序运行速度加快,但是可能在搜索过程中漏掉了最优解。相对的,只要评估函数的值小于等于实际当前状态到目标状态的代价,就一定能找到最优解
在这个问题中可以表述为:评估函数得到的从当前状态到目标的状态需要行动的步数一定不能超过实际上需要行动的步数。
所以,我们可以将评估函数设定为:1-8八数字当前位置到目标位置的曼哈顿距离之和。(为什么这样设计留给读者思考。当然也有其他符合条件的估计函数,不同估计函数效率如何也留给读者自行比较。)
F:评估值和状态值的总和。
同时在启发式搜索中将原来的一个队列变成了两个队列:openlist和closelist。
在openlist中的状态,其F值还可能发生变化。而在closelist中的状态,其F值一定不会再发生改变。
整个搜索解的流程变为:
- 计算初始状态的F值,并将其加入openlist
- 从openlist中取出F值最小的状态u,并将u加入closelist。若u为目标状态,结束搜索;
- 对u进行扩展,假设其扩展的状态为v:若v未出现过,计算v的f值并加入openlist;若v在openlist中,更新v的F值,取较小的一个;若v在closelist中,抛弃该状态。
- 若openlist为空,结束搜索。否则回到2。
利用这个方法可以避免搜索一些明显会远离目标状态的状态,从而缩小搜索空间,早一步搜索到目标结果。
在启发式搜索中,最重要的是评估函数的选取,一个好的评估函数能够更快的趋近于目标状态。
将上述过程写做伪代码为:
search(status):
start.status = status
start.g = 0 // 实际步数
start.h = evaluate(start.status)
start.f = start.g + start.h
openlist.insert(start)
While (!openlist.isEmpty())
u = openlist.getMinFStatus()
closelist.insert(u)
For v is u.neighborStatus
If (v in openlist) Then
// 更新v的f值
If (v.f > v.h + u.g + 1) Then
v.f = v.h + u.g + 1
End If
Else If (v in closelist)
continue
Else
v.g = u.g + 1
v.h = evaluate(v.status)
v.f = v.g + v.h
openlist.insert(v)
End If
End For
End While
其中openlist.getMinFStatus()可以使用堆来实现。
启发式搜索在某些情况下并不一定好用,一方面取决于评估函数的选取,另一个方面由于在选取状态时也会有额外的开销。而快速趋近目标结果所减少的时间,能否弥补这一部分开销也是非常关键的。
所以根据题目选取合适的搜索方法才是最重要的。
提示已经讲得很全面了。
一个方面是空间上的优化,用康托展开和逆康托展开来表示八数码的状态。
另一方面是时间上的优化,用启发式搜索(A*),其中评估函数设定为1-8八数字当前位置到目标位置的曼哈顿距离之和。
#include <algorithm> #include <cstring> #include <string.h> #include <iostream> #include <list> #include <map> #include <set> #include <stack> #include <string> #include <utility> #include <queue> #include <vector> #include <cstdio> #include <cmath> #define LL long long #define N 100005 #define INF 0x3ffffff using namespace std; int factor[]={1,1,2,6,24,120,720,5040,40320}; vector<int>stnum; //八数码某个状态序列 int destination; //目标状态康托展开值 struct state { int f; //评估值和状态值的总和。 int g; //从起始状态到当前状态的最少步数 int h; //评估函数 int k; //该状态康托展开值 state(int f,int g,int h,int k):f(f),g(g),h(h),k(k){}; friend bool operator<(state a,state b) { if(a.f!=b.f) return a.f>b.f; else return a.g>b.g; } }; int cantor(vector<int>num) //康托展开 { int k = 0; int n = 9; for(int i=0;i<n;i++) { int tp = 0; for(int j = i+1; j < n; j++) { if(num[j] < num[i]) { tp++; } } k += tp * factor[n-1-i]; } return k; } vector<int> recantor(int k) //逆康托展开 { vector<int>num; int a[10]; int n = 9; bool used[10]; memset(used,false,sizeof(used)); for(int i=0;i<n;i++){ a[i] = k / factor[n-1-i]; k %= factor[n-1-i]; int cnt = 0; for(int j=0;j<n;j++){ if(!used[j]) { cnt++; if(a[i] + 1==cnt) { num.push_back(j); used[j] = true; break; } } } } return num; } int pos[]={8,0,1,2,3,4,5,6,7}; int getdis(int a,int b) //曼哈顿距离 { return (abs(a/3-b/3)+abs(a%3-b%3)); } int get_evaluation(vector<int>num) //评估函数 { //评估函数设定为1-8八数字当前位置到目标位置的曼哈顿距离之和。 int h=0; for(int i=0;i<9;i++) { h+=getdis(i,pos[num[i]]); } return h; } void solve() { priority_queue<state>openlist; set<int>closelist; //在closelist中,抛弃该状态。 while(!openlist.empty()) openlist.pop(); closelist.clear(); int h=get_evaluation(stnum); openlist.push(state(h,0,h,cantor(stnum))); int step=0; //统计步数 bool flag=false; //标记是否能找到目标状态 while(!openlist.empty()) { state cur=openlist.top(); //从openlist中取出F值最小的状态 openlist.pop(); int k=cur.k; closelist.insert(k); //将该状态加入closelist if(destination==k) {//若该状态为目标状态,结束搜索 flag=true; //找到目标状态 step=cur.g; //步数 break; } vector<int> st = recantor(k); //当前状态的八数码序列 for(int i=0;i<9;i++) if(st[i]==0) //找到0的位置 { if(i%3!=2) { //不在行末,0位可以和右边相邻位置交换 swap(st[i],st[i+1]); int x = cantor(st); int g = cur.g+1; int h = get_evaluation(st); int f = g + h; if(closelist.find(x)==closelist.end()) { openlist.push(state(f,g,h,x)); } swap(st[i],st[i+1]); } if(i%3!=0) { //不在某行开头,可以和左边相邻位置交换 swap(st[i],st[i-1]); int x = cantor(st); int g = cur.g+1; int h = get_evaluation(st); int f = g + h; if(closelist.find(x)==closelist.end()) { openlist.push(state(f,g,h,x)); } swap(st[i],st[i-1]); } if(i<6) { swap(st[i],st[i+3]); int x = cantor(st); int g = cur.g+1; int h = get_evaluation(st); int f = g + h; if(closelist.find(x)==closelist.end()) { openlist.push(state(f,g,h,x)); } swap(st[i],st[i+3]); } if(i>2) { swap(st[i],st[i-3]); int x = cantor(st); int g = cur.g+1; int h = get_evaluation(st); int f = g + h; if(closelist.find(x)==closelist.end()) { openlist.push(state(f,g,h,x)); } swap(st[i],st[i-3]); } } } if(!flag) cout << "No Solution!" << endl; else cout<<step<<endl; } int main() { vector <int> des; for(int i=0;i<8;i++) des.push_back(i+1); des.push_back(0); destination=cantor(des); int T; cin >> T; while(T--) { int a; stnum.clear(); for(int i=0;i<9;i++) {cin>>a; stnum.push_back(a);} solve(); } return 0; }