【实验目的】
通过上机实验,加深对语法制导翻译的理解,掌握将语法分析所识别的语法成分变换为中间代码的语义翻译方法。
【实验内容】
对给定的程序通过语义分析器能够判断语句串是否正确。正确则输出三地址指令形式的四元式代码,错误则抛出错误信息。
【设计思想】
(1)输入待分析的字符串。
语法如下:
a.关键字:begin,if,then,while,do,end.
b.运算符和界符::= + - * / < <= > >= <> = ; ( ) #
c.其他单词是标识符(ID)和整形常数(NUM):ID=letter(letter|digit)*,NUM=digitdigit*
d.空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
(2)扫描字符串,采用递归向下进行分析。
主要函数如下:
a.scaner()//词法分析函数,char token[8]用来存放构成单词符号的字符串;
b.parser()//语法分析,在语法分析的基础上插入相应的语义动作:将输入串翻译成四元式序列。只对表达式、赋值语句进行翻译。
c.emit(char *result,char *arg1,char *op,char *ag2)//该函数功能是生成一个三地址语句返回四元式表中。
d.char *newtemp()//该函数返回一个新的临时变量名,临时变量名产生的顺序为T1,T2,…。
【实验要求】
四元式表的结构如下:
struct {char result[8];
char ag1[8];
char op[8];
char ag2[8];
}quad[20];
(3)输出为三地址指令形式的四元式序列。
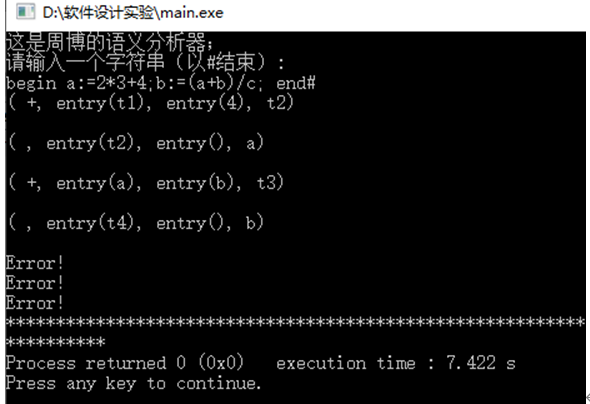
例如:语句串begin a:=2+3*4;x:=(a+b)/c;end#,
输出的三地址指令如下:
t1=3*4
t2=2+t1
a=t2
t3=a+b
t4=t3/c
x=t4
代码:
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 #include<stdlib.h> 5 using namespace std; 6 struct { 7 char result[12]; 8 char ag1[12]; 9 char op[12]; 10 char ag2[12]; 11 }quad; 12 //变量的定义 13 char prog[80], token[12]; 14 char ch; int syn, p, m = 0, n, sum = 0, kk; //p 是缓冲区 prog 的指针, m 是 token 的指针 15 char *rwtab[6] = { "begin", "if", "then", "while", "do", "end" }; 16 void scaner(); 17 char *factor(void); 18 char *term(void); 19 char *expression(void); 20 int yucu(); 21 void emit(char *result, char *ag1, char *op, char *ag2); 22 char *newtemp(); 23 int statement(); 24 int k = 0; 25 void emit(char *result, char *ag1, char *op, char *ag2) { 26 strcpy(quad.result, result); 27 strcpy(quad.ag1, ag1); 28 strcpy(quad.op, op); 29 strcpy(quad.ag2, ag2); 30 //cout<<quad.result<<"="<<quad.ag1<<quad.op<<quad.ag2<<endl; 31 cout << "( " << quad.op << ", " << "entry(" << quad.ag1 << "), " << "entry(" << quad.ag2 << "), " << quad.result << ") " << endl; 32 //cout<<"entry("<<quad.ag1<<"entry("<<quad.op<<quad.ag2<<endl; 33 } 34 char *newtemp() { 35 char *p; 36 char m[12]; 37 p = (char *)malloc(12); 38 k++; 39 _itoa_s(k, m, 10); 40 strcpy(p + 1, m); 41 p[0] = 't'; 42 return (p); 43 } 44 //对字符的扫描 45 void scaner() { 46 for (n = 0; n<8; n++) 47 token[n] = NULL; 48 ch = prog[p++]; 49 while (ch == ' ') { 50 ch = prog[p]; 51 p++; 52 } 53 if ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z')) { 54 if ((ch >= 'a'&&ch <= 'c') || (ch >= 'A'&&ch <= 'C')){ 55 m = 0; 56 while ((ch >= '0'&&ch <= '9') || (ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z')) { 57 token[m++] = ch; 58 ch = prog[p++]; 59 } 60 token[m++] = '�'; 61 p--; 62 syn = 10; 63 for (n = 0; n<6; n++) { 64 if (strcmp(token, rwtab[n]) == 0) { 65 syn = n + 1; 66 break; 67 } 68 } 69 } 70 else 71 cout << "Error!" << endl; 72 } 73 else if ((ch >= '0'&&ch <= '9')) { 74 { 75 sum = 0; 76 while ((ch >= '0'&&ch <= '9')) { 77 sum = sum * 10 + ch - '0'; 78 ch = prog[p++]; 79 } 80 } 81 p--; 82 syn = 11; 83 if (sum>32767) 84 syn = -1; 85 } 86 else switch (ch) 87 { 88 case'<': 89 m = 0; 90 token[m++] = ch; 91 ch = prog[p++]; 92 if (ch == '>') { 93 syn = 21; 94 token[m++] = ch; 95 } 96 else if (ch == '=') 97 { 98 syn = 22; 99 token[m++] = ch; 100 } 101 else { 102 syn = 23; 103 p--; 104 } 105 break; 106 case'>': 107 m = 0; 108 token[m++] = ch; 109 ch = prog[p++]; 110 if (ch == '=') { 111 syn = 24; 112 token[m++] = ch; 113 } 114 else { 115 syn = 20; 116 p--; 117 } 118 break; 119 case':': 120 m = 0; token[m++] = ch; 121 ch = prog[p++]; 122 if (ch == '=') { 123 syn = 18; 124 token[m++] = ch; 125 } 126 else { 127 syn = 17; 128 p--; 129 } 130 break; 131 case'*': 132 syn = 13; 133 token[0] = ch; 134 break; 135 case'/': 136 syn = 14; 137 token[0] = ch; 138 break; 139 case'+': 140 syn = 15; 141 token[0] = ch; 142 break; 143 case'-': 144 syn = 16; 145 token[0] = ch; 146 break; 147 case'=': 148 syn = 25; 149 token[0] = ch; 150 break; 151 case';': 152 syn = 26; 153 token[0] = ch; 154 break; 155 case'(': 156 syn = 27; 157 token[0] = ch; 158 break; 159 case')': 160 syn = 28; 161 token[0] = ch; 162 break; 163 case'#': 164 syn = 0; 165 token[0] = ch; 166 break; 167 default: 168 syn = -1; 169 break; 170 } 171 } 172 int lrparser() 173 { 174 //cout<<" 调用 lrparser"<<endl; 175 int schain = 0; 176 kk = 0; 177 if (syn == 1) { 178 scaner(); 179 schain = yucu(); 180 //cout<<"SYN= "<<syn<<endl; 181 if (syn == 6) { 182 scaner(); 183 if (syn == 0 && (kk == 0)) 184 cout << "success!" << endl; 185 } 186 /* else 187 { 188 if(kk!=1) 189 cout<<"缺 end!"<<endl; 190 kk=1; 191 } */ 192 } 193 else 194 { 195 cout << "Error!" << endl; 196 kk = 1; 197 } 198 return(schain); 199 } 200 int yucu() { // cout<<" 调用 yucu"<<endl; 201 int schain = 0; 202 schain = statement(); 203 while (syn == 26) { 204 scaner(); 205 schain = statement(); 206 } 207 return(schain); 208 } 209 int statement() 210 { 211 //cout<<" 调用 statement"<<endl; 212 char *eplace, *tt; 213 eplace = (char *)malloc(12); 214 tt = (char *)malloc(12); 215 int schain = 0; 216 switch (syn) { 217 case 10: 218 strcpy(tt, token); 219 scaner(); 220 // if(syn==18) { 221 scaner(); 222 strcpy(eplace, expression()); 223 emit(tt, eplace, "", ""); 224 schain = 0; 225 /* } 226 else { cout<<"缺少赋值符 !"<<endl; 227 kk=1; 228 } */ 229 return (schain); 230 break; 231 } 232 return (schain); 233 } 234 char *expression(void) { 235 char *tp, *ep2, *eplace, *tt; 236 tp = (char *)malloc(12); 237 ep2 = (char *)malloc(12); 238 eplace = (char *)malloc(12); 239 tt = (char *)malloc(12); 240 strcpy(eplace, term()); //调用 term 分析产生表达式计算的第一项 eplace 241 while ((syn == 15) || (syn == 16)) { 242 if (syn == 15) 243 strcpy(tt, "+"); 244 else 245 strcpy(tt, "-"); 246 scaner(); 247 strcpy(ep2, term()); //调用 term 分析产生表达式计算的第二项 ep2 248 strcpy(tp, newtemp()); // 调用 newtemp 产生临时变量 tp 存储计算结果 249 emit(tp, eplace, tt, ep2); //生成四元式送入四元式表 250 strcpy(eplace, tp); 251 } 252 return(eplace); 253 } 254 char *term(void) { 255 // cout<<" 调用 term"<<endl; 256 char *tp, *ep2, *eplace, *tt; 257 tp = (char *)malloc(12); 258 ep2 = (char *)malloc(12); 259 eplace = (char *)malloc(12); 260 tt = (char *)malloc(12); 261 strcpy(eplace, factor()); 262 while ((syn == 13) || (syn == 14)) { 263 if (syn == 13)strcpy(tt, "*"); 264 else strcpy(tt, "/"); 265 scaner(); strcpy(ep2, factor()); // 调用 factor 分析产生表达式计算的第二项 ep2 266 strcpy(tp, newtemp()); 267 //调用 newtemp产生临时变量 tp 存储计算结果 emit(tp,eplace,tt,ep2); //生成四元式送入四元式表 268 strcpy(eplace, tp); 269 } 270 return(eplace); 271 } 272 char *factor(void) { 273 char *fplace; 274 fplace = (char *)malloc(12); 275 strcpy(fplace, ""); 276 if (syn == 10) { 277 strcpy(fplace, token); 278 scaner(); 279 } 280 else if (syn == 11) { 281 itoa(sum, fplace, 10); 282 scaner(); 283 } 284 else if (syn == 27) { 285 scaner(); 286 fplace = expression(); //调用 expression分析返回表达式的值 287 if (syn == 28) 288 scaner(); 289 else { 290 cout << "缺)错误 !" << endl; 291 kk = 1; 292 } 293 } 294 else { 295 cout << "缺(错误 !" << endl; 296 kk = 1; 297 } 298 return(fplace); 299 } 300 int main(void) { 301 cout << "这是周博的语义分析器;" << endl; 302 for (int i = 0; i < 10; i++) 303 { 304 cout << "*************"; 305 } 306 cout << endl; 307 p = 0; 308 cout << "请输入一个字符串(以#结束):" << endl; 309 do { 310 cin.get(ch); 311 prog[p++] = ch; 312 } while (ch != '#'); 313 p = 0; 314 scaner(); 315 lrparser(); 316 for (int i = 0; i < 10; i++) 317 { 318 cout << "*************"; 319 } 320 return 0;
实验截图: