因为TreeMap的相关知识较多,故TreeMap的分析将会分成三篇文章来写,望大家谅解。
本篇文章先给大家介绍一下红黑树基本概念,并分析一下在红黑树中查找某个结点的相关源码实现。
TreeMap是啥
从TreeMap的类名上就能知道它的底层存储结构其实是红黑树。首先简单介绍一下红黑树的相关知识,以便理解后续内容。
什么是红黑树?先放一张红黑树的示意图看看:
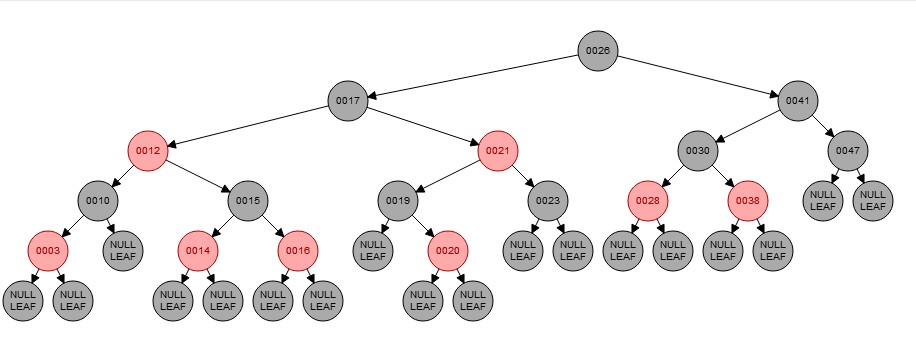
注:图片出处为 博客园 —— 五月的仓颉
简单解释一下树的相关术语的含义:
1.根结点(即0026结点):整个树结构图中最上面的一个结点,其他所有的结点都是由该结点延伸出去的。
2.父结点:在树的上下结构中,有连接关系并处于上方的结点。比如0026是0017和0041的父结点,0017是0012和0021的父结点等等。
3.子结点:在树的上下结构中,有连接关系并处于下方的结点。比如0017是0026的左子结点,0041是0026的右子结点;0030是0041的左子结点,0047是0041的右子结点。
并且左子节点是小于父结点的,而右子节点一般是大于父结点的。比如0012比0017小,而0010比0012小;同样0041比0026大,并且0047也比0041大。
4.兄弟结点:属于同一个父结点的结点互相称为兄弟结点。比如0017和0041同属于0026的子结点,则0017和0041就是兄弟节点。
5.叶子结点:没有任何子结点的结点称为叶子节点。如上图中所有的NULL LEAF结点都是叶子结点。
6.二叉树:每个节点最多只有两个子结点的树结构称为二叉树。如上图就是一种二叉树的数据结构。
树的一些基本术语就介绍到这里,其他的请同学们自行查阅资料学习吧,这里就不再多说了 : )
什么是红黑树
上面已经说了TreeMap是基于红黑树的存储结构,那什么是红黑树呢?
红黑树是一种特殊的二叉树,它的每个结点都额外有一个颜色的属性,颜色只有两种:红色和黑色。
关于红黑树有以下几个规定:
1.首先当前树必须为二叉树的结构。
2.每个结点都有一种颜色,且颜色只能为红色或黑色
3.根结点必须是黑色。
4.叶子结点必须是黑色。
5.不能同时出现父结点和子结点都是红色的情况。即如果一个结点是父结点且为红色,则它的子结点必须全部为黑色。
6.从根结点到每个叶子结点经过的路程中,黑色结点的数量必须是一样的。
比如 0026 -> 0017 -> 0012 -> 0010 -> 0003 -> 叶子结点,这条路径上共有4个黑色结点;
0026 -> 0041 -> 0030 -> 0038 -> 叶子结点,这条路径上也有4个黑色结点。
只有以上6个条件全部满足的树,我们才称其为红黑树。比如上图的中的树结构就是一个标准的红黑树。
TreeMap源码中的数据结构及相关属性
1 /** 2 * 红黑树每个结点对象的数据结构 3 * 4 * 5 * @param <K> key 6 * @param <V> value 7 */ 8 static final class Entry<K,V> implements Map.Entry<K,V> { 9 K key; //键 10 V value; //值 11 Entry<K,V> left; //左子结点引用 12 Entry<K,V> right; //右子结点引用 13 Entry<K,V> parent; //父结点引用 14 boolean color = BLACK; //结点默认为黑色 15 16 /** 17 * 构造一个叶子结点,默认无左右子结点,颜色为黑色 18 */ 19 Entry(K key, V value, Entry<K,V> parent) { 20 this.key = key; 21 this.value = value; 22 this.parent = parent; 23 } 24 25 /** 26 * 返回key 27 * 28 * @return the key 29 */ 30 public K getKey() { 31 return key; 32 } 33 34 /** 35 * 返回key对应的value 36 * 37 * @return the value associated with the key 38 */ 39 public V getValue() { 40 return value; 41 } 42 43 /** 44 * 替换对应的值 45 * 46 * @return 原先被替换的值 47 */ 48 public V setValue(V value) { 49 V oldValue = this.value; 50 this.value = value; 51 return oldValue; 52 } 53 54 /** 55 * 重写结点的equals()方法,比较结点的大小时使用 56 */ 57 public boolean equals(Object o) { 58 if (!(o instanceof Map.Entry)) 59 return false; 60 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 61 //必须key和value都相同才算相等 62 return valEquals(key,e.getKey()) && valEquals(value,e.getValue()); 63 } 64 65 /** 66 * 重写结点的hashCode()方法 67 */ 68 public int hashCode() { 69 int keyHash = (key==null ? 0 : key.hashCode()); 70 int valueHash = (value==null ? 0 : value.hashCode()); 71 return keyHash ^ valueHash; //key的hashCode 异或 value的hashCode 72 } 73 74 /** 75 * 重写toString()方法 76 */ 77 public String toString() { 78 return key + "=" + value; 79 } 80 } 81 82 /** 用户自定义的比较器 */ 83 private final Comparator<? super K> comparator; 84 85 /** 红黑树根结点 */ 86 private transient Entry<K,V> root; 87 88 /** 红黑树总结点个数 */ 89 private transient int size = 0;
可以看到TreeMap因为实现了Map的结点的数据结构,所以同样有key和value两个属性。并且因为是红黑树,所以还有父结点、左右子结点的引用以及结点颜色这些属性。
我们看到第83行有个 comparator 属性,它表示当前TreeMap使用的是哪种比较器。
大家都知道TreeMap是支持结点排序的,它有两种排序方式:
1.按照结点key的自然顺序维护结点的顺序。比如有两个结点 A Entry<1,"11"> 和 B Entry<2,"222">,以这种key的自然排序来讲,如果先插入A后插入B,则A为B父结点,B为A的右子结点;如果先插入B后插入A,那么B为A的父结点,A为B的左子结点。
2.另一种排序是用户自定义的排序方式。在构造方法中传入一个自定义的比较器,则TreeMap会根据用户自己定义的结点对象比较大小的方法来维护结点的顺序。
TreeMap构造方法
1 /** 2 * 无参数构造方法,使用key的自然比较顺序来维护树中结点的顺序 3 */ 4 public TreeMap() { 5 comparator = null; 6 } 7 8 /** 9 * 带参数构造方法,使用用户传入的比较器来维护树中结点的顺序 10 * @param 用户自定义比较器,如果为空,则该Map会使用key的自然排序维护树的顺序 11 */ 12 public TreeMap(Comparator<? super K> comparator) { 13 this.comparator = comparator; 14 }
TreeMap获取某个结点的源码分析
1 /** 2 * 获取节点的操作 3 * 如果在map中找到了这个键,则返回键对应的值;找不到对应的键或者键指向为null,否则返回null 4 * 5 * @throws ClassCastException 用户传入的key和当前map中的key无法比较(不是同一类型),则报该异常 6 * @throws NullPointerException 使用了自然排序但传入的key为null,或者比较器不支持key为null的情况,则报此异常 7 * 8 */ 9 public V get(Object key) { 10 Entry<K,V> p = getEntry(key); //可以看到实际上是调用getEntry()这个方法来获取节点的 11 return (p==null ? null : p.value); 12 } 13 14 15 /** 16 * 返回通过传入的键在map中找到的相应entry,若未找到则返回null 17 * 18 * @throws ClassCastException 用户传入的key和当前map中的key无法比较(不是同一类型),则报该异常 19 * @throws NullPointerException 使用了自然排序但传入的key为null,或者比较器不支持key为null的情况,则报此异常 20 */ 21 final Entry<K,V> getEntry(Object key) { 22 // 首先要区分是使用map键的自然排序查找还是使用用户自定义的比较器来进行查找 23 if (comparator != null) //如果用户传入了自定义比较器 24 return getEntryUsingComparator(key); //调用getEntryUsingComparator()方法,通过用户自定义比较器的compare()方法查找entry 25 if (key == null) //如果key为null,报空指针异常 26 throw new NullPointerException(); 27 Comparable<? super K> k = (Comparable<? super K>) key; //没有传入自定义比较器,使用key的自然排序比较传入的key和map中的key 28 Entry<K,V> p = root; //从根节点开始比较 29 while (p != null) { //如果节点不是空,则一直循环遍历比较 30 int cmp = k.compareTo(p.key); //获取传入的key和当前节点key的比较结果,使用自然排序Comparable实现的compareTo()方法进行比较 31 if (cmp < 0) //结果<0,说明传入的key比当前节点的key小 32 p = p.left; //将下次比较的节点变更为当前节点的左子节点 33 else if (cmp > 0) //结果>0,说明传入的key比当前节点的key大 34 p = p.right; //将下次比较的节点变更为当前节点的右子节点 35 else //结果相等,则该节点就是要查找的节点 36 return p; //直接返回节点对应的Entry 37 } 38 return null; //遍历完整个树也没找到,则返回null 39 } 40 41 42 43 /** 44 * 使用用户自定义比较器的比较方法来查找节点 45 * 逻辑与通过自然排序查找类似,不再赘述 46 */ 47 final Entry<K,V> getEntryUsingComparator(Object key) { 48 @SuppressWarnings("unchecked") 49 K k = (K) key; 50 Comparator<? super K> cpr = comparator; 51 if (cpr != null) { 52 Entry<K,V> p = root; 53 while (p != null) { 54 int cmp = cpr.compare(k, p.key); //仅仅这里和getEntry()方法不同,使用自定义比较器的compare()方法进行比较 55 if (cmp < 0) 56 p = p.left; 57 else if (cmp > 0) 58 p = p.right; 59 else 60 return p; 61 } 62 } 63 return null; 64 }
可以看到查找其实很简单,就是从根结点开始往下遍历比较。如果要查找的节点比较小,则继续往左子结点比较;反之则往右子结点比较;如果相等,则当前结点就是要查找的结点。
要注意的只有一点,即TreeMap使用的是key的自然排序还是用户自定义的排序。
key自然排序使用的是实现了Comparable接口的compareTo()方法来进行比较,而用户自定义排序则使用的实现Comparator接口的compare()方法来比较。
这里延伸一个经典的面试题:Comparable接口和Comparator接口有啥相同和不同之处?
相同点:两个接口都是用于支持对象进行比较大小所定义的。
不同点:
1.Comparable具体实现比较大小的方法是CompareTo(),而Comparator具体实现比较大小的方法是Compare()。
2.Comparable一般强调相同类型的对象进行比较(比如小明和小红都是人类,那他们之间的大小就是按年龄大小来进行比较的,那么CompareTo()方法中其实就是两人的age进行比较);
而相对的Comparator一般强调不同类型的对象进行比较(比如小华是人类,旺财是狗,而人类要和狗进行比较大小,则必须由用户自己制定一个比较规则来确定谁大谁小,那么compare()方法中其实就是自定义的两个类型的不同属性进行比较)。
明确这两个接口的区别后,上面查询结点的方法也就不难理解啦 : )
本篇文章到此结束,内容还是偏基础,希望大家不吝赐教。
那么下篇文章我会和大家一起分析下在插入节点后,红黑树内部数据结构是怎样一步步变化的,敬请期待哟~