在传统网络服务中扩展中需要处理Bytes来进行协议的读写,这种原始的处理方式让工作变得相当繁琐复杂,出错和调试的工作量都非常大;组件为了解决这一问题引用Stream读写方式,这种方式可以极大的简化网络协议读写的工作量,并大大提高协议编写效率。接下来就体验一下组件的PipeStream在处理一个完整的HTTP 1.1协议有多简便。
结构定义
HTTP 1.1协议就不详细介绍了,网上的资源非常丰富;在这里通过对象结束来描述这个协议
Request
class HttpRequest { public string HttpVersion { get; set; } public string Method { get; set; } public string BaseUrl { get; set; } public string ClientIP { get; set; } public string Path { get; set; } public string QueryString { get; set; } public string Url { get; set; } public Dictionary<string, string> Headers { get; private set; } = new Dictionary<string, string>(); public byte[] Body { get; set; } public int ContentLength { get; set; } public RequestStatus Status { get; set; } = RequestStatus.None; }
以上是描述一个HTTP请求提供了一些请求的详细信息和对应的请求内容
Response
class HttpResponse : IWriteHandler { public HttpResponse() { Headers["Content-Type"] = "text/html"; } public string HttpVersion { get; set; } = "HTTP/1.1"; public int Status { get; set; } public string StatusMessage { get; set; } = "OK"; public string Body { get; set; } public Dictionary<string, string> Headers = new Dictionary<string, string>(); public void Write(Stream stream) { var pipeStream = stream.ToPipeStream(); pipeStream.WriteLine($"{HttpVersion} {Status} {StatusMessage}"); foreach (var item in Headers) pipeStream.WriteLine($"{item.Key}: {item.Value}"); byte[] bodyData = null; if (!string.IsNullOrEmpty(Body)) { bodyData = Encoding.UTF8.GetBytes(Body); } if (bodyData != null) { pipeStream.WriteLine($"Content-Length: {bodyData.Length}"); } pipeStream.WriteLine(""); if (bodyData != null) { pipeStream.Write(bodyData, 0, bodyData.Length); } Completed?.Invoke(this); } public Action<IWriteHandler> Completed { get; set; } }
以上是对应请求的响应对象,实现了IWriteHandler接口,这个接口是告诉组件如何输出这个对象。
协议分析
结构对象有了接下来的工作就是把网络流中的HTTP协议数据读取到结构上.
请求基础信息
private void LoadRequestLine(HttpRequest request, PipeStream stream) { if (request.Status == RequestStatus.None) { if (stream.TryReadLine(out string line)) { var subItem = line.SubLeftWith(' ', out string value); request.Method = value; subItem = subItem.SubLeftWith(' ', out value); request.Url = value; request.HttpVersion = subItem; subItem = request.Url.SubRightWith('?', out value); request.QueryString = value; request.BaseUrl = subItem; request.Path = subItem.SubRightWith('/', out value); if (request.Path != "/") request.Path += "/"; request.Status = RequestStatus.LoadingHeader; } } }
以上方法主要是分解出Method,Url和QueryString等信息。由于TCP协议是流,所以在分析包的时候都要考虑当前数据是否满足要求,所以组件提供TryReadLine方法来判断当前内容是否满足一行的需求;还有通过组件提供的SubRightWith和SubLeftWith方法可以大简化了字符获取问题。
头部信息获取
private void LoadRequestHeader(HttpRequest request, PipeStream stream) { if (request.Status == RequestStatus.LoadingHeader) { while (stream.TryReadLine(out string line)) { if (string.IsNullOrEmpty(line)) { if (request.ContentLength == 0) { request.Status = RequestStatus.Completed; } else { request.Status = RequestStatus.LoadingBody; } return; } var name = line.SubRightWith(':', out string value); if (String.Compare(name, "Content-Length", true) == 0) { request.ContentLength = int.Parse(value); } request.Headers[name] = value.Trim(); } } }
头信息分析就更加简单,当获取一个空行的时候就说明头信息已经解释完成,接下来的就部分就是Body;由于涉及到Body所以需要判断一个头存不存在Content-Length属性,这个属性用于描述消息体的长度;其实Http还有一种chunked编码,这种编码是分块来处理最终以0
结尾。这种方式一般是响应用得比较多,对于提交则很少使用这种方式。
读取消息体
private void LoadRequestBody(HttpRequest request, PipeStream stream) { if (request.Status == RequestStatus.LoadingBody) { if (stream.Length >= request.ContentLength) { var data = new byte[request.ContentLength]; ; stream.Read(data, 0, data.Length); request.Body = data; request.Status = RequestStatus.Completed; } } }
读取消息体就简单了,只需要判断当前的PipeStream是否满足提交的长度,如果可以则直接获取并设置到request.Data属性中。这里只是获了流数据,实际上Http体的编码也有几种情况,在这里不详细介绍。这些实现在FastHttpApi中都有具体的实现代码,详细可以查看 https://github.com/IKende/FastHttpApi/blob/master/src/Data/DataConvertAttribute.cs
整合到服务
以上针对Request和Response的协议处理已经完成,接下来就集成到组件的TCP服务中
public override void SessionReceive(IServer server, SessionReceiveEventArgs e) { var request = GetRequest(e.Session); var pipeStream = e.Stream.ToPipeStream(); if (LoadRequest(request, pipeStream) == RequestStatus.Completed) { OnCompleted(request, e.Session); } } private RequestStatus LoadRequest(HttpRequest request, PipeStream stream) { LoadRequestLine(request, stream); LoadRequestHeader(request, stream); LoadRequestBody(request, stream); return request.Status; } private void OnCompleted(HttpRequest request, ISession session) { HttpResponse response = new HttpResponse(); StringBuilder sb = new StringBuilder(); sb.AppendLine("<html>"); sb.AppendLine("<body>"); sb.AppendLine($"<p>Method:{request.Method}</p>"); sb.AppendLine($"<p>Url:{request.Url}</p>"); sb.AppendLine($"<p>Path:{request.Path}</p>"); sb.AppendLine($"<p>QueryString:{request.QueryString}</p>"); sb.AppendLine($"<p>ClientIP:{request.ClientIP}</p>"); sb.AppendLine($"<p>Content-Length:{request.ContentLength}</p>"); foreach (var item in request.Headers) { sb.AppendLine($"<p>{item.Key}:{item.Value}</p>"); } sb.AppendLine("</body>"); sb.AppendLine("</html>"); response.Body = sb.ToString(); ClearRequest(session); session.Send(response); }
只需要在SessionReceive接收事件中创建相应的Request对象,并把PipeStream传递到相应的解释方法中,然后判断完成情况;当解释完成后就调用OnCompleted输出相应的Response信息,在这里简单地把当前请求信息输出返回.(在这里为什么要清除会话的Request呢,因为Http1.1是长连接会话,必须每个请求都需要创建一个新的Request对象信息)。
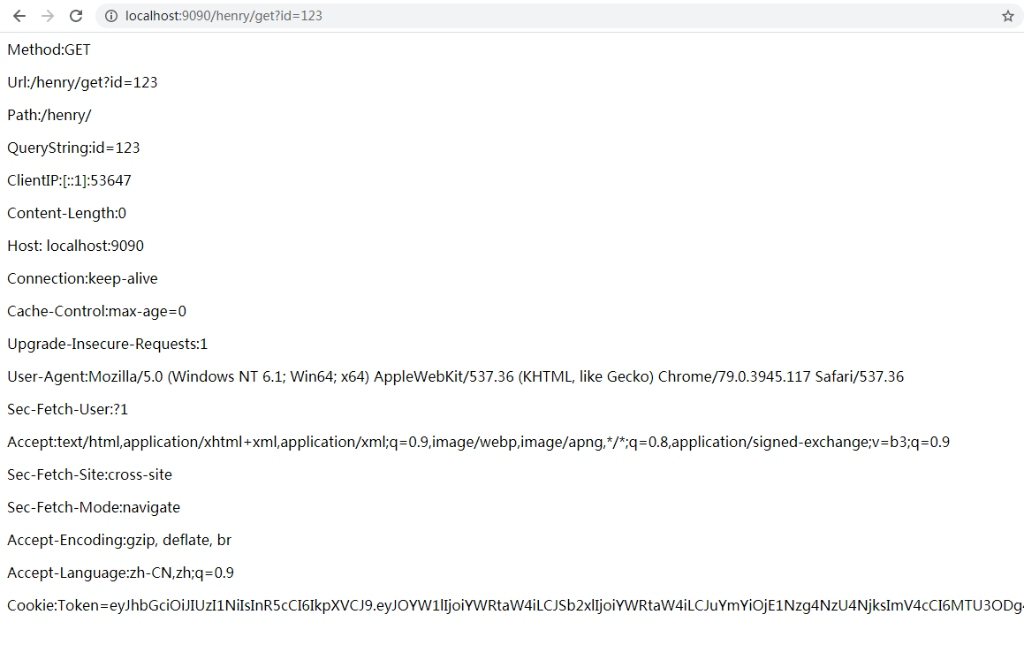
这样一个基于BeetleX解释的Http服务就完成了,是不是很简单。接下来简单地测试一下性能,在一台e3-1230v2+10Gb的环境压力测试
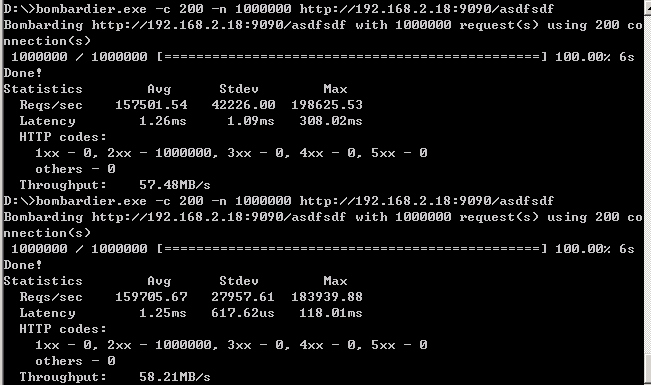
测试结果的有15万的RPS,虽然这样一个简单服务但效率并不理想,相对于也是基于组件扩展的FastHttpApi来说还是有些差距,为什么简单的代码还没有复杂的框架来得高效呢,其实原因很简单就是对象复用和string编码缓存没有用上,导致开销过大(这些细节上的性能优化有时间会在后续详解)。
下载完整代码 https://github.com/IKende/BeetleX-Samples/tree/master/TCP.BaseHttp