剩余匿名函数
序列
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,format,bytes,bytearry,memoryview,ord,chr,ascii,repr
format


#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐 print(format('test', '<20')) print(format('test', '>20')) print(format('test', '^20')) #整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None >>> format(3,'b') #转换成二进制 '11' >>> format(97,'c') #转换unicode成字符 'a' >>> format(11,'d') #转换成10进制 '11' >>> format(11,'o') #转换成8进制 '13' >>> format(11,'x') #转换成16进制 小写字母表示 'b' >>> format(11,'X') #转换成16进制 大写字母表示 'B' >>> format(11,'n') #和d一样 '11' >>> format(11) #默认和d一样 '11' #浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None >>> format(314159267,'e') #科学计数法,默认保留6位小数 '3.141593e+08' >>> format(314159267,'0.2e') #科学计数法,指定保留2位小数 '3.14e+08' >>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示 '3.14E+08' >>> format(314159267,'f') #小数点计数法,默认保留6位小数 '314159267.000000' >>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数 '3.141593' >>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数 '3.14159267' >>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数 '3.1415926700' >>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母 'INF' #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数 >>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点 '3e-05' >>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点 '3.1e-05' >>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点 '3.14e-05' >>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写 '3.14E-05' >>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点 '3' >>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点 '3.1' >>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点 '3.14' >>> format(0.00003141566,'.1n') #和g相同 '3e-05' >>> format(0.00003141566,'.3n') #和g相同 '3.14e-05' >>> format(0.00003141566) #和g相同 '3.141566e-05'
如果参数format_spec未提供,则和调用str(value)效果相同,转换成字符串格式化。
>>> format(3.1415936) '3.1415936' >>> str(3.1415926) '3.1415926'
bytearray
bytearray()函数方法返回一个新字节数组(bytes类型)。这个数组里的元素是可变的,范围在0~256。
a = bytearray([1,2,3,5]) a1 = bytearray('中国',encoding='utf-8')#字符串要指定编码方式 a2 = bytearray('中国',encoding='gbk')#字符串要指定编码方式 print(a) print(a1) print(a2)

memoryview
memoryview() 函数返回给定参数的内存查看对象(Momory view)。
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
>>>v = memoryview(bytearray("abcefg", 'utf-8')) >>> print(v[1]) 98 >>> print(v[-1]) 103 >>> print(v[1:4]) <memory at 0x10f543a08> >>> print(v[1:4].tobytes()) b'bce' >>>
ret = memoryview(bytes('你好',encoding='utf-8')) print(len(ret)) print(bytes(ret[:3]).decode('utf-8')) print(bytes(ret[3:]).decode('utf-8'))
reversed
reversed()函数返回一个反转的迭代器。
l = [1,2,3,8,4,3,9,2] # l.__reversed__()#返回的是迭代器 l1 = reversed(l) print(l1) for i in l1: print(i,end = ' ')

slice
slice()函数实现切片对象,主要用在切片操作函数里的参数传递。
l = [1,2,3,8,4,3,9,2] s = slice(1,6,2) print(l[s])

其他
chr
chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。返回值是当前整数对应的ascii字符。可以是10进制也可以是16进制的形式的数字。
ord
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
repr
repr() 函数将对象转化为供解释器读取的形式。返回一个对象的 string 格式。
ascii
ascii() 函数类似 repr() 函数, 返回一个表示对象的字符串, 但是对于字符串中的非 ASCII 字符则返回通过 repr() 函数使用 x, u 或 U 编码的字符。 生成字符串类似 Python2 版本中 repr() 函数的返回值。返回字符串。
print(ord('A')) print(chr(66))# print(repr('1')) print(repr(1)) print(ascii(1)) print(ascii('好'))

数据集合
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,all,any,zip,filter,map
filter
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用list()来转换。
该函数接收两个参数,第一个位函数,第二个位序列,序列的每个元素作为参数传递给函数进行判断,然后返回True或False,最后将返回True的元素放到新列表中。
从列表 [1,2,3,4,5,6,7,8]中删除偶数,保留奇数:
l = [1,2,3,4,5,6,7,8] def check(x): return x%2 == 0 ret = filter(check,l)#filter(函数名or None,iterable) for i in ret: print(i,end=' ')

删除None或者空字符串:
def c(x): return x and str(x).strip()#str(x) r1 = filter(c,[0,1,None,''," ",'123',[]]) for i in r1: print(i)

发现0也被删除了,因为0的返回值为False。
利用filter()过滤出1~100中平方根是整数的数:
import math def cal(x): return math.sqrt(x)%1 == 0#x的平方根除以1余0,说明为整数。 r = filter(cal,range(1,101)) for i in r: print(i,end=' ')

map
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理:
l = [1,2,3,4,5,6,7,8] def cal(x): return x**2 li = map(cal,l) for i in li: print(i,end=' ')

sorted
sorted() 函数对所有可迭代的对象进行排序操作。
1 sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。 2 list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。 3 即sort修改原列表,sorted返回生成一个新的列表。
列表排序:
l1 = [1,3,5,-2,-4,-6] l2 = sorted(l1)#排序,从小到大 l3 = sorted(l1,key=abs)#绝对值排序,从小到大 l4 = sorted(l1,key=abs,reverse=True)#绝对值排序,从大到小 print(l2) print(l3) print(l4)

l = [[1,2],[3,4,5,6],(7,),'123'] print(sorted(l,key=len))

zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
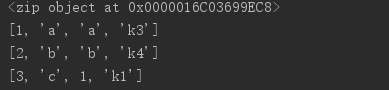
l = [1,2,3] l1 = ['a','b','c'] l2 = ['a','b',1] d = {'k1':1,'k2':2,'k3':3,'k4':4}#字典基本都是操作key,而且无序。 print(zip(l,l1,l2,d)) for i in zip(l,l1,l2,d): # print(i)#元组 print(list(i))#转换为列表
all
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
元素除了是 0、空、FALSE 外都算 TRUE。
如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False;
注意:空元组、空列表返回值为True,这里要特别注意。
print(all([1,2,3])) print(all((1,2,3))) print(all([1,2,3,0])) print(all([])) print(all(())) print(all([1,[]]))

any
any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。如果都为空、0、false,则返回false,如果不都为空、0、false,则返回true。
print(any((0,1,None))) print(any(['',[],0]))

pass