R语言学习特别说明:对字母大小写敏感
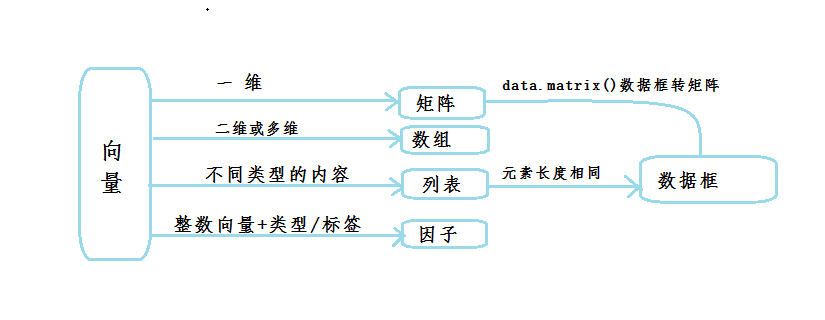
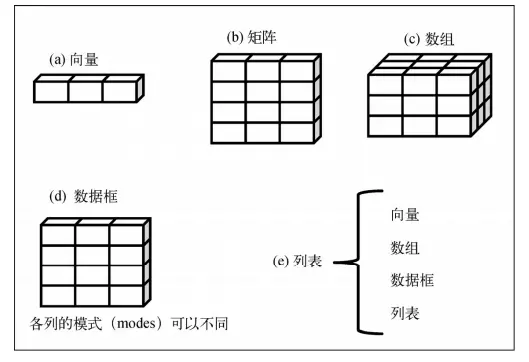
- R语言对象:R语言有6种存储数据的对象类型,它们分别是向量、数组、列表、矩阵、因子、数据框,接下来会一 一举例说明
- 对象的5种基本类型:字符(character) 数值(可以是整数或者是小数)(numeric)、整数(integer)、复合型(complex)、逻辑(logical)
- R对象的属性:对象的名称(name)、对象的维度(矩阵 数组)(dim)、对象的类型(class)、对象的长度(length)
- R语言赋值:R语言赋值不像C语言和Java语言赋值,R语言变量不需要声明,直接赋值使用
赋值符号用'<-'或者'='表示 ,推荐使用'<-'如:
x<-1
x:[1] 1 #方括号中的是x中的第一个元素
- 向量(vector)
- 简要描述:向量是用于存储数值型、字符型或逻辑型数据的一维数组,向量只能包含统一类型的对象
- 功能描述:函数vector(mode='logical',length=0L)有两个参数:类型(mode)和长度(length),创建的向量中元素值取决于参数所指定的数据类型:数值型(numeric())向量则元素值都为0,逻辑型(logical())都为FALSE,字符型(character())都为""。
- 向量的创建:
x<-c("a","b","c")
> x
[1] "a" "b" "c"
> y<-c(1,2,3,4,5)
> y
[1] 1 2 3 4 5
> z<-c(1:8)
> z
[1] 1 2 3 4 5 6 7 8
- 矩阵(matrix)
- 简要描述矩阵是向量加维度的属性
- 矩阵创建:矩阵参数最少两个,行和列,创建的是空白内容,矩阵是按照列来填充,dim函数可以很好的看见矩阵是多少行多少列
x<- matrix(nrow=3,ncol=4)
attributes(x) #查看矩阵的具体描述信息
注意:矩阵中元素的类型必须相同,矩阵是一维数组,当一个矩阵中存放不同类型的内容时会统一转换成一种类型,如下:
> x<-c(a,2,3,TRUE,FALSE)
> x
[1] 5 2 3 1 0
- 数组(Array)
- 简要描述:R数组是多维的,矩阵和数组的区别是数组可以多维,而矩阵只能是一维
- 创建数组:
> x<-array(1:24,dim=c(4,6))
> x
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 5 9 13 17 21
[2,] 2 6 10 14 18 22
[3,] 3 7 11 15 19 23
[4,] 4 8 12 16 20 24
> k<-array(1:24,dim=c(2,3,4)) #创建一个2行3列的思维数组,dim=c(2,3,4) 参数4代表的是数组的维度
>
> k
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
, , 3
[,1] [,2] [,3]
[1,] 13 15 17
[2,] 14 16 18
, , 4
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
- 列表(list)
- 简要描述:列表是一个包含不同的类型的内容数据集,一个列表中可以存放很多不同类型的数据
- 创建列表:list
l<-list(a,2,TRUE,-2i) > l [[1]] [1] 5 [[2]] [1] 2 [[3]] [1] TRUE [[4]] [1] 0-2i
- 命名列表内容
l2<-list(a=1,b=2,c=3)
> l2
$a
[1] 1
$b
[1] 2
$c
[1] 3
- 因子(Factor)
- 简要描述:factor 因子是用来处理分类数据有序和无序的数据,可以把因子理解成整数向量,因子优于整数向量,在因子中使用levels=...来设置基线水平
- 创建因子 :
> x<-factor(c("female","male","male","female","male"))
> x
[1] female male male female male
Levels: female male
> y<-factor(c("female","male","male","female","male"),levels=c("male","female"))
> y
[1] female male male female male
Levels: male female #Levels表示因子的水平,因子的水平可以手动设置
unclass(x) #去掉因子的属性来看因子内容
table(x) #计算因子中的词频
- 数据框(data.frame())
- 简要描述:R数据框是用于存储表格数据,存储列表,和矩阵关系密切,可以把它当作长度相同的列表
- 数据库小规则:数据框中每个元素代表一列数据、数据框中每个元素的长度代表行数、数据框中元素类型可以不同
- 创建数据框:
> df<-data.frame() > df data frame with 0 columns and 0 rows > class(df) [1] "data.frame"
- 日期(Date)
x<-Sys.date:获取当前系统的日期
x2<-"2015-10-01" #声明字符型日期
x3<-"2017-10-01"
x2<-as.Date("2015-10-01")
x3<-as.Date("2017-10-01") #将字符型的日期转换为日期类型
weekdays(x) #获取日期是周几
months(x) #当前日期是哪月
quarters(x) #当前日期属于这一年的哪个季度
julian(x) #表示距离1970-01-01日期到现在过去了多少天18123
#时间运算,日期运算可以转换为整数
> x2
[1] "2015-10-01"
> x3
[1] "2017-10-01"
> x3-x2
Time difference of 731 days
>as.numeric(x3-x2) #将结果转换成数值类型
[1] 731
#两个日期做减法会得到一个字符型的结果,在处理数据时通常需要把它作相应的转换
- 时间(Time)
- 简要描述:时间类型有POSIXct和POSIXlt
- 字符—>时间转换:
as.Date() #字符转日期
as.POSIXct() as.POSIXlt() strptime() #字符转时间
# 例如:
x1<-"Jan 1,2019 02:18"
strptime(x1,"%B %d,%Y %H:%M")
- 缺失值(NA/NaN)
- 简要描述:缺失值的处理在数据分析中是很常见的一种,在数据预处理之前必须要处理数据的缺失值
- R中的缺失值:NA/NaN :其中NaN属于NA,而NA不属于NaN :NaN一般只用于表示数字的缺失值
- NA有类型属性:整数NA和字符NA
- 检测缺失值的方法:is.na() / is.nan()
- 实例:
> x<-c(5,NA,6,NA,NA)
> y<-c(5,NaN,6,NaN,NaN)
>
> is.na(x)
[1] FALSE TRUE FALSE TRUE TRUE
> is.na(y)
[1] FALSE TRUE FALSE TRUE TRUE
> is.nan(x)
[1] FALSE FALSE FALSE FALSE FALSE
> is.nan(y)
[1] FALSE TRUE FALSE TRUE TRUE
#说明:is.na()表示的两个结果相同说明NaN属于NA
- 小结