spark数据倾斜处理
- 危害:
- 当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。
- 当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足使得任务失败,并进而引进整个应用失败。
表现:同一个stage的多个task执行时间不一致。
- 原因:
- 机器本身性能,导致速度不一致。
- 数据来源的问题:
- 从数据源直接读取。如读取HDFS,Kafka
- 读取上一个Stage的Shuffle数据
如何缓解/消除数据倾斜
-
kafka:取决于kafka topic中消息在partition是否分布均匀。随机partition没问题,其他没有分布均匀的情况需要另外处理。
-
hdfs: 使文件可切分或者保证各文件的数据量基本一致。
-
shuffle: 调整并行度分散同一个Task的不同Key。
Spark在做Shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的Key对应的数据被分配到了同一个Task上,造成该Task所处理的数据远大于其它Task,从而造成数据倾斜。
简单说,数据根据并行度做hashpartionter时,可能没分配均匀,此时可以通过调整并行度来改变。
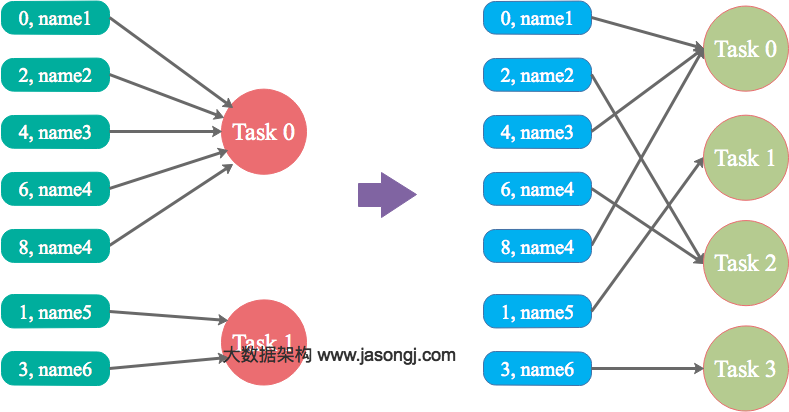
优势
实现简单,可在需要Shuffle的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
劣势
适用场景少,只能将分配到同一Task的不同Key分散开,但对于同一Key倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
自定义Partitioner
原理:
使用自定义的Partitioner(默认为HashPartitioner),将原本被分配到同一个Task的不同Key分配到不同Task。
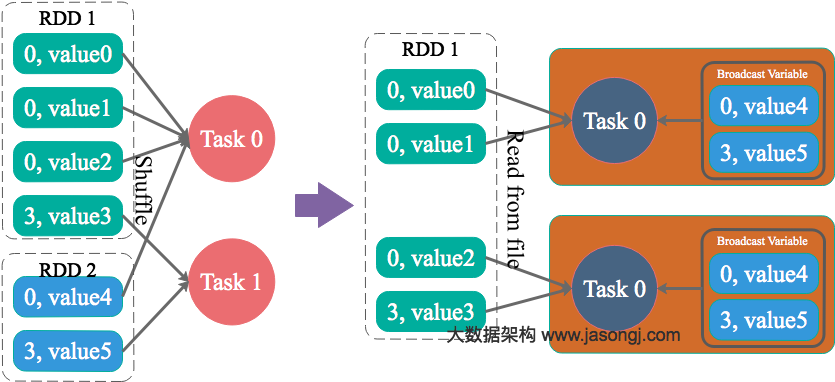
将Reduce side Join转变为Map side Join
原理:
通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle从而完全消除Shuffle带来的数据倾斜
为skew的key增加随机前/后缀
原理:
为数据量特别大的Key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的Task中,彻底解决数据倾斜问题。Join另一则的数据中,与倾斜Key对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。
大表随机添加N种随机前缀,小表扩大N倍
原理:
如果出现数据倾斜的Key比较多,上一种方法将这些大量的倾斜Key分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)
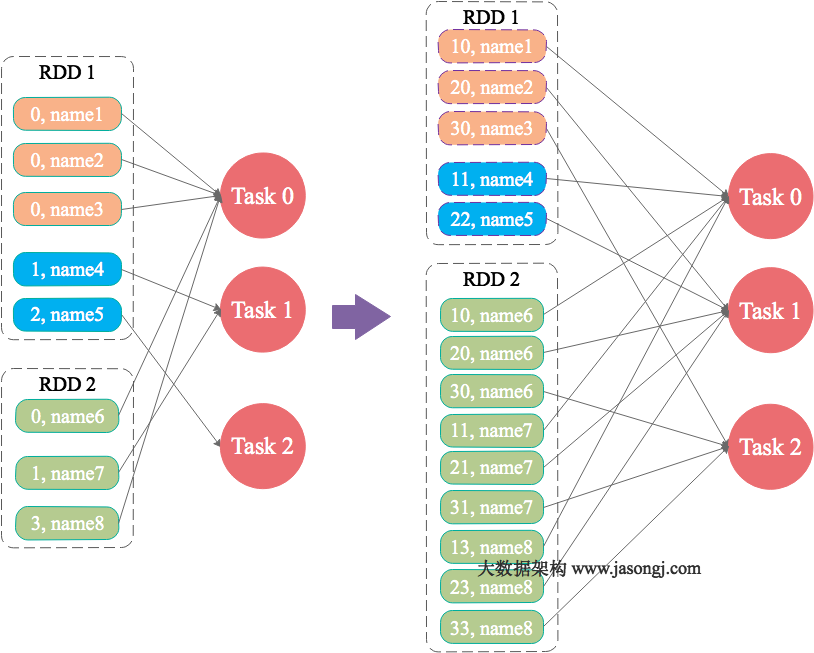
为什么小表要扩大?
因为两个表的数据本来是可以join上,现在加上大表加上随机前缀,小表也需要加上同样的前缀才能join上。
优势
对大部分场景都适用,效果不错。
劣势
需要将一个数据集整体扩大N倍,会增加资源消耗。
总结
避免spark数据倾斜的办法,就是在了解其执行机制的基础上,尽可能的分散key。针对不同的情况,采取不同的策略。