本文概要
本文主要从以下几点阐述RDD,了解RDD
- 什么是RDD?
- 两种RDD创建方式
- 向给spark传递函数Passing Functions to Spark
- 两种操作之转换Transformations
- 两种操作之行动Actions
- 惰性求值
- RDD持久化Persistence
- 理解闭包Understanding closures
- 共享变量Shared Variables
- 总结
Working with Key-Value Pairs、Shuffle operations、patitioning与并行度、DoubleRDDFunctions、RDD如何保障数据处理效率、RDD对容错的支持等知识点将做下一篇文章中阐述。

与许多专有的大数据处理平台不同,Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce,Streaming,SQL,Machine Learning以及Graph等。
要使用Spark,首先需要理解RDD。
1. 什么是RDD?
官网解释:
the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel.
RDD全称为Resilient Distributed Datasets,是一个容错的集合,它可以并行操作。
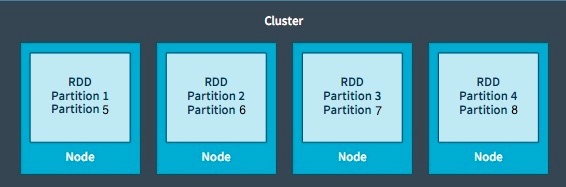
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。多个分区可以由多个任务并行计算。
RDD有容错机制,这点将做下篇文章中探讨。
2. 两种RDD创建方式
- Parallelized Collections集合并行化:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
- External Datasets从外部数据集创建:
- any storage source supported by Hadoop, including your local file system, HDFS, Cassandra, HBase, Amazon S3, etc. Spark supports text files, SequenceFiles, and any other Hadoop InputFormat.它支持text、SequenceFiles、任意的hadoop输入格式。
JavaRDD<String> distFile = sc.textFile("data.txt");
3. 向spark传递函数Passing Functions to Spark
Spark’s API relies heavily on passing functions in the driver program to run on the cluster. Spark’s API严重依赖传递给他的函数,驱动程序在集群上运行函数。
在java中需要实现接口 org.apache.spark.api.java.function,有如下两种方式:
- 实现接口:Implement the Function interfaces in your own class, either as an anonymous inner class or a named one, and pass an instance of it to Spark.
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
- lambda表达式:Use lambda expressions to concisely define an implementation.
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
4. 两种操作之转换Transformations
转换操作返回的结果是RDD. RDD-->RDD。
转换操作举例:
- map:
| 原始数据 | 函数 | 结果 |
|---|---|---|
| {1,2,3,4} | rdd.map(x => x+1) | {2,3,4,5} |
- filter
| 原始数据 | 函数 | 结果 |
|---|---|---|
| {1,2,3,4} | rdd.filter(x => x!=1) | {2,3,4} |
- flatmap: 1-->N
| 原始数据 | 函数 | 结果 |
|---|---|---|
| {1,2,3,4} | rdd.filter(x => x!=1) | {2,3,4} |
-
伪集合操作
- distinct(): 需要网络混洗数据shuffle
- intersection(): shuffle
- subtract(): shuffle
- union():
- cartesian: 笛卡尔积。应用于求用户相似度时。
-
注意:transformations只有在执行action时才会执行转换
5. 两种操作之行动Actions
Action: return a value to the driver program after running a computation on the dataset.在数据集计算完成后返回一个结果给驱动程序。
最常见的行动操作:reduce(func):通过函数func先聚集各分区的数据集,再聚集分区之间的数据,func接收两个参数,返回一个新值,新值再做为参数继续传递给函数func,直到最后一个元素
| 原始数据 | 函数 | 结果 |
|---|---|---|
| {1,2,3,4} | rdd.reduce((x, y) => x + y) | 10 |
6. 惰性求值
只有发生行动操作时,转换才会真正执行。
好处:This design enables Spark to run more efficiently. For example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset. spark运行性能更好。比如一个数据集结果map/reduce 处理后得到一个结果,而不是返回一个很大的map数据集。
- Spark可以把一些操作合并到一起来减少计算数据的步骤,比如可以对RDD进行多次转换。而在类似 Hadoop MapReduce 的系统中,开发者常常花费大量时间考虑如何把操作组合到一起,以减少MapReduce 的周期数。
- 写一些很复杂的映射,性能并不一定比简单操作好。所以可以写一些简单的连续的操作,这些操作更容易管理。
7. RDD持久化Persistence
RDD支持两种持久化方式:
- persist()
- cache(): Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it. cache是容错的,如果RDD的任一分区丢失了,它将自动重新计算。
在运行action时,RDD会被反复计算。为了避免多次计算同一RDD,可以对其持久化。
lineLengths.persist(StorageLevel.MEMORY_ONLY());
spark存储级别:

加上后缀‘_2’,持久化两份数据
存储级别的选择Which Storage Level to Choose?
- MEMORY_ONLY:the most CPU-efficient option。缺省的、最快的方式
- MEMORY_ONLY_SER : selecting a fast serialization library to make the objects much more space-efficient,but still reasonably fast to access. 通过快速序列化库节省空间,但是访问快递。
- Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. 不要溢出到磁盘,除非计算数据集的成本太高,或者需要过滤大量数据
- Use the replicated storage levels if you want fast fault recovery.
Removing Data
内存管理算法:least-recently-used (LRU) fashion
手动清内存:RDD.unpersist() method.
8. 理解闭包Understanding closures
One of the harder things about Spark is understanding the scope and life cycle of variables and methods when executing code across a cluster.
理解变量和方法的范围和生命周期
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
本地模式 Vs. 集群模式
预备知识:Spark应用程序的组成
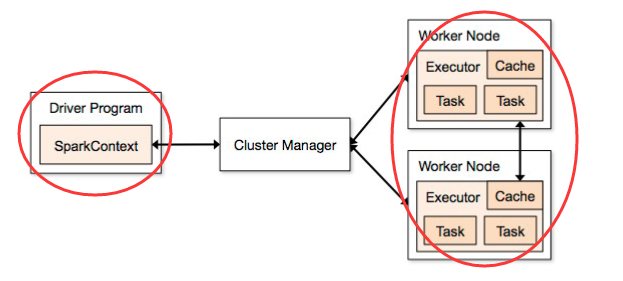
Driver: 驱动器,一个 job 只有一个,主要负责 job 的解析,与 task 的调度等。
Executor:执行器,实际运行 task 的地方,一个 job 有多个。
再回过头看上面代码的行为是有歧义的。
-
本地模式: 以本地模式运行在单个JVM上,运行程序的 JVM 和运行驱动器的 JVM 是同一个。所以操作就会引用到原始的 counter,对RDD中的值进行累加,并且将它存储到counter中。
-
集群模式: 以集群模式运行时,上面的代码的结果也许不会如我们预期的那样。当执行一个作业(job)时,Spark会将RDD 操作拆分成多个任务(task),多个task并行处理--每一个任务都会由一个executor来执行。
在执行之前,Spark会计算闭包(closure)。闭包是对executors可见的变量和方法,executors会用闭包来执行RDD上的计算(在这个例子中,闭包是foreach())。这个闭包是被序列化的,并且发送给每个executor。在本地模式中,只有一个executor,所以共享相同的闭包。然而,在集群模式中,就不是这样了。executors会运行在各自的worker节点中,每个executor都有闭包的一个副本。
发送给每个executor的闭包中的变量其实也是副本。每个foreach函数中引用的counter不再是driver节点上的counter。当然,在driver节点的内存中仍然存在这一个counter,但是这个counter对于executors来说是不可见的。executors只能看到自己的闭包中副本。这样,counter最后的值仍旧是0,因为所有在counter的操作只引用了序列化闭包中的值。
简单说,spark为了避免闭包引入的问题,仅处理闭包内的局部变量。
如何做到这一点?
- 将传入的变量和方法,拷贝到闭包中。
那么如何确保上面的行动Action正确执行,达到预期的效果?Shared Variables
9. 共享变量Shared Variables
两种使用模式:broadcast variables and accumulators.
广播变量Broadcast Variables
creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.什么时候创建广播变量?任务的多个步骤需要同一份数据 或者缓存数据的反序列化 很重要时。
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. 广播变量缓存在每台机器上。
The data broadcasted this way is cached in serialized form and deserialized before running each task.广播数据序列化后缓存在缓存中,在运行每个任务时进行反序列化操作。
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
广播变量只能被传播一次,传播之后不能修改。
Accumulators
一般用来做集算器counter或者求和sum.
For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will only be applied once, i.e. restarted tasks will not update the value.累加器只在action中执行,spark保证每个task只更新一次累加值,重新执行任务不会更新其值。
LongAccumulator accum = jsc.sc().longAccumulator();
sc.parallelize(Arrays.asList(1, 2, 3, 4)).foreach(x -> accum.add(x));
accum.value();
// returns 10
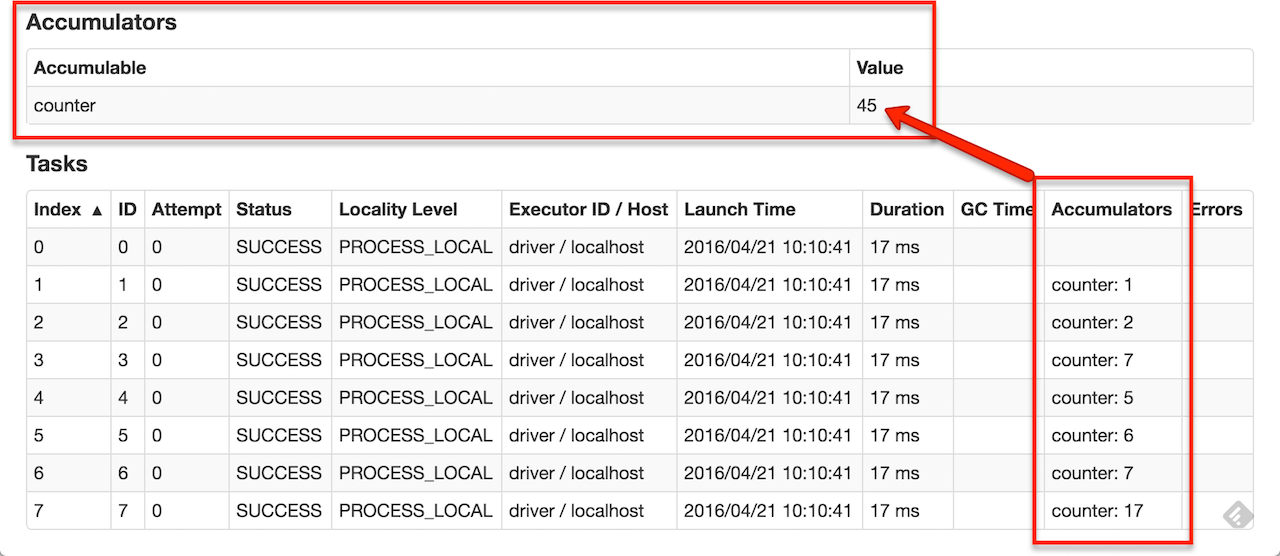
累加器执行过程:
10. 总结
RDD的操作只有三种:
- 创建RDD
- 转化RDD。transformation
- 调用RDD操作进行求值。action
RDD是惰性求值,只有执行Action时,转化操作才会执行。
如果多次使用转化操作中的数据,可以将数据缓存,避免多次重复计算。
spark的难点之一,就是理解闭包。因为数据是在task中并行处理,所以不能在task中处理普通的全局变量,只能使用共享变量Shared Variables。