网上大多爬虫仍旧是python2的urllib2写的,不过,坚持用python3(3.5以上版本可以使用异步I/O)
相信有不少人爬虫第一次爬的是Mm图,网上很多爬虫的视频教程也是爬mm图,看了某人的视频后,把这个爬虫给完成了
因为爬取的内容涉及个人隐私,所以,爬取的代码及网址不在此公布,不过介绍一下爬取的经验:
1.我们首先得了解我们要爬取的是什么,在哪爬取这些信息,不要着急想用什么工具,怎么搞,怎么搞得
2.手动操作一遍爬虫要完成的任务,我这个就是爬图片的,可以自己操作一遍
3.打开抓包软件或者Google的F12调试工具,查看数据,了解请求过程中的信息,如网址,发送请求的数据
大概了解以上信息后,可以开始编写爬虫了(个人经验,大牛勿喷,,,)
介绍python3用于爬虫的模块及方法:
可以查看官方的API文档,看懂文档,下面的就不用看了
urllib包:在python2中urllib和urllib2是分开的,python3合并在了一起,强调,这是个包,所以很多函数不一样了,但是还是那个味道
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsingrobots.txtfiles
这四个模块中urllib.request是常用的,urllib.parse中urlencode()也是会用到的
在urllib.request中,常用的方法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
headers参数,如果不想很容易被服务器发现,那么最起码加个user-agent吧,当然,你可以设置代理ip
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
将请求发送的data字典转化为str,经过编码,data成了(get请求不用)
在爬取的过程中,正则表达式一定会用到,推荐一款软件:MTracer,可以自己尝试写正则: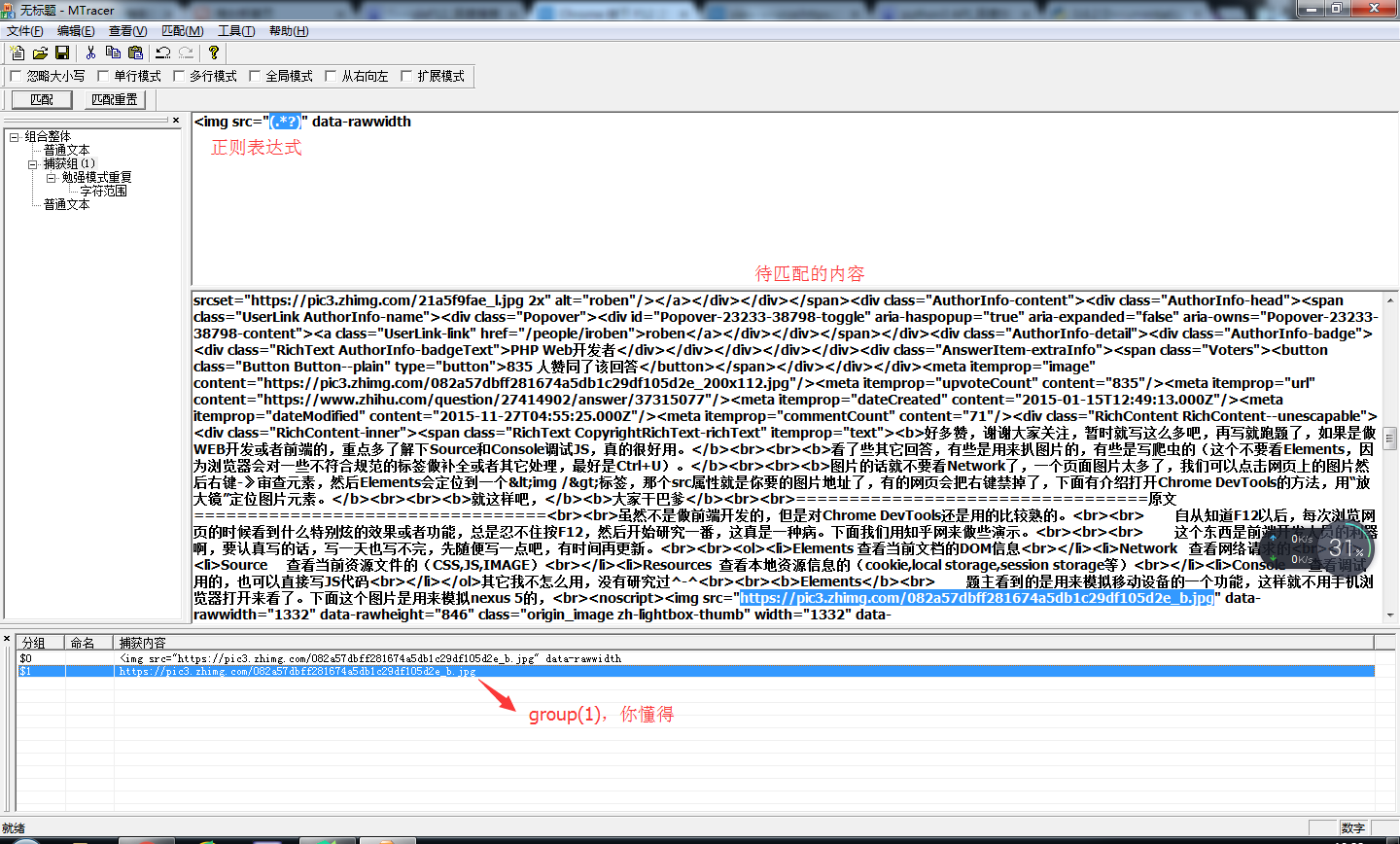
还是很不错的,谁爬谁知道