作者:Luyang Wang, Kai Huang, Jiao Wang, Shengsheng Huang, Jason Dai
基于深度学习的推荐模型已广泛应用于各种电商平台中,为用户提供推荐。目前常用的方法通常会将用户和商品embedding 向量连接起来输入多层感知器(multilayer perceptron)以生成最终的预测。但是,这些方法无法捕获实时用户行为信号,并且没有考虑到重要的情景特征(例如时间和位置等)的影响,以致最终的推荐不能准确地反映用户的实时偏好,这个问题在快餐推荐的应用场景中更为重要,因为:
- 如果当用户的购物车中已经添加了饮料时,用户不太可能再购买其他饮料。
- 用户的购买偏好会在给定的地点、时间和当前的天气条件下发生很大变化。例如,人们几乎从不在半夜给孩子们买食物,也不太可能在寒冷的雨天购买冰镇饮料。
在此文章中,我们介绍了Transformer Cross Transformer(TxT)模型,该模型可以利用到实时用户点餐行为以及情景特征来推断用户的当前偏好。该模型的主要优点是,我们应用了多个Transformer编码器来提取用户点单行为和复杂的情景特征,并通过点积的方法将Transformer输出组合在一起以生成推荐。
此外,我们利用Analytics Zoo提供的RayOnSpark功能,使用Ray*, Apache Spark* 和Apache MXNet* 构建了一个完整的端到端的推荐系统。它将数据处理(使用Spark)和分布式训练(使用MXNet和Ray)集成到一个统一的数据分析和AI流水线中,并直接运行在存储数据的同一个大数据集群上。我们已经在Burger King成功部署了这套推荐系统,并且已经在生产环境中取得了卓越的成果。
TxT推荐模型
我们提出了Transformer Cross Transformer(TxT)模型,该模型使用Sequence Transformer对客户订单行为进行编码,使用Context Transformer对情景特征(例如天气,时间和位置等)进行编码,然后使用点积的方式将它们组合(“cross”部分)以产生最终输出,如图1所示。我们利用MXNet API实现了我们的模型代码。
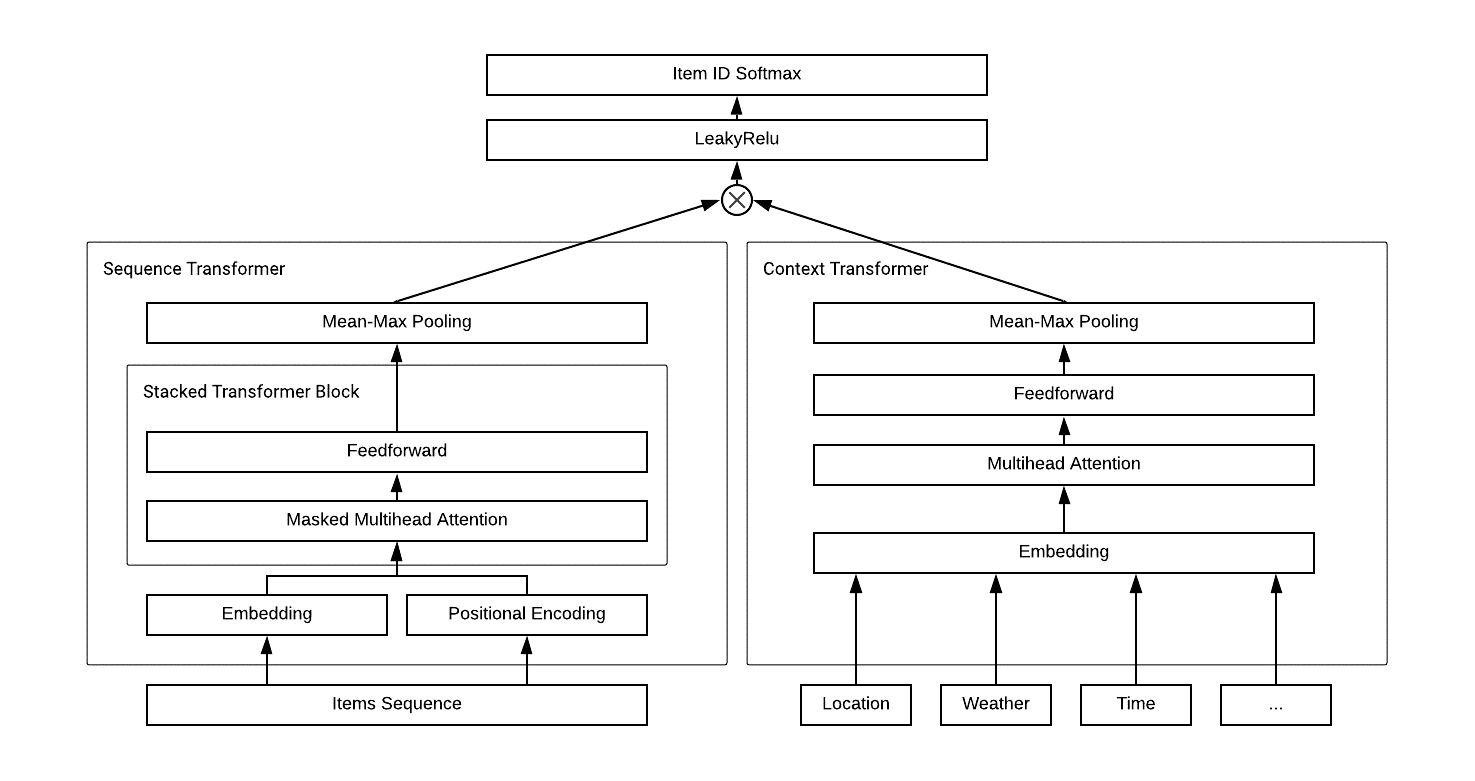
图1: TxT模型结构
Sequence Transformer
我们基于Transformer架构创建了一个Sequence Transformer,用于学习客户购物车中包含每件产品加入顺序信息的embedding 向量,如图1的左下部分所示。为了确保商品位置信息可以在其原始的购物行为中得到考虑,除了商品特征embedding之外,我们还对商品进行基于位置的embedding。两个embedding的输出加在一起,输入到一个multi-head self-attention神经网络中。
为了从每个商品的隐藏向量中提取客户整个购物车信息的向量表示,我们将mean-pooling和max-pooling分别与最终Sequence Transformer的输出连接起来。通过这种方式,pooling层的输出既考虑到了在购物车中包含的所有产品,同时又专注提取了少数关键产品的显著特征。
Sequence Transformer可以使用Analytics Zoo中的API直接构建,如下:
from zoo.models.recommendation import SequenceTransformer sequence_transformer = SequenceTransformer( num_items=num_items, item_embed=200, item_hidden_size=200, item_max_length=10, item_num_heads=4, item_num_layers=2, item_transformer_dropout=0.1, item_pooling_dropout=0.1, cross_size=100) item_outs = sequence_transformer(input_items, padding_mask)
Context Transformer
合并情景特征的一种常见方法是将它们与带时间序列的输入特征直接连接起来。但是简单地将非时间序列的特征与时间序列的特征连接起来的意义不大。以前的一些解决方案使用相加来处理多个情景特征,然而简单的相加只能综合多个情景特征对输出做出的贡献,但大多数情况下,这些情景特征对用户最终决策的贡献并不相等。
因此,我们使用Context Transformer对情景特征进行编码,如图1右下方所示。使用Transformer的multi-head self-attention,我们不仅可以捕获每一个情景特征的影响,还可以捕获不同情景特征之间的内部关系和复杂的交互作用。
Context Transformer可以使用Analytics Zoo中的API直接构建,如下:
context_transformer = ContextTransformer( context_dims=context_dims, context_embed=100, context_hidden_size=200, context_num_heads=2, context_transformer_dropout=0.1, context_pooling_dropout=0.1, cross_size=100) context_outs = context_transformer(input_context_features)
Transformer Cross Transformer
为了联合训练Sequence Transformer和Context Transformer,我们在这两个transformer输出之间做点积进行联合训练,同时优化商品的embedding,情景特征的embedding及其交互的所有参数。最后我们使用LeakyRelu作为激活函数,使用softmax层来预测每个候选商品的概率。
TxT由Sequence Transformer和Context Transformer组成,可以使用Analytics Zoo中的API直接构建,如下:
from zoo.models.recommendation import TxT net = TxT(num_items, context_dims, item_embed=100, context_embed=100, item_hidden_size=256, item_max_length=8, item_num_heads=4, item_num_layers=2, item_transformer_dropout=0.0, item_pooling_dropout=0.1, context_hidden_size=256, context_max_length=4, context_num_heads=2, context_num_layers=1, context_transformer_dropout=0.0, context_pooling_dropout=0.0, activation="leakyRelu", cross_size=100) net.hybridize(static_alloc=True, static_shape=True) output = net(sequence, valid_length, context)
端到端的系统架构
通常情况下,构建一个完整的推荐系统会建立两个单独的集群,一个集群用于大数据处理,另一个集群用于深度学习(例如,使用GPU集群)。但这不仅会带来跨集群数据传输的巨大开销,而且还需要在生产环境中去管理独立的系统和工作流。为了应对这些挑战,我们在Analytics Zoo的RayOnSpark之上构建了我们的推荐系统,将Spark数据处理和使用Ray的分布式MXNet训练集成到一个统一的流水线中,直接运行在数据存储的集群上。
图2展示了我们系统的总体架构。Spark的程序中,在Driver节点上会创建一个SparkContext对象去负责启动多个Spark Executor来运行Spark任务。 RayOnSpark会在Spark Driver上另外创建一个RayContext对象,去自动把Ray进程和Spark Executor一起启动,并在每个Spark Executor里创建一个RayManager来管理Ray进程(例如,在Ray程序退出时自动关闭进程)。
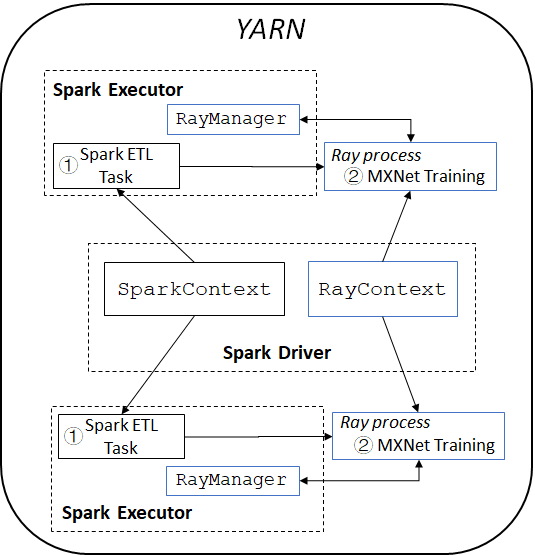
图 2: 基于RayOnSpark的推荐系统流水线架构
在我们的推荐系统中,我们首先启动Spark任务去读取存储在分布式文件系统上的餐厅交易数据,然后使用Spark对这些数据进行数据清理,ETL和预处理。 Spark任务完成后,我们将处理后在内存中的Spark RDD通过Plasma直接输入给Ray进行分布式训练。
参考RaySGD的设计,我们实现了MXNet Estimator,它提供了一个轻量级的wrapper,可以在Ray上自动地部署分布式MXNet训练。 MXNet worker和parameter server都是用Ray actor实现和运行的,它们之间通过MXNet提供的分布式key-value store来相互通信,每个MXNet worker从Plasma中拿取本地节点上的部分数据来训练模型。通过这种方式,用户就可以使用下面简单的scikit-learn风格的API,通过Ray无缝地将MXNet的模型训练代码从单个节点扩展到生产集群:
from zoo.orca.learn.mxnet import Estimator mxnet_estimator = Estimator(train_config, model, loss, metrics, num_workers, num_servers) mxnet_estimator.fit(train_rdd, validation_rdd, epochs, batch_size)
这种统一的设计架构将基于Spark的数据处理和基于Ray的分布式MXNet训练集成到一个端到端的、基于内存的流水线中,能够在存储大数据的同一集群上直接运行。因此,构建整个推荐系统的流水线我们只需要维护一个集群,避免了不同集群之间额外的数据传输,也不需要额外的集群维护成本。这样充分地利用了现有的集群资源,并且显著地提升了整个系统的端到端性能。
模型评估
我们使用了过去12个月中汉堡王客户的交易记录进行了离线的实验,其中前11个月的历史数据用于训练,最后一个月的数据用于验证。我们用这些数据对模型进行训练,让模型能够预测客户下一个最有可能购买的产品。从图表1中,我们可以看到我们的TxT优于其他用于推荐的基准模型(包括Association Rule Learning和GRU4Rec)。相比GRU4Rec,我们可以看到,TxT能利用各种情景特征大大提高了预测的准确性(Top1和Top3准确率分别提升了约5.65%和7.32%)。
|
|
选用的模型 |
Top1准确率 |
Top3准确率 |
|
1 |
Association Rule Learning |
20.14% |
35.04% |
|
2 |
GRU4Rec |
30.65% |
45.72% |
|
3 |
Transformer Cross Transformer (TxT) |
35.03% |
53.04% |
图表 1: 不同推荐模型的离线训练结果
为了评估我们的模型在实际生产环境中的有效性,我们在Burger King的手机客户端上同时对比了TxT模型和Google Recommendation AI*提供的推荐模型。我们从推荐转化率和附加销售额的提升这两个方面评估了不同模型的在线效果,在生产环境做了4周的A/B测试。我们随机选择了20%的用户作为对照组,为他们提供之前在生产环境使用的基于规则(Rule Based)的推荐系统。如图表2,与对照组相比,TxT将下单页面上的推荐转化率提高了264%,附加销售额提高了137%。与运行Google Recommendation AI的测试组相比,TxT进一步提高了100%的转换收益和73%的附加销售收益。
|
推荐系统 |
转化率提升 |
附加销售额提升 |
|
Rule Based Recommendation (Control) |
0% |
0% |
|
Google Recommendation AI |
+164% |
+64% |
|
Transformer Cross Transformer (TxT) |
+264% |
+137% |
图表2: 不同推荐解决方案的在线结果
结论
这篇文章描述了我们如何在Burger King的生产环境中构建一个端到端的推荐系统。我们通过Transformer Cross Transformer(TxT)模型成功地捕获了用户订单行为和复杂的情景特征为用户做合适的推荐,并且使用RayOnSpark实现了统一的数据处理(使用Spark)和深度学习模型训练(使用Ray)的流水线。TxT模型和RayOnSpark均已在Analytics Zoo项目中开源。
*其他名称和品牌可能是其他所有者的财产